DeepSWE AI Coding Model Benchmark Finally Solves AI Training Data Contamination
Key Takeaways
- •DeepSWE uses 91 contamination‑free tasks from open‑source repos
- •Benchmark covers TypeScript, Go, Python, JavaScript, Rust
- •Verification error rates: 0.3% false positives, 1.1% false negatives
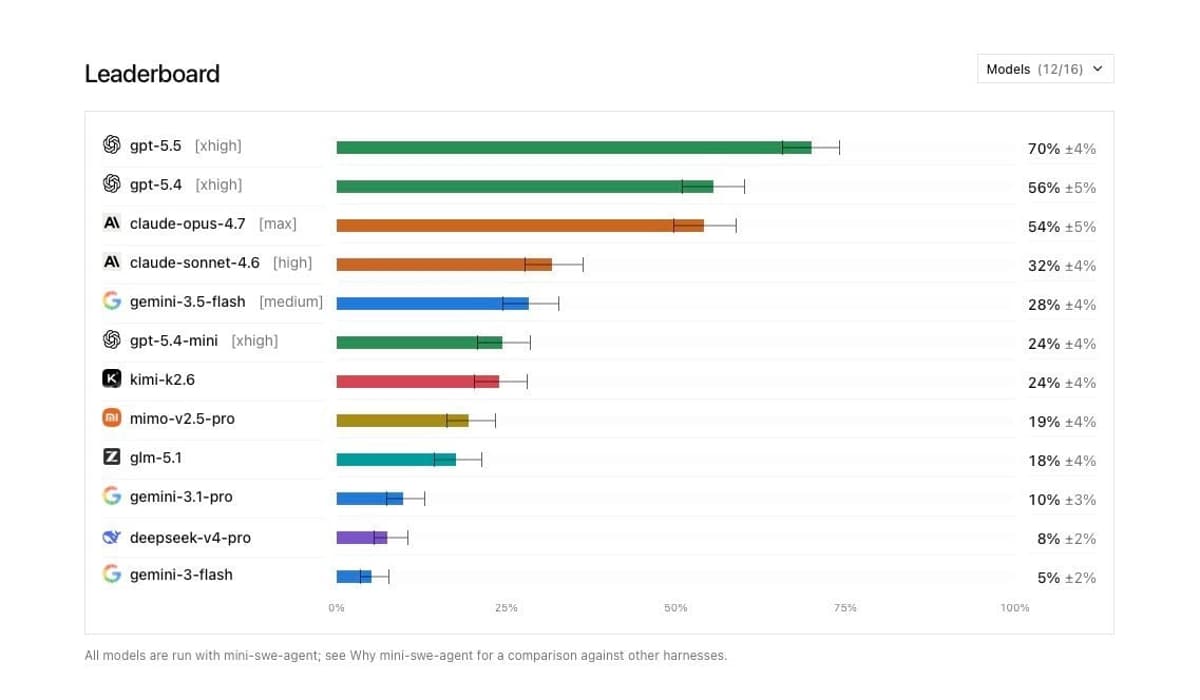
- •GPT‑5.5 leads with 70% accuracy, low cost and speed
- •Opus 4.7 costs three times more and runs slower than GPT‑5.5
Pulse Analysis
The rapid rise of AI‑powered coding assistants has outpaced the tools used to evaluate them. Traditional benchmarks often rely on publicly available code snippets that models may have seen during training, inflating performance metrics and obscuring real‑world usefulness. DeepSWE addresses this gap by curating entirely original tasks, ensuring a clean testing environment that reflects genuine developer challenges. This contamination‑free approach restores confidence in comparative results, allowing enterprises to make data‑driven choices about which models to integrate into their development pipelines.
DeepSWE’s methodology emphasizes breadth and depth. By pulling problems from 91 active repositories across five major languages, the benchmark captures a spectrum of programming paradigms—from front‑end JavaScript frameworks to low‑level Rust systems. The tasks demand higher token counts and concise prompts, pushing models to demonstrate not just syntactic correctness but functional problem‑solving. A robust verification layer, with error rates under 1.5%, rewards diverse correct implementations, delivering granular insights into model behavior that go beyond simple pass/fail scores.
The early results are already reshaping market expectations. GPT‑5.5’s 70% accuracy, combined with a modest $5.80 per trial cost and a 20‑minute average runtime, sets a new efficiency benchmark, making it attractive for cost‑conscious enterprises. In contrast, Opus 4.7’s higher expense and slower execution highlight trade‑offs that organizations must weigh. As AI coding tools become integral to software delivery, DeepSWE’s focus on practical, contamination‑free evaluation will likely become a standard reference, guiding both product development and procurement strategies in the years ahead.
DeepSWE AI Coding Model Benchmark Finally Solves AI Training Data Contamination
Comments
Want to join the conversation?