From Messy to Clean: 8 Python Tricks for Effortless Data Preprocessing
•February 18, 2026
0
Why It Matters
Efficient preprocessing cuts development time and improves data quality, directly boosting model performance and business decision speed. Adopting these patterns helps data teams scale pipelines without fragile custom code.
Key Takeaways
- •Normalize column names with one-liner.
- •Strip whitespace across object columns efficiently.
- •Convert strings to numeric safely, coercing errors.
- •Parse dates with errors='coerce' to avoid crashes.
- •Impute missing values using median and mode.
Pulse Analysis
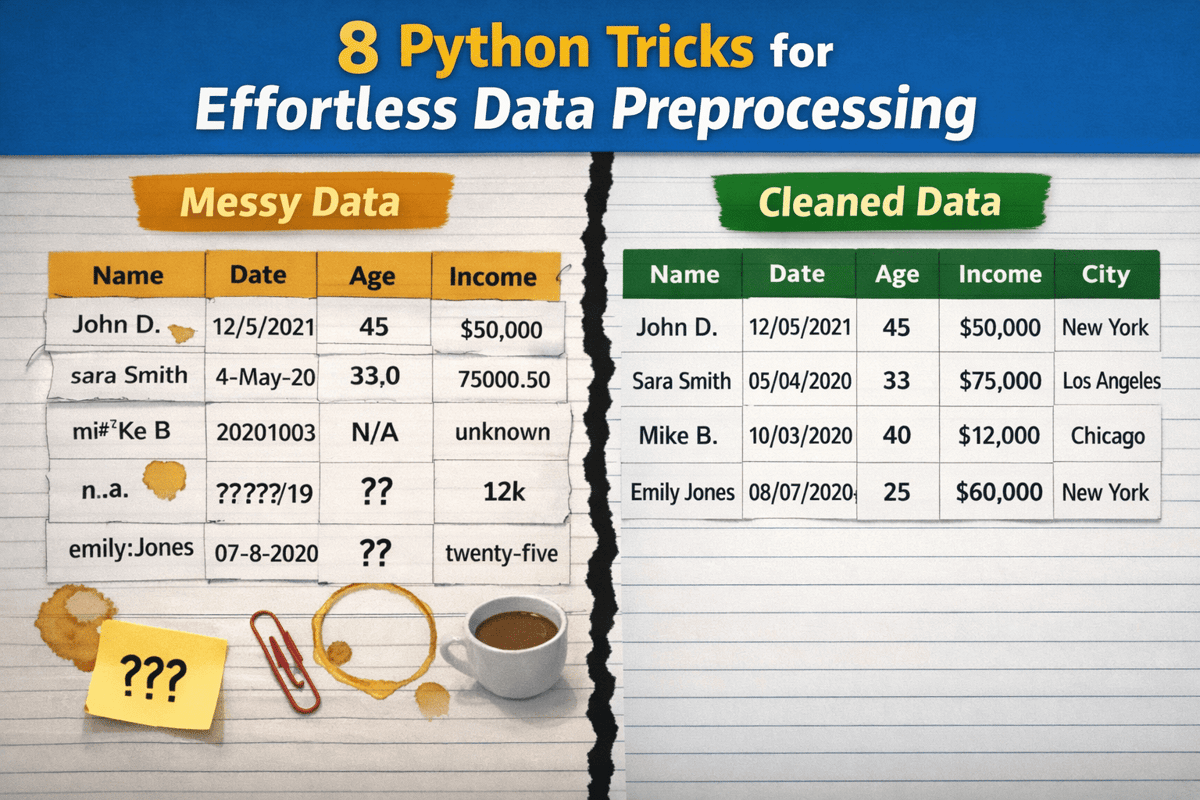
Data scientists often spend a disproportionate amount of time wrangling raw inputs before any analysis can begin. In the Python ecosystem, pandas provides a rich toolbox, yet many practitioners write verbose, ad‑hoc scripts that are hard to maintain. By applying systematic one‑liners—such as stripping column whitespace, lower‑casing identifiers, and replacing spaces with underscores—teams instantly create a consistent schema that downstream processes can rely on, eliminating a common source of bugs.
Beyond naming conventions, the article’s tricks address type safety and missing‑value handling, two pillars of robust pipelines. Converting strings to numeric with pd.to_numeric(errors='coerce') and parsing dates with pd.to_datetime(errors='coerce') prevent runtime exceptions, automatically flagging problematic entries as NaN or NaT. Strategic imputation—using median for continuous fields and mode for categorical ones—preserves statistical integrity while keeping datasets complete. Standardizing categories through mapping functions further reduces cardinality, simplifying feature engineering and model interpretability.
When these practices are embedded into a reusable preprocessing module, organizations gain scalability and reproducibility across projects. Quantile‑based clipping of extreme values curtails outlier influence without discarding data, a technique especially valuable in finance and e‑commerce analytics where tail behavior matters. As machine‑learning pipelines evolve toward automated MLOps, such concise, pandas‑native patterns become essential building blocks, ensuring that data quality keeps pace with rapid model deployment cycles.
From Messy to Clean: 8 Python Tricks for Effortless Data Preprocessing
0
Comments
Want to join the conversation?
Loading comments...