How to Build a Self-Organizing Agent Memory System for Long-Term AI Reasoning
•February 14, 2026
0
Companies Mentioned
Why It Matters
By giving agents durable, queryable memory, enterprises can build assistants that retain context across sessions, reducing hallucinations and improving productivity. This modular design also lowers engineering overhead for long‑term AI deployments.
Key Takeaways
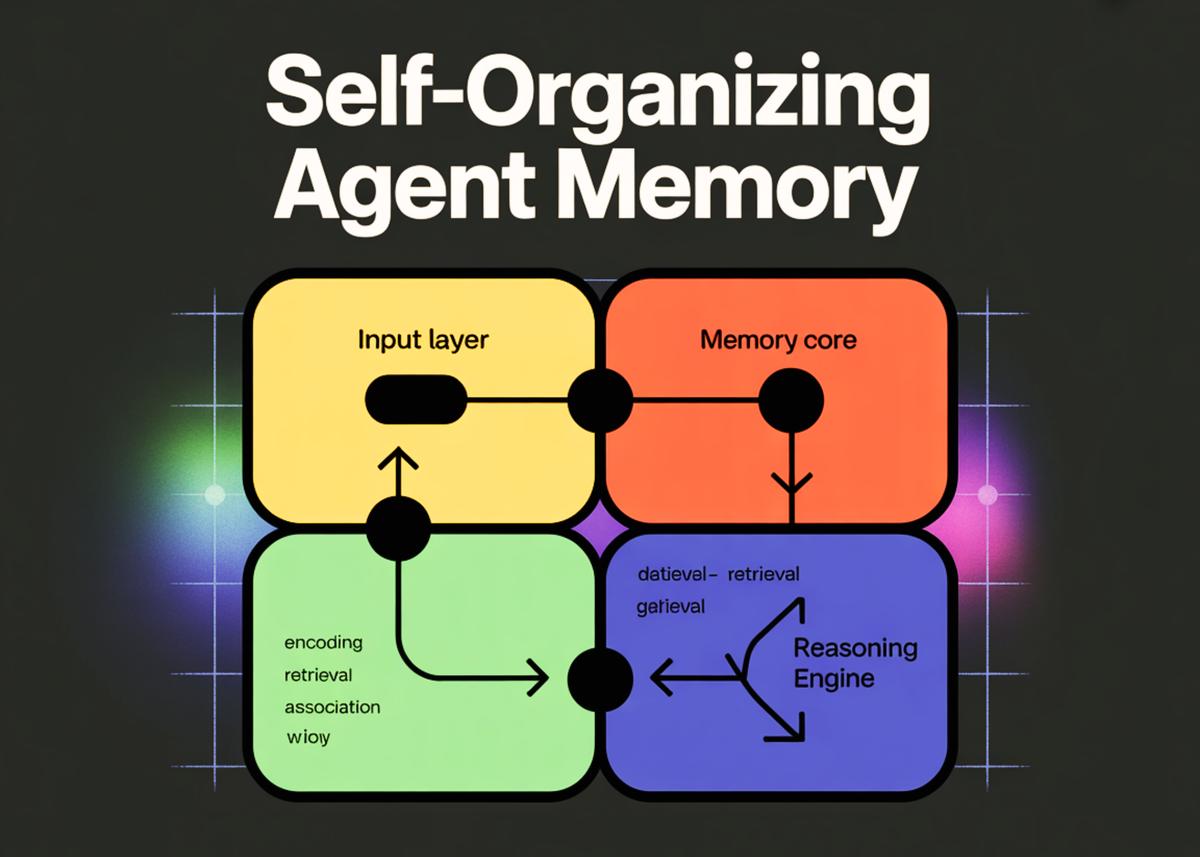
- •Memory split into cells, scenes, and summaries.
- •SQLite stores structured memory with full-text search.
- •Memory manager extracts, compresses, and consolidates interactions.
- •Agent retrieves relevant scenes before generating responses.
- •System enables long‑term, explainable reasoning without opaque vectors.
Pulse Analysis
Long‑term context has become a critical bottleneck for conversational AI, especially in enterprise settings where continuity across interactions drives value. The self‑organizing memory system presented leverages a lightweight SQLite engine to persist knowledge in a relational format, enabling deterministic retrieval via full‑text search. By separating memory concerns from the reasoning engine, developers can iterate on each component independently, ensuring that the language model remains focused on generation while the memory layer handles extraction, compression, and summarization. This architectural split also simplifies compliance and auditability, as stored facts are explicit and searchable rather than hidden in high‑dimensional embeddings.
The core of the system revolves around three abstractions: memory cells that capture granular facts, scenes that group related cells, and scene summaries that distill the most salient information. Memory cells are generated by prompting an LLM to transform raw dialogue into JSON objects annotated with type and salience scores. These cells are inserted into both a relational table and an FTS5 virtual table, providing fast lexical lookup and ranking by importance. Periodic consolidation runs a second LLM pass to synthesize a concise narrative for each scene, which is then upserted into a dedicated scenes table. This iterative process ensures that the agent’s knowledge base evolves organically without manual curation.
When responding to a user, the worker agent first queries the memory store for scenes matching the current query, assembles their summaries, and feeds this context back into the LLM. The response is generated with full awareness of prior interactions, and the resulting exchange is fed back into the MemoryManager for continuous learning. This feedback loop creates a virtuous cycle where the agent becomes increasingly knowledgeable over time, supporting use cases such as project management assistants, compliance bots, and personalized tutoring platforms. By combining deterministic storage with LLM‑driven abstraction, the approach offers a scalable, transparent alternative to pure vector databases, positioning it as a compelling blueprint for next‑generation AI agents.
How to Build a Self-Organizing Agent Memory System for Long-Term AI Reasoning
0
Comments
Want to join the conversation?
Loading comments...