
Recent Posts
Video•Dec 27, 2025
TiDAR: Think in Diffusion, Talk in Autoregression (Paper Analysis)
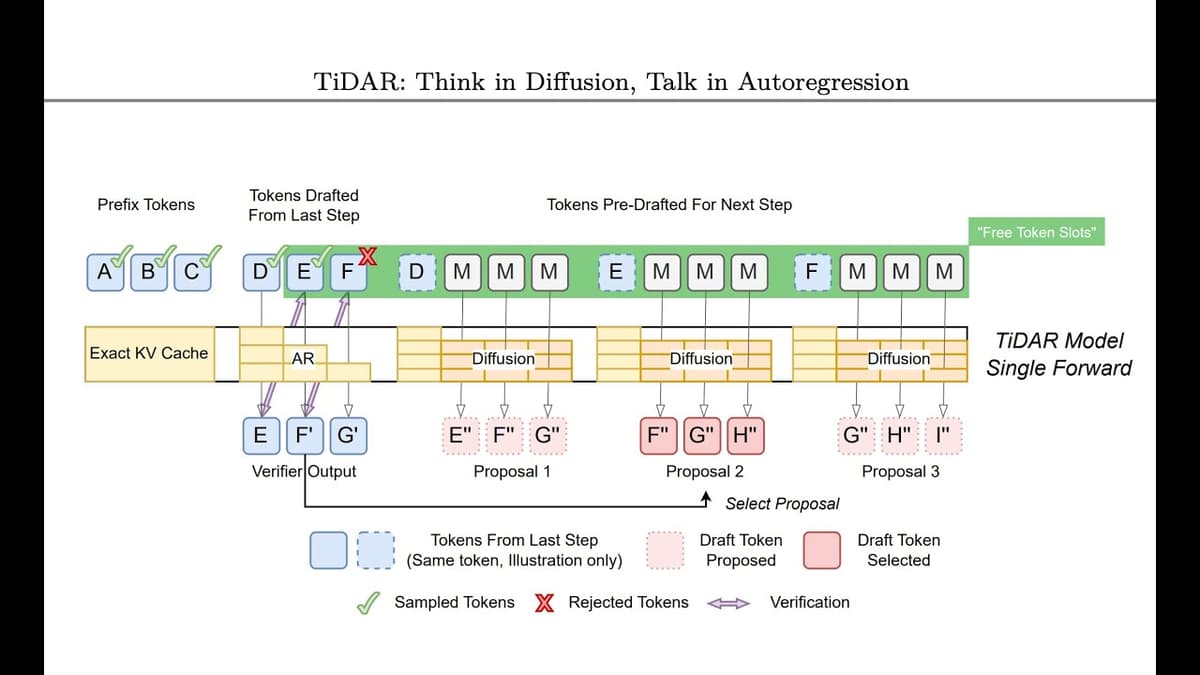
The Nvidia TiDAR paper introduces a hybrid autoregressive‑diffusion language model that exploits unused GPU capacity during large‑language‑model inference. By combining diffusion‑style parallel token prediction with traditional autoregressive sampling, TiDAR achieves higher throughput while preserving the exact output distribution of a pure autoregressive decoder. The authors observe that standard autoregressive inference is memory‑bound, leaving GPUs under‑utilized. Diffusion models can generate many future tokens at once but only produce marginal distributions, harming quality. TiDAR resolves this by using diffusion to generate speculative token suggestions and then verifying them with the autoregressive head, effectively parallelizing the check without the quality loss of pure diffusion or the overhead of conventional speculative decoding. A key illustration from the paper describes the approach as “a close‑to‑free lunch,” noting that the extra GPU cycles are already available and only modest additional electricity is required. Unlike speculative decoding, which relies on a smaller, fast model that may mis‑predict and waste compute, TiDAR’s diffusion component provides high‑fidelity suggestions directly from the same model, eliminating the need for an external oracle. The result is a significant speedup in LLM serving, lower latency, and better hardware utilization, promising cost reductions for cloud providers and enterprises deploying generative AI. As inference efficiency becomes a bottleneck for scaling AI services, TiDAR’s architecture could reshape deployment strategies across the industry.
By Yannic Kilcher

Video•Dec 14, 2025
Titans: Learning to Memorize at Test Time (Paper Analysis)
The video reviews Google Research’s “Titans: Learning to Memorize at Test Time,” a NeurIPS paper that proposes a novel architecture enabling language models to retain information beyond their fixed context window. The presenter explains that the model treats the keys...
By Yannic Kilcher