Machine Unlearning: The Technical Solution to AI Copyright Scandals
Companies Mentioned
Why It Matters
Selective forgetting enables firms to meet GDPR‑style erasure mandates and copyright defenses while avoiding costly model rebuilds, safeguarding both legal compliance and product reliability.
Key Takeaways
- •Unlearning targets individual records, authors, or content groups for removal
- •Governance layers log requests, apply updates, and generate audit proof
- •Performance testing ensures core model quality remains intact
- •Technique reduces legal exposure but cannot erase indirect learned patterns
Pulse Analysis
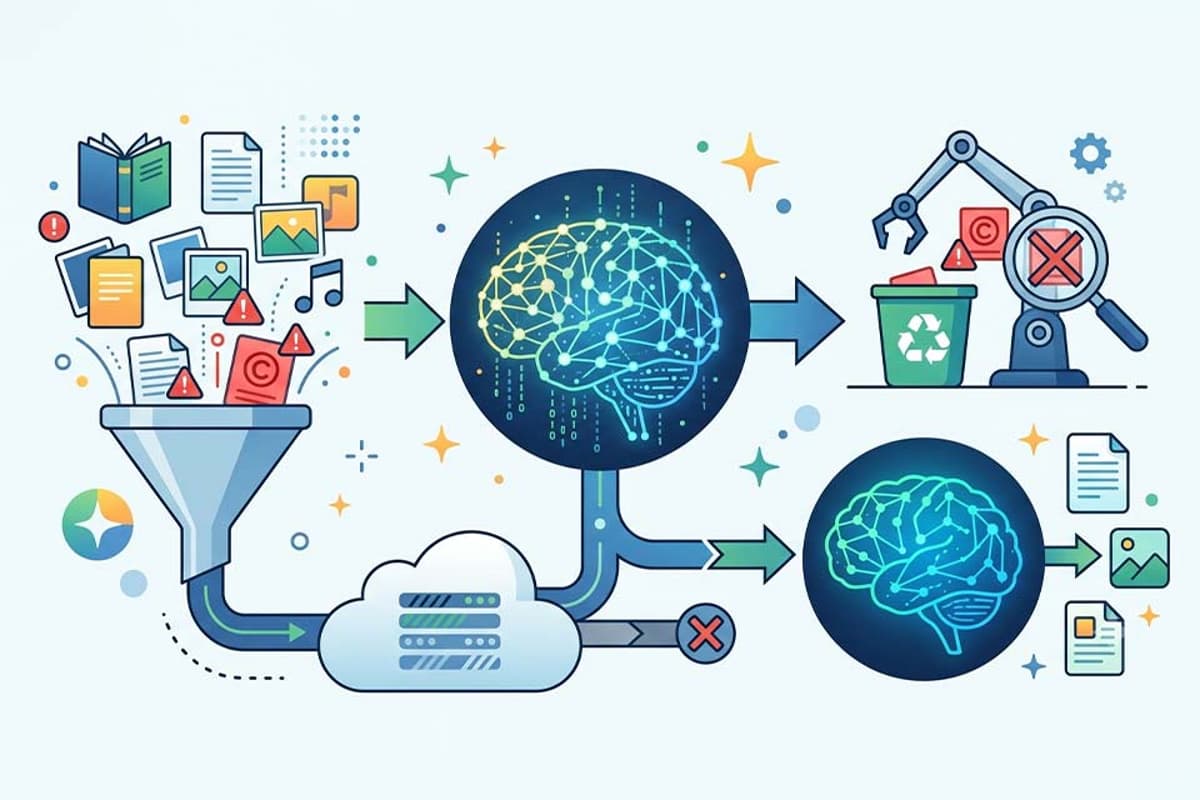
Machine unlearning has emerged as a pragmatic response to the growing legal pressure on AI developers to honor data‑erasure requests. Traditional deletion of source files leaves a hidden imprint in model weights, meaning that copyrighted text or personal information can still surface in outputs. By tracing the influence of specific data points and applying controlled weight adjustments, unlearning bridges the gap between privacy regulations such as the GDPR and the opaque nature of deep‑learning models, offering a technically feasible path to compliance.
From a technical standpoint, unlearning operates through a multi‑step workflow: data mapping identifies the exact assets to be removed, influence tracing pinpoints where those assets affect model behavior, and a controlled update rewrites the affected parameters or retrieval components. This process is typically overseen by a dedicated governance layer that records each request, runs extraction and membership‑inference tests, and stores verifiable audit logs. While the method can preserve overall model performance, it does introduce trade‑offs—over‑aggressive removal may degrade nuanced reasoning, and indirect patterns learned from similar data may persist, requiring ongoing monitoring.
The business implications are significant. Companies can now address copyright disputes and privacy complaints without incurring the multi‑million‑dollar costs of full model retraining, accelerating time‑to‑remediation and protecting revenue streams. Early adopters in finance, media, and enterprise AI are building unlearning capabilities into their MLOps pipelines, signaling a shift toward responsible AI as a core operational competency. As regulators tighten data‑rights enforcement, the ability to demonstrate verifiable deletion will become a competitive differentiator, driving broader industry investment in scalable unlearning solutions.
Machine Unlearning: The Technical Solution to AI Copyright Scandals
Comments
Want to join the conversation?
Loading comments...