Even the Best AI Models Fail at Visual Tasks Toddlers Handle Easily
•January 18, 2026
0
Companies Mentioned
Why It Matters
The findings expose a critical limitation in current AI that hampers applications requiring precise visual reasoning, signaling a need for fundamentally new multimodal architectures. Industries relying on visual inspection, robotics, and autonomous navigation may face delayed deployment until these gaps are closed.
Key Takeaways
- •Multimodal models underperform toddlers on visual tasks
- •Gemini‑3‑Pro‑Preview tops benchmark at 49.7% accuracy
- •Verbalization bottleneck limits fine‑grained visual reasoning
- •Open‑source models score below 25% on BabyVision
- •Drawing‑based solutions remain unsolved by current AI
Pulse Analysis
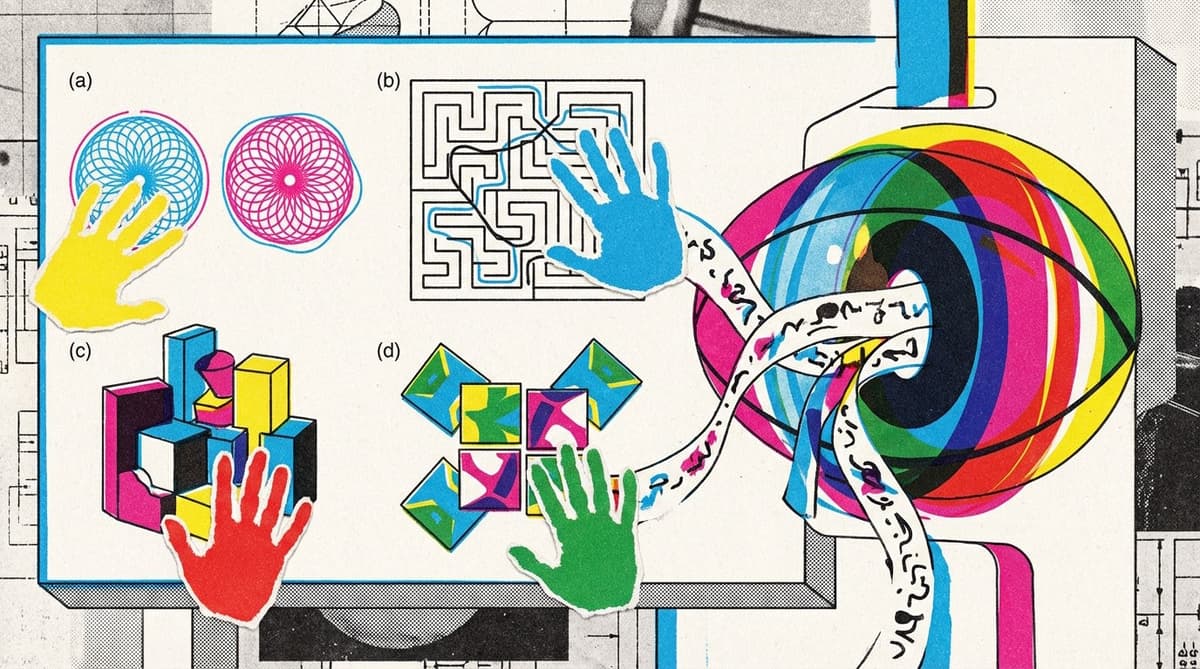
The BabyVision benchmark, introduced by researchers from UniPat AI and partners, shines a light on a blind spot that has long been overlooked in the rush to build ever‑larger multimodal language models. While models such as Gemini‑3‑Pro‑Preview and GPT‑5.2 excel at language‑driven tasks and score above 90% on knowledge exams, they falter dramatically when asked to discriminate subtle geometric differences, trace lines through mazes, or count hidden 3‑D blocks. This discrepancy underscores that current architectures treat vision as a pre‑processing step, converting images into textual tokens before any reasoning occurs, a process the authors label the "verbalization bottleneck."
The performance gap is not merely academic; it has tangible repercussions for sectors that depend on reliable visual cognition. Manufacturing quality control, autonomous vehicle navigation, and medical imaging all require precise spatial understanding that cannot be reduced to simple captions. As the benchmark shows, even the best‑performing models lag behind three‑year‑old children, suggesting that deploying these systems in safety‑critical environments could be premature. Moreover, the stark contrast between proprietary and open‑source offerings—most scoring below 25%—highlights a systemic challenge rather than an isolated model flaw.
Looking ahead, researchers advocate for unified multimodal models that maintain visual representations throughout the reasoning pipeline, bypassing the language bottleneck entirely. Early experiments with image‑generation extensions like BabyVision‑Gen hint at the promise of drawing‑based solutions, yet current generators still stumble on tasks demanding continuous spatial coherence, such as mazes. The release of BabyVision on GitHub provides the community with a diagnostic tool to track progress toward true visual intelligence, encouraging a shift from language‑first designs to architectures that can natively process and reason about visual data.
Even the best AI models fail at visual tasks toddlers handle easily
0
Comments
Want to join the conversation?
Loading comments...