

How to Run LLMs Locally (Great For Learning and Privacy)
The video explains that open‑source large language models such as Gwen, Kimmy, and the GLM family can now be run on a personal computer, eliminating the need for cloud APIs and preserving data privacy. It reviews five toolchains. Llama.cpp is the low‑level C++ engine that introduced the GGUF container and 4‑bit quantization, allowing multi‑gigabyte models to fit on laptops. Ollama builds on llama.cpp to automate downloads, quantization, and expose an OpenAI‑compatible endpoint for rapid prototyping. LM Studio adds a cross‑platform GUI that visualizes hardware requirements and lets users switch models without restarting. For production workloads, vLLM and its competitor SGLang use paged attention and continuous batching to maximize GPU throughput and handle many concurrent requests. Finally, Apple’s MLX LM leverages the unified memory architecture of M‑series chips to run larger models faster than traditional CPU‑GPU splits. The presenter demonstrates commands such as “ollama run gemma‑4” that pull weights and launch a local chat server, and explains how vLLM’s KV‑cache block splitting frees memory for larger batches. He also notes that SGLang’s Radix Attention caches shared prompt prefixes, making it ideal for retrieval‑augmented generation. On an M‑series Mac Studio with 192 GB RAM, MLX LM can host models that would otherwise require multiple expensive GPUs. These options reduce the barrier to entry for developers, researchers, and privacy‑concerned users, enabling a full AI stack—from experimentation to enterprise‑scale serving—on commodity hardware. The rapid availability of such tools signals a shift toward decentralized AI deployment and could reshape how companies build internal assistants and data‑intensive pipelines.
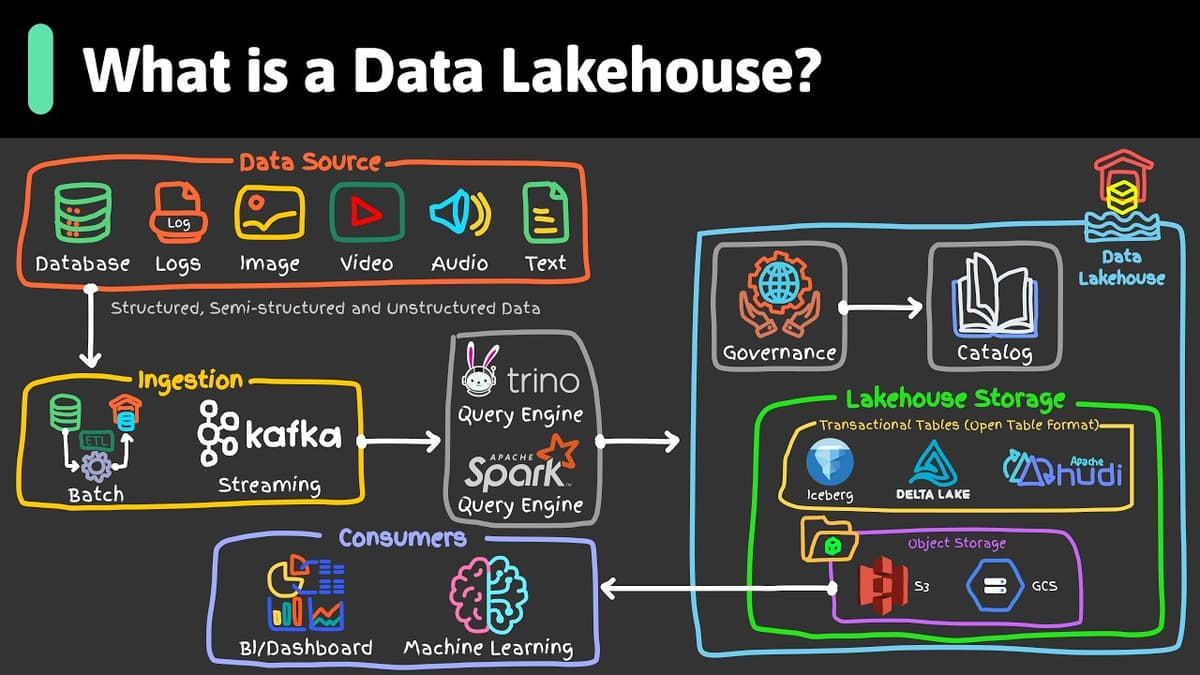
What Is a Data Lakehouse?
The video explains the emerging data lakehouse architecture, positioning it between traditional data warehouses—optimized for curated, ACID‑compliant SQL analytics—and data lakes, which store raw, massive‑scale files cheaply. It highlights the pain points of maintaining separate systems, such as duplicated ingestion...