Video•Aug 31, 2024
How Might LLMs Store Facts | Deep Learning Chapter 7
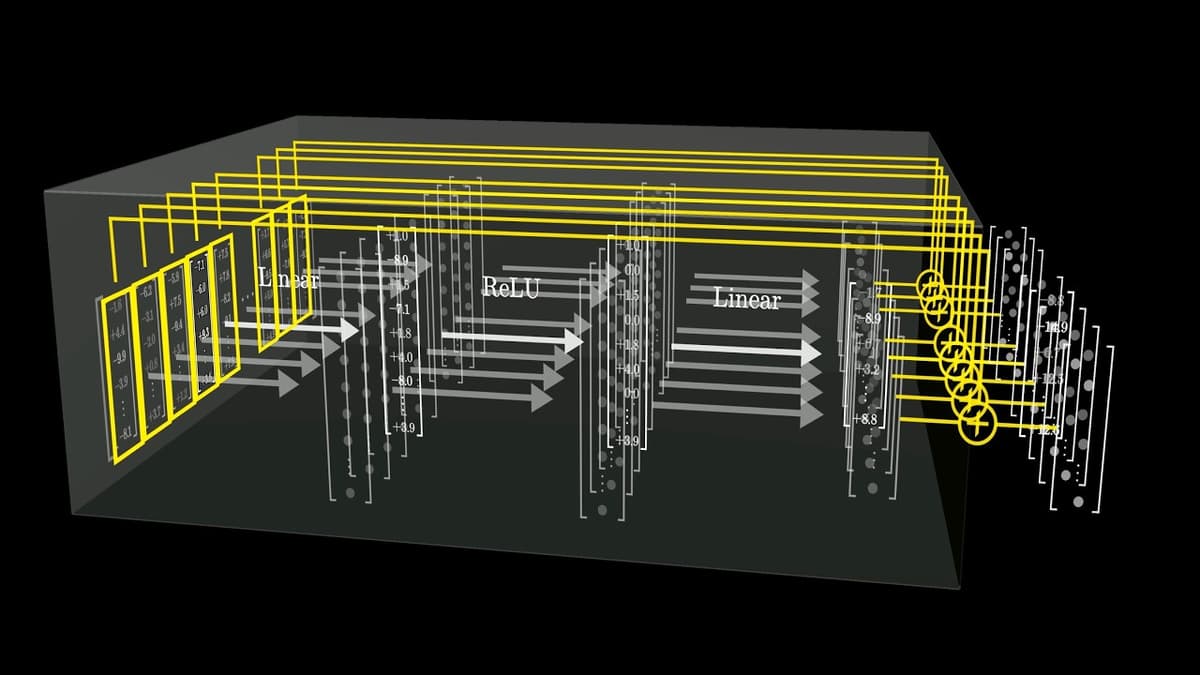
Researchers and the video explain how factual knowledge in transformer language models may be stored primarily inside the feedforward multi-layer perceptron (MLP) blocks rather than attention. Using a toy example—how the fact “Michael Jordan plays basketball” could be encoded—the presenter shows that high-dimensional token vectors can align with directions for first name, last name and concepts, and that MLPs can map a vector encoding a person’s full name into the concept direction for their sport via two matrix multiplications and a nonlinearity. The walkthrough emphasizes that MLPs act on each token vector in parallel (no cross-token communication) and that interpreting these simple computations is hard despite their conceptual simplicity. The discussion draws on recent DeepMind work and frames this as a partial, mechanistic explanation for where models “memorize” facts.