
AI Breakthroughs Coming in 2026: World Models, Spatial Intelligence & Multimodality
AI Breakthroughs Coming in 2026: World Models, Spatial Intelligence & Multimodality
Happy new year everyone!
The narrative has been shifting. Every major AI lab—Google, Meta, Luma, Runway—is no longer racing to build a better video generator. They’re racing to build a world engine.
In my new video, I break down the technical shifts that got us here: from multimodal training that unlocked native audio-video generation, to autoregressive architectures that finally solved consistent editing, to real-time models that predict the next frame on demand. And of course, my predictions on where we’re going next.
Watch the full episode on YouTube:
YouTube Chapter Links:
-
00:00 - Intro
-
00:33 - Video Models in 2025
-
01:15 - Video With Audio Generation
-
01:54 - Emergence of World Models
-
03:50 - Multimodality
-
05:29 - Solving Inconsistency
-
07:01 - Image Models in 2025
-
07:47 - Diffusion vs Autoregressive Models
-
09:20 - Benefits of Multimodality with Image Generation
-
11:34 - Real-World Simulation Using Video Generation
-
16:02 - Real-Time Interaction in World Models
-
19:19 - 3D Native World Models
-
22:49 - What’s Coming in 2026
-
25:34 - The Effect on Content Creation Workflows
-
29:03 - What We Won’t See In 2026
-
30:12 - Conclusion
The Slot Machine Is Dead
Remember re-rolling generations endlessly hoping for something usable? Autoregressive image models like Nano Banana changed that. By predicting tokens sequentially—with a thinking step to plan composition before generating—these models reason about their own output before you ever see it. The model does the slot-machining for you now.
From Synthetic Camera to World Engine
Video diffusion models treat a clip as one 3D block—height, width, time—and denoise it all at once. Great for consistency within a generation, terrible for real-time interaction. Autoregressive models like Genie 3 flip the paradigm: predict the next frame, accept user input, repeat to infinity. Suddenly you’re not just generating video—you’re directing a world that responds.
[
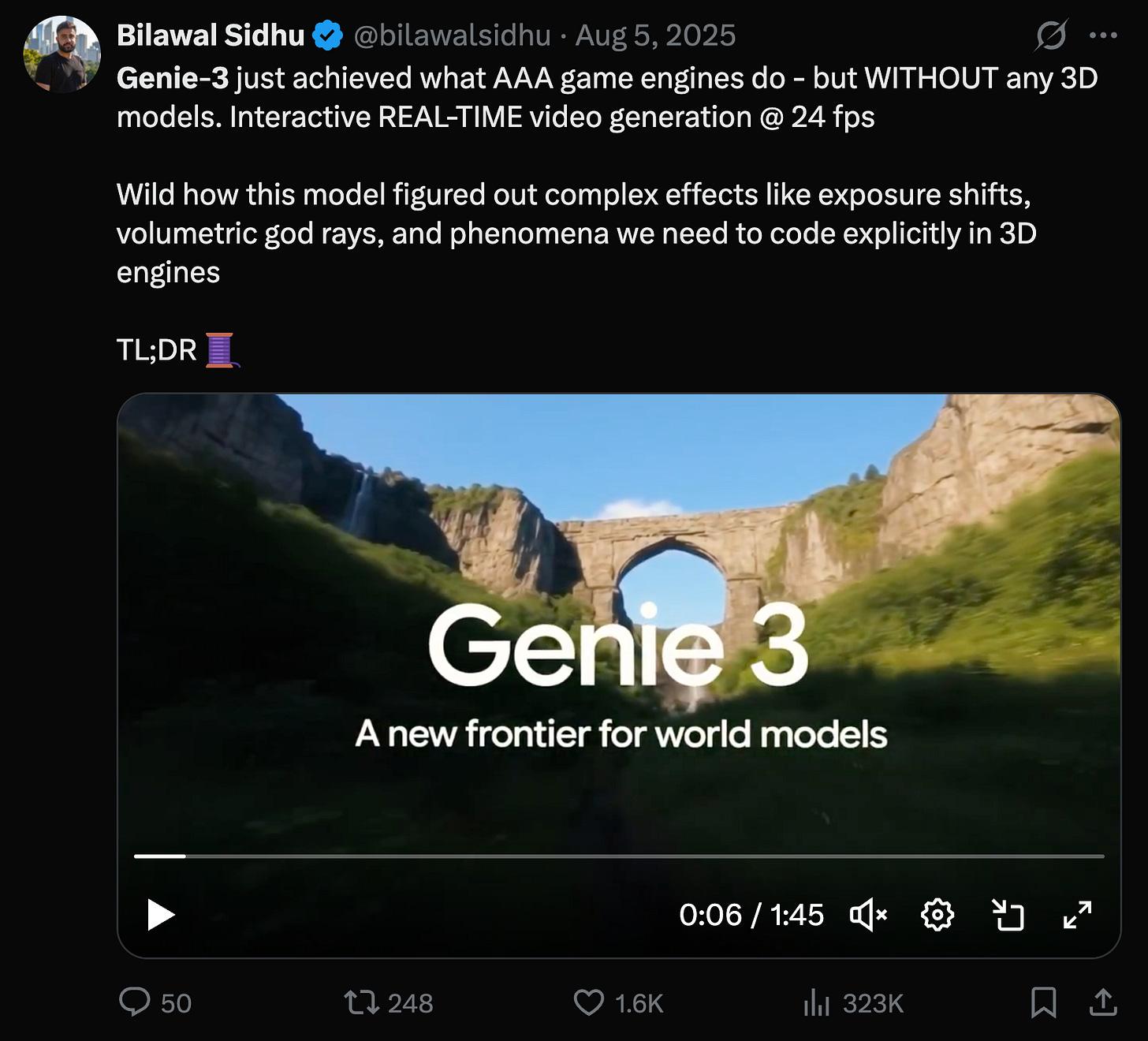
](https://x.com/bilawalsidhu/status/1952742891295764620)
The Hybrid Future
The 2026 workflow is taking shape: use World Labs or SpAItial to build your environments in 3D, then prompt next-gen video models with image references, audio clips of your characters, and let the autoregressive architecture retain likeness across generations. Virtual production meets generative media. Startups like Artcraft and Intangible AI have the right idea.
