I Stopped My Data From Being Used to Train AI (You Might Want to Too)
•March 11, 2026
0
Why It Matters
User‑controlled data exclusion limits inadvertent intellectual‑property exposure and reduces privacy risks, pressuring AI firms to adopt clearer consent practices.
Key Takeaways
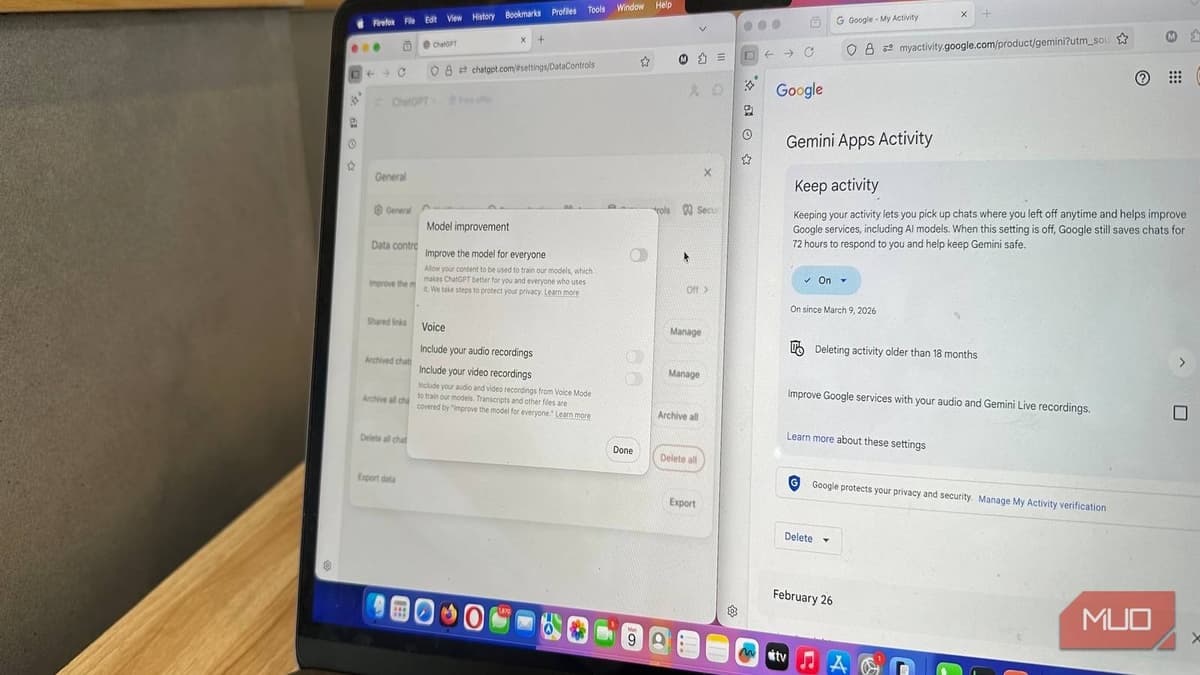
- •ChatGPT settings stop future model training usage
- •Claude opt‑out also removes past data from training
- •Adobe Stock uploads feed AI; Cloud files generally safe
- •LinkedIn can disable generative‑AI data use
- •Meta lacks any opt‑out for model training
Pulse Analysis
As generative AI becomes embedded in everyday tools, the line between personal interaction and data harvesting blurs. While large language models improve through massive datasets, the default practice of automatically ingesting user content raises legal and ethical questions. Opt‑out mechanisms—like those in ChatGPT, Claude, and LinkedIn—offer a modest safeguard, but they often apply only to future interactions and can be overridden by feedback actions, leaving users vulnerable to unintended exposure of proprietary or creative work.
Regulators worldwide are beginning to scrutinize AI training data practices, with the EU’s AI Act and emerging U.S. state privacy bills demanding clearer consent frameworks. Companies that proactively provide granular controls not only mitigate compliance risk but also build trust with a privacy‑aware audience. Conversely, platforms such as Meta that lack any opt‑out option may face pressure from both legislators and consumers, potentially prompting legislative mandates for mandatory data exclusion or transparent reporting of training data sources.
For businesses, the practical takeaway is to audit all SaaS tools that incorporate AI features and verify their data‑usage policies. Enabling opt‑outs where available, limiting uploads of sensitive assets to public repositories, and employing internal governance for AI‑generated content can reduce exposure. As the market matures, expect a shift toward default opt‑out models and standardized privacy labels, making it easier for enterprises and individuals to protect their intellectual property while still leveraging AI capabilities.
I stopped my data from being used to train AI (you might want to too)
0
Comments
Want to join the conversation?
Loading comments...