
Recent Posts
Video•Feb 20, 2026
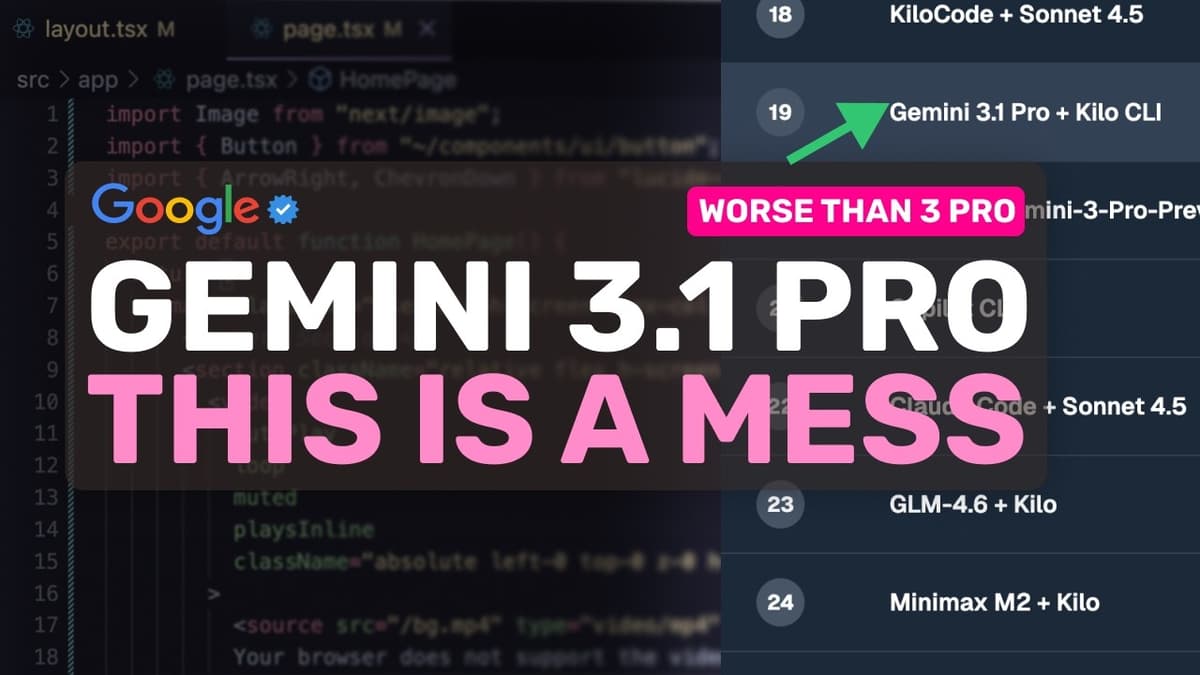
Gemini 3.1 Pro (Fully Tested): This MODEL Is ACTUALLY BAD & A MESS.
Google unveiled Gemini 3.1 Pro, a 0.1‑step upgrade touted as a major reasoning leap, featuring a 1 million‑token context window and a 65,000‑token output limit. The company claims a jump to 77.1 % on the ARC‑AGI2 benchmark, positioning the model as a flagship offering. Independent testing on the creator’s Kingbench suite tells a different story. On the oneshot benchmark Gemini 3.1 Pro scored 96 % (212/220), down from the predecessor’s perfect 100 % while costing $1.73 versus $0.85 to run the same test. More strikingly, its agentic performance fell to 49.2 %—ranked 19th of 46—after a previous 71.4 % score placed it in the top ten. The regression stems from a bloated planning phase. In a simple terminal‑calculator task the model spent 37 seconds looping through repetitive “thinking” sections, and on an image‑cropper task it lingered in planning for 114 seconds before emitting any code. It also failed to use Kilo CLI’s ask‑question tool, duplicated code, and introduced package‑name typos that caused npm 404 errors, whereas competitors like Sonnet 4.6 or Claude Opus 4.6 move straight to implementation. For developers paying per token, Gemini 3.1 Pro offers no clear advantage over cheaper or more capable alternatives. Its only viable niche is the free‑tier access where a 96 % oneshot score is attractive; otherwise, models such as Sonnet 4.6, Opus 4.6, or GLM‑5 deliver higher accuracy and far more efficient agentic behavior, casting doubt on Google’s ability to compete on performance‑price grounds.
By AICodeKing

Video•Feb 14, 2026
My AI Frontend Workflow: This Is the EASIEST WORKFLOW to BUILD AMAZING UIs with AI!
The video tackles the pervasive problem of "AI slop" UIs—generic, purple‑gradient‑filled sites that lack visual identity. It argues that prompting alone cannot fix the issue because large language models reproduce the most common patterns in their training data. Instead, the...
By AICodeKing

Video•Feb 12, 2026
RIP Amp Code? : Amp Code VS Code Extension Is Done, Here's the Alternative for You.
AMP, the AI coding agent originally from Sourcegraph, announced it will permanently discontinue its VS Code extension, opting to concentrate on a standalone CLI and web experience. The decision was disclosed on the company’s “Raising an Agent” podcast, where founders Quinn...
By AICodeKing
Video•Feb 9, 2026
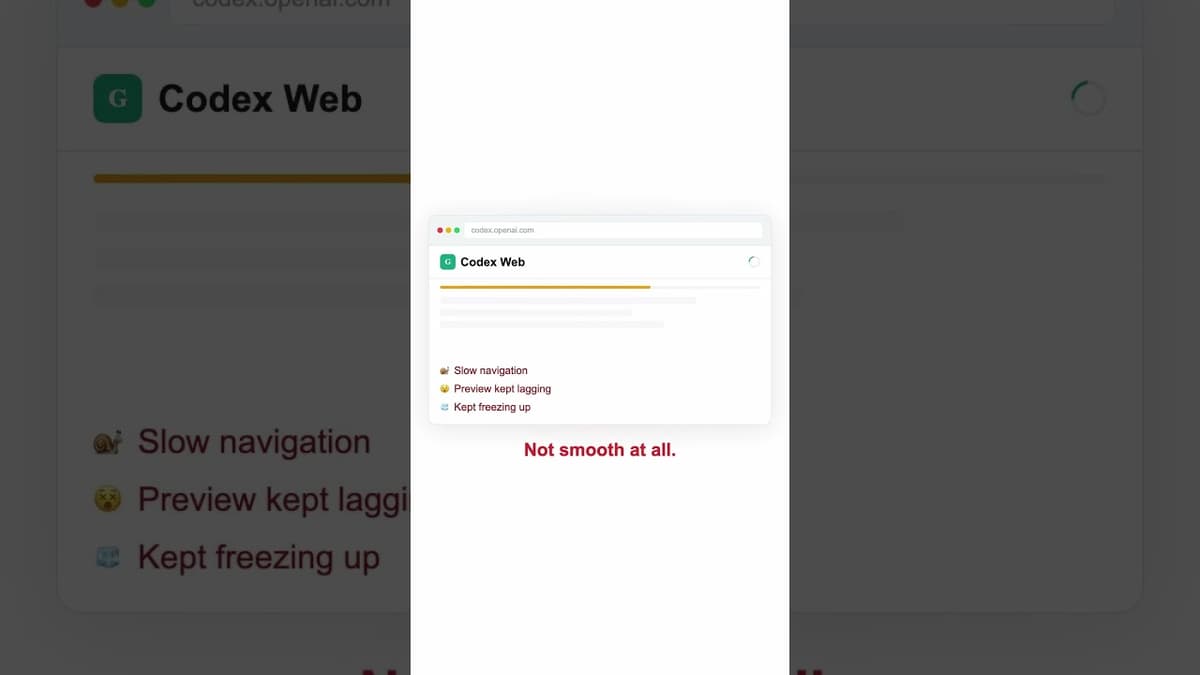
LOL, Opus 4.6 Better than Codex? #claude #newclaude
Two AI coding models—Opus 4.6 and Codeex (GPT 5.3)—were launched simultaneously and put to the test building a complete landing page from scratch. The reviewer ran Codeex through its web interface and Opus 4.6 via Kilo Codes’ cloud agents, noting stark differences in user...
By AICodeKing