[
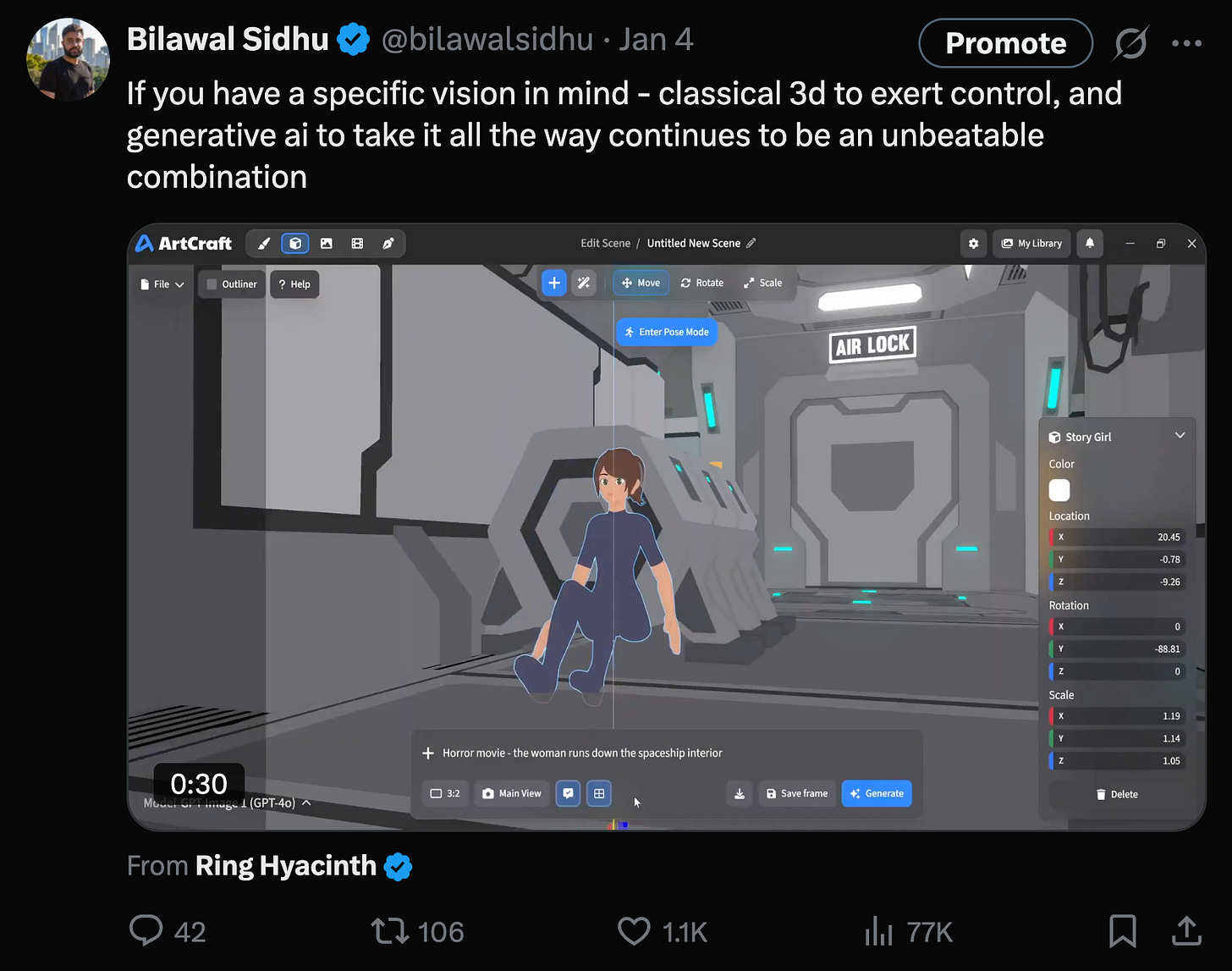
](https://x.com/bilawalsidhu/status/2007890372748558489)
On The Horizon 🔭
The missing piece: embodied agents within these world models. Imagine directing AI characters on a sound stage who reason about their environment and deliver performances in real-time. We’re not there yet—but that’s where this is heading. And it’s an area where robotics and entertainment share more in common than you might imagine.
Check out recent discussion on X:
-
Every video is now a spatio-temporal portal you can revisit from any angle
-
Casey Neistat is posting about Gaussian splatting. Reality capture has officially gone mainstream.
-
Classical 3D for control, generative AI to finish—the hybrid workflow is unbeatable
If this gave you something to think about, share it with fellow reality mappers. The future’s too interesting to navigate alone.
Cheers,
Bilawal Sidhu
https://bilawal.ai
Comments
Want to join the conversation?
Loading comments...