Token Delivery Network: The Next Operating Model for AI Inference
Why It Matters
By moving inference to the edge, TDNs reduce latency and enable compliance with data‑sovereignty rules, opening new markets for telcos and cloud operators. The token‑metered model creates a scalable, service‑oriented revenue stream beyond raw GPU sales.
Key Takeaways
- •TDN routes AI requests to optimal edge endpoints based on multiple criteria.
- •Tokens replace GPU hours as the primary usage metric for inference.
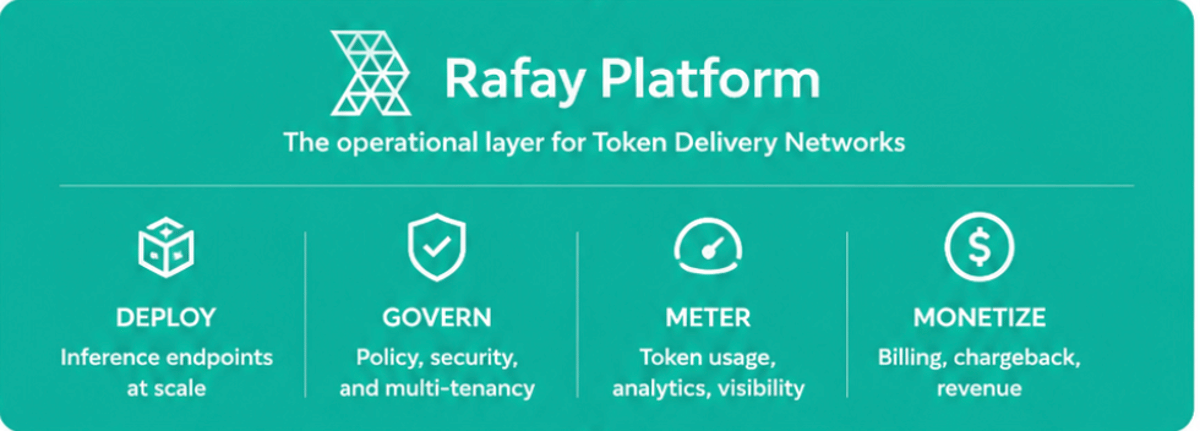
- •Rafay's platform automates deployment, governance, and monetization of edge models.
- •Telcos and sovereign clouds can monetize existing edge infrastructure via TDNs.
Pulse Analysis
The rise of generative AI has turned inference latency into a competitive differentiator, much like video streaming once made content delivery networks essential. By situating model endpoints at programmable edges—data centers, telecom sites, or enterprise facilities—Token Delivery Networks replicate the CDN playbook for AI, delivering curated insights instead of static files. This proximity reduces round‑trip time, improves user experience, and satisfies increasingly strict data‑sovereignty regulations, positioning edge inference as a core infrastructure layer rather than an afterthought.
At the heart of a TDN is a token‑based metering system that abstracts raw GPU hours into a service‑level unit. Each request consumes tokens, allowing providers to price AI outputs by value rather than compute time. Rafay’s platform supplies the orchestration layer that spins up, governs, and bills these edge endpoints automatically, integrating with existing DNS and CDN routing mechanisms. The programmable edge concept ensures that capacity can be provisioned wherever power and network connectivity exist, turning fragmented micro‑data centers into a coherent AI service fabric.
For telcos, sovereign clouds, and neocloud operators, the TDN model unlocks a new revenue frontier. Their extensive regional footprints already meet the physical requirements for low‑latency inference, and the software layer supplied by firms like Rafay enables them to package that capacity as token‑metered AI services. As AI workloads shift from bulk GPU rentals to consumable, policy‑aware APIs, the economics of AI delivery will increasingly mirror the subscription and usage‑based models that dominate modern cloud services, reshaping the competitive landscape for the next decade.
Token Delivery Network: The Next Operating Model for AI Inference
Comments
Want to join the conversation?
Loading comments...