Google Deepmind's D4RT Model Aims to Give Robots and AR Devices More Human-Like Spatial Awareness
•January 24, 2026
0
Companies Mentioned
Why It Matters
By delivering near‑real‑time 4D scene understanding on modest hardware, D4RT accelerates deployment of intelligent perception in robotics and AR, and marks a step toward richer world models needed for future AGI research.
Key Takeaways
- •D4RT reconstructs 4D scenes up to 300× faster.
- •Single decoder handles depth, pose, point clouds.
- •Processes one‑minute video in five seconds on TPU.
- •Enables on‑device spatial awareness for robots and AR.
Pulse Analysis
