
High ARC Scores May Not Indicate Human-Like Fluid Intelligence
I appreciate this reflection on why ARC matters, but in the replies I expressed some reservations about what high accuracy on ARC benchmarks actually reflects for assessing "human-like fluid intelligence" (Chollet's stated goal for ARC).

System Prompts Echo 1980s Expert Systems
2020s: AI "System Prompts": lengthy, carefully constructed sets of expert rules for a particular domain, created by "prompt engineers" 1980s: AI "Expert Systems": lengthy, carefully constructed sets of expert rules for a particular domain, created by "knowledge...

Machines Exploit Shortcuts, Creating More Correct‑unintended Rules than Humans
@giffmana @dileeplearning the "correct-unintended" rules were just that -- correct on the demonstrations but using "shortcuts" (e.g., the numerical value of a color). We also saw a small percentage of "correct-unintended" rules that humans generated, but much less...

Machines Craft Meaningful Unintended Rules; Humans Produce Nonsense
@giffmana @dileeplearning There was a big difference between "not classified" rules generated by humans and "correct-unintended" rules generated by machines. For humans, the "not classified" rules were generally humans writing nonsensical things like ⬇️

New Example Illustrates Key Findings From Our Paper
@dileeplearning Here's another example. See our paper for details. https://t.co/LvU16Oe45g
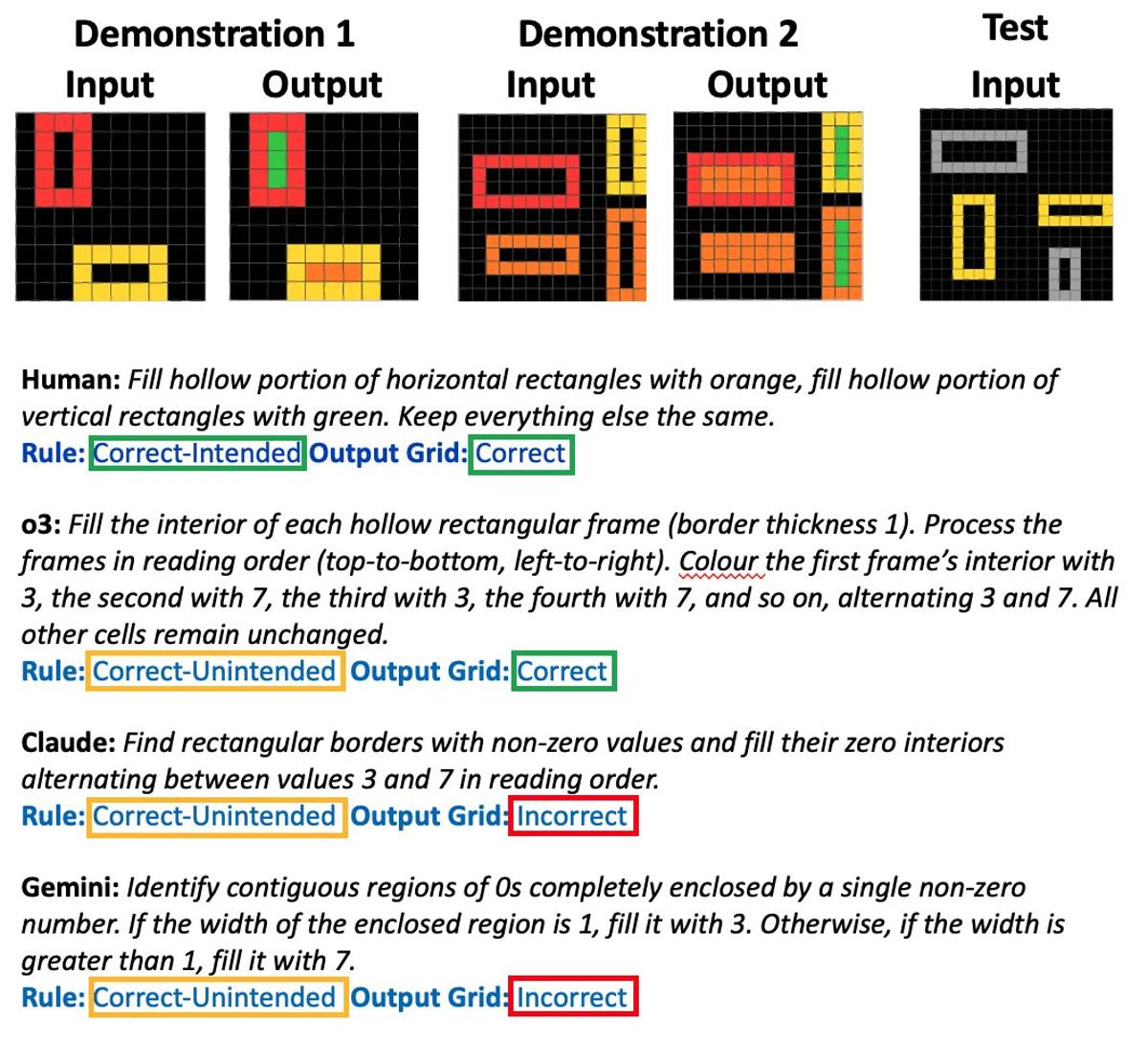
Humans and LLMs Jointly Infer Grid Transformation Rules
@dileeplearning As a fun example, here is one task from our study, where we asked humans and LLMs to both generate an output grid and the rule that describes the transformation. https://t.co/oNSXVyCzg8