
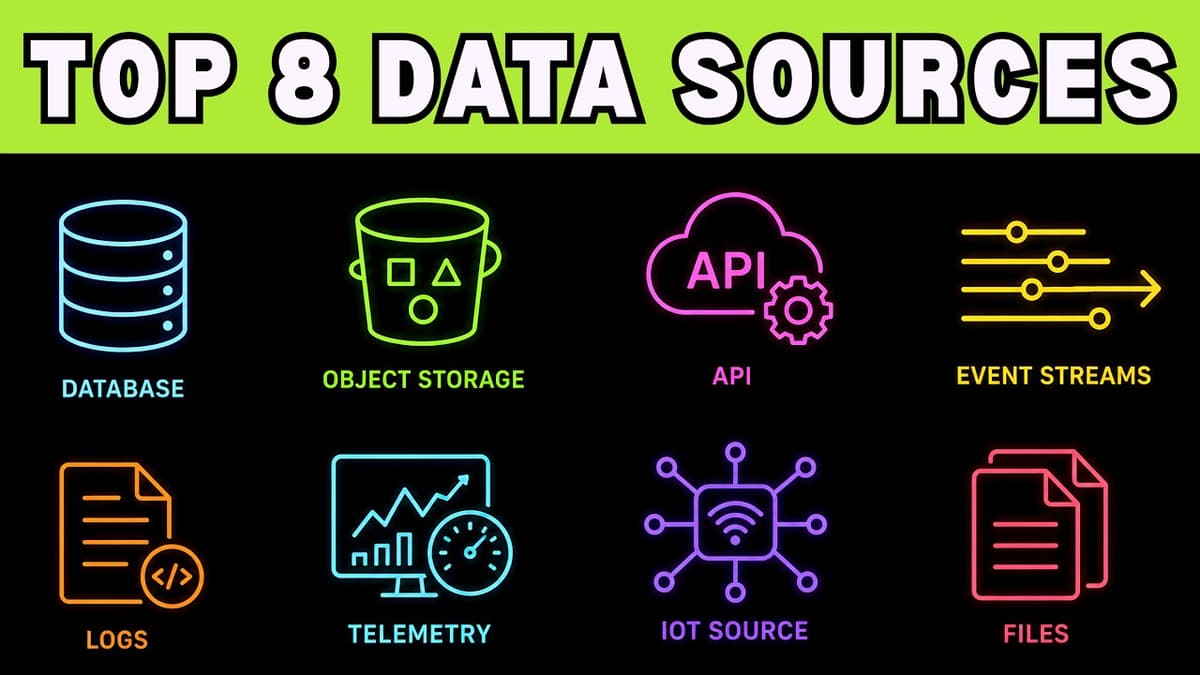
Master These 8 Data Sources to Become a Better Data Engineer
The video outlines the eight most common data sources that data engineers must master, emphasizing that pipeline design begins with a deep understanding of where data originates. It walks through application databases, file storage, third‑party APIs, event streams, logs and telemetry, IoT devices, and manual business spreadsheets, highlighting the unique characteristics and failure modes of each. Key insights include the need for schema‑change detection in production databases, robust file‑arrival and format validation, pagination and rate‑limit handling for APIs, idempotent processing to survive duplicate or out‑of‑order events, and vigilant monitoring of noisy, evolving log formats. The presenter stresses that each source carries distinct speed, volume, and reliability patterns that dictate specific quality‑control measures. Illustrative examples range from a learning platform’s PostgreSQL tables to Stripe payment APIs, Kafka event streams, and a finance team’s monthly Excel uploads. Notable quotes such as “the pipeline does not start when you write code; it starts when you understand the source” underscore the practical mindset required to avoid silent data corruption. The overarching implication is clear: data engineers who map source‑specific risks and embed automated checks can build resilient pipelines, reduce downstream errors, and deliver trustworthy analytics faster. Mastery of these sources translates directly into more reliable business intelligence and competitive advantage.

The Data Engineering Concepts Nobody Explains Properly
The video breaks down the core data‑processing patterns that shape modern engineering platforms—ETL, ELT, batch, stream, micro‑batch, and the Lambda/Kappa architectural choices. It emphasizes that each pattern dictates how data moves, how quickly results appear, and how resilient the system...

9 Things I Do as a Data Engineer on Real Projects (9AM to 5PM)
The video demystifies the data‑engineer role, showing it is far more than writing ETL code. A typical day begins with client and business‑user meetings to clarify requirements, followed by scoping sessions where engineers estimate effort, identify dependencies, and flag risks.\n\nTechnical...

Data Engineering Is Dead (Again)
The video argues that traditional data engineering, as we know it, is effectively dead, but stresses that the discipline is merely evolving through successive technological waves. It traces the role from on‑prem data warehouses, through the cloud migration, Hadoop and Spark...

Lambda vs Kappa Architecture Explained in 2 Minutes
The video provides a concise comparison of Lambda and Kappa architectures, two dominant paradigms for processing large‑scale data streams. Lambda, introduced to marry batch accuracy with real‑time speed, relies on separate batch and streaming pipelines, whereas Kappa streamlines the stack...

Stream Processing Explained in 2 Minutes
The video introduces stream processing as a fundamentally different paradigm from traditional batch analytics, emphasizing that data is handled the moment it arrives rather than waiting for scheduled aggregation. It frames the concept through vivid analogies—a hospital heart‑rate monitor and...

Batch Processing Explained in 2 Minutes
Batch processing aggregates data over a defined time window before executing a single job, as illustrated by bank reconciliation and payroll cycles. In practice, batch jobs run on schedules ranging from every 15 minutes to weekly, offering predictability and cost efficiency....

ETL Explained in 2 Minutes
The video “ETL Explained in 2 Minutes” breaks down the extract‑transform‑load process using a food‑factory analogy, illustrating how raw data from disparate sources must be cleaned before reaching a warehouse. It outlines the three stages: extraction from transactional databases, APIs or...

The Core Storage and Architecture of Data Engineering - Explained in 10 Minutes
The video walks through the foundational storage paradigms and architectural patterns that underpin modern data engineering platforms, from raw data lakes to structured warehouses and the emerging lakehouse model. It explains that data lakes—often implemented with Azure Data Lake Storage or...

OLTP vs OLAP Explained in 2 Minutes
The video explains the fundamental distinction between online transaction processing (OLTP) and online analytical processing (OLAP) using a supermarket analogy. It shows how a checkout counter represents OLTP—rapid, accurate updates to inventory and payments—while end‑of‑day sales reports illustrate OLAP’s focus...

Medallion Architecture Explained in 2 Minutes
The video introduces the medallion architecture, a data‑engineering pattern that organizes datasets into three progressive layers—bronze, silver, and gold—to avoid overwriting raw inputs. It stresses that ingesting data should not be cleaned in a single pass because doing so erodes flexibility,...