Recent Posts

News•Feb 26, 2026
5 Useful Python Scripts for Automated Data Quality Checks
The article presents five open‑source Python scripts that automate common data‑quality checks, ranging from missing‑value analysis to cross‑field consistency validation. Each tool reads CSV, Excel or JSON inputs, applies schema‑driven rules or statistical methods, and generates detailed reports with actionable recommendations. The author provides direct GitHub links for immediate download and integration into existing pipelines. By automating these checks, organizations can catch errors early, reduce manual effort, and improve the reliability of downstream analytics.
By KDnuggets

News•Feb 24, 2026
5 Python Data Validation Libraries You Should Be Using
Data validation is gaining prominence as pipelines become more complex, and Python now offers a diverse set of libraries to address this need. The article reviews five tools—Pydantic, Cerberus, Marshmallow, Pandera, and Great Expectations—each targeting a different validation paradigm, from...
By KDnuggets

News•Feb 20, 2026
7 XGBoost Tricks for More Accurate Predictive Models
The article outlines seven practical XGBoost tricks that boost predictive accuracy on tabular data. It demonstrates how adjusting learning rate, tree depth, subsampling, regularization, early stopping, hyper‑parameter search, and class weighting can transform a baseline model. Code snippets using the...
By KDnuggets

News•Feb 19, 2026
FastMCP: The Pythonic Way to Build MCP Servers and Clients
FastMCP is a Python framework that streamlines building Model Context Protocol (MCP) servers and clients using decorator‑based abstractions. It handles JSON‑RPC 2.0 messaging, async execution, and multiple transports such as stdio, HTTP, WebSocket, and SSE, while providing built‑in error handling and...
By KDnuggets
News•Feb 18, 2026
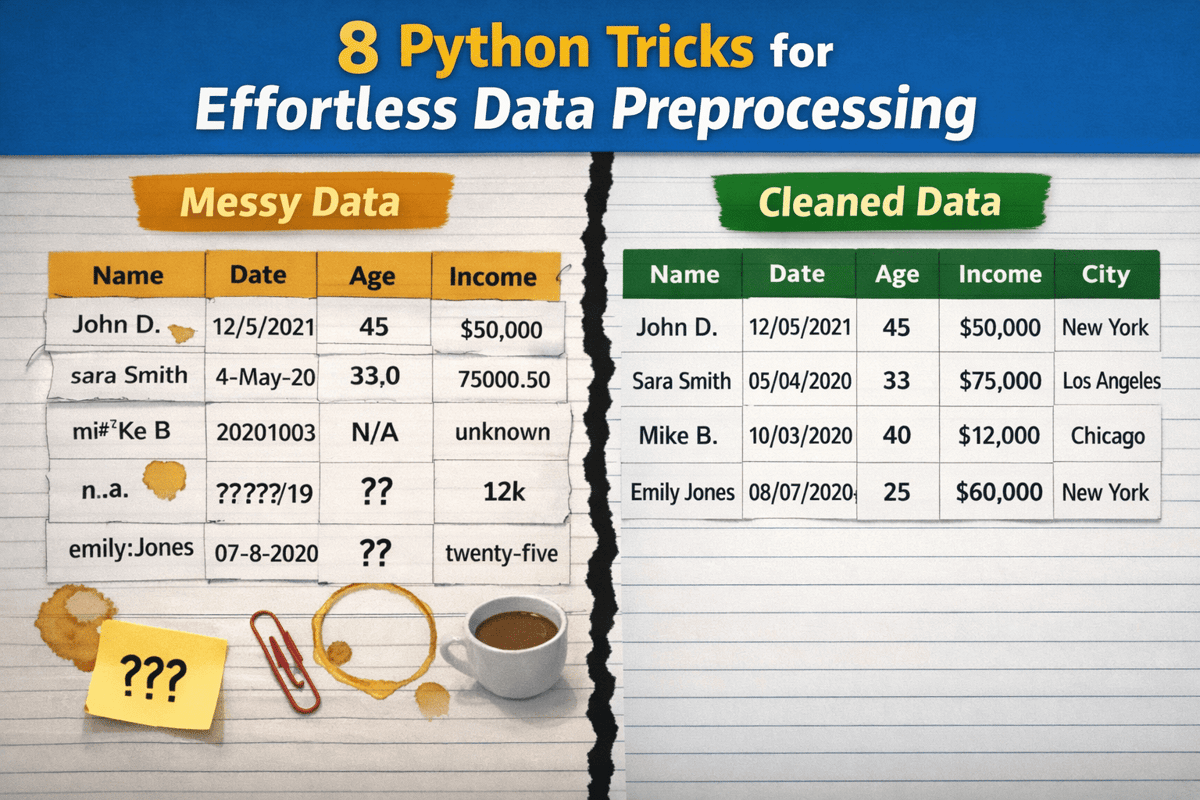
From Messy to Clean: 8 Python Tricks for Effortless Data Preprocessing
The article outlines eight concise Python tricks that streamline data preprocessing, from normalizing column names to clipping outliers. Each technique uses pandas functions to handle whitespace, type conversion, date parsing, missing values, categorical standardization, duplicate removal, and quantile‑based capping. The...
By KDnuggets

News•Feb 16, 2026
All About Feature Stores
Feature stores have moved from niche tools to core infrastructure for operational machine‑learning, providing a single source of truth for features used in both training and online inference. The concept was coined by Uber in 2017 and commercialized by Tecton...
By KDnuggets

News•Feb 16, 2026
Learn Python, SQL and PowerBI to Become a Certified Data Analyst for FREE This Week
From February 16–22, DataCamp’s entire curriculum is 100% free.
By KDnuggets
News•Feb 16, 2026
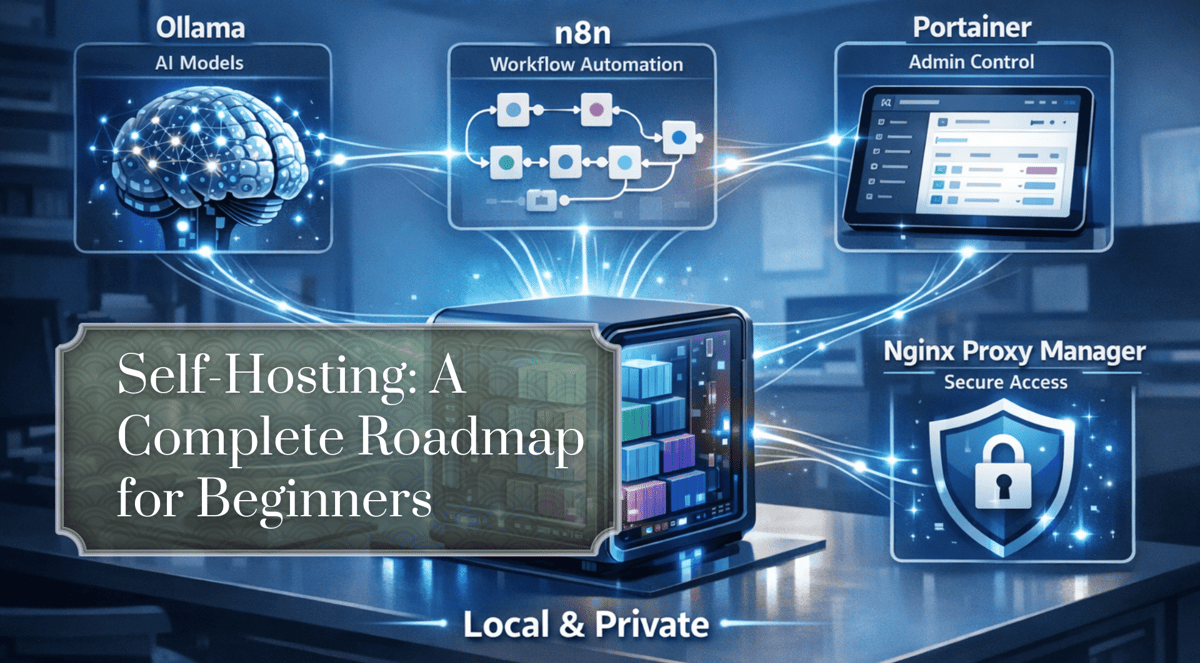
Self-Hosted AI: A Complete Roadmap for Beginners
The article outlines a step‑by‑step roadmap for building a private AI hub using Docker, Ollama, and n8n. It targets beginners seeking to run large language models locally without relying on cloud providers. The guide emphasizes containerization, open‑source model serving, and...
By KDnuggets