AgentClinic Puts Medical AI Through a More Realistic Diagnostic Test
Why It Matters
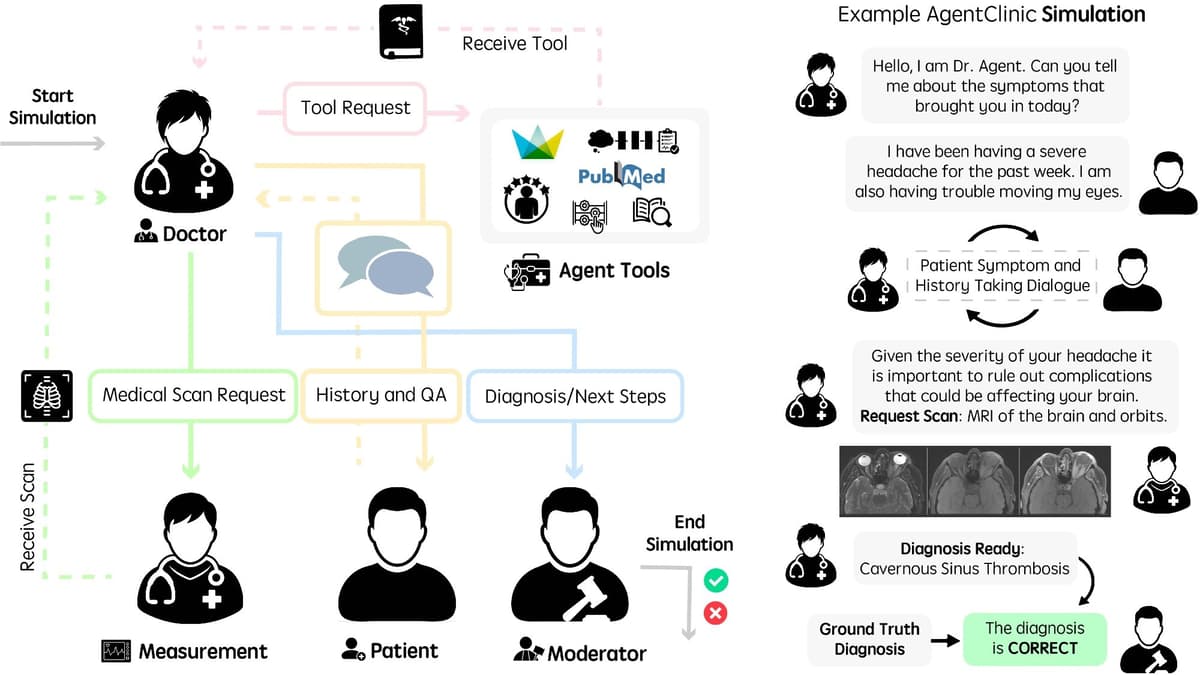
AgentClinic shows that passing medical exams is insufficient; interactive, tool‑enabled evaluation is essential before AI can be trusted in clinical settings. This shifts how developers and regulators will assess AI readiness for patient care.
Key Takeaways
- •Claude 3.5 Sonnet achieved 62.1% accuracy, highest among LLMs
- •Reducing interactions to 10 dropped accuracy to 25%, showing interaction limits
- •Notebook tool raised Claude’s mean accuracy to 51.3%
- •Bias prompts reduced GPT‑4 accuracy by ~2–3 percentage points
- •Multilingual performance varied; Claude remained strongest across seven languages
Pulse Analysis
The rise of large language models (LLMs) has sparked excitement in healthcare, yet most evaluations still rely on static multiple‑choice exams. AgentClinic disrupts that paradigm by creating a sandbox where a "doctor" agent must converse with simulated patients, request measurements, and even request image analyses. This sequential, multimodal setup mirrors real clinical workflows, forcing models to manage uncertainty, allocate limited interactions, and integrate external tools—capabilities that traditional question‑answer benchmarks overlook. By grounding cases in MedQA, NEJM challenges, and de‑identified MIMIC‑IV records, the benchmark offers a more realistic stress test for AI diagnostics.
Results from the study reveal a nuanced performance landscape. Claude 3.5 Sonnet outperformed GPT‑4 and other contenders, achieving 62.1% accuracy on MedQA scenarios and maintaining the strongest multilingual scores across seven languages. However, even top models faltered when interaction windows were narrowed to ten turns, with accuracy plunging to 25%, underscoring the importance of dialogue depth. Tool augmentation proved a double‑edged sword: the Notebook tool lifted Claude’s mean accuracy to 51.3%, while other tools offered modest gains or even setbacks for certain models. Bias‑laden prompts shaved roughly 2‑3 points off GPT‑4’s scores, highlighting how subtle prompt framing can sway diagnostic outcomes.
For investors, developers, and regulators, AgentClinic signals a pivotal shift in AI validation. It demonstrates that excelling on static exams does not guarantee competence in the messy, iterative reality of patient care. While the benchmark remains a simulation—relying on LLM‑generated patients and measurements—it provides a scalable, reproducible framework to benchmark sequential reasoning, tool use, and bias resilience. Future iterations that incorporate real clinician feedback and live patient data will be critical to bridge the gap between laboratory performance and safe, autonomous clinical deployment. Until then, stakeholders should treat high benchmark scores as promising signals, not definitive proof of readiness for bedside decision‑making.
AgentClinic puts medical AI through a more realistic diagnostic test
Comments
Want to join the conversation?
Loading comments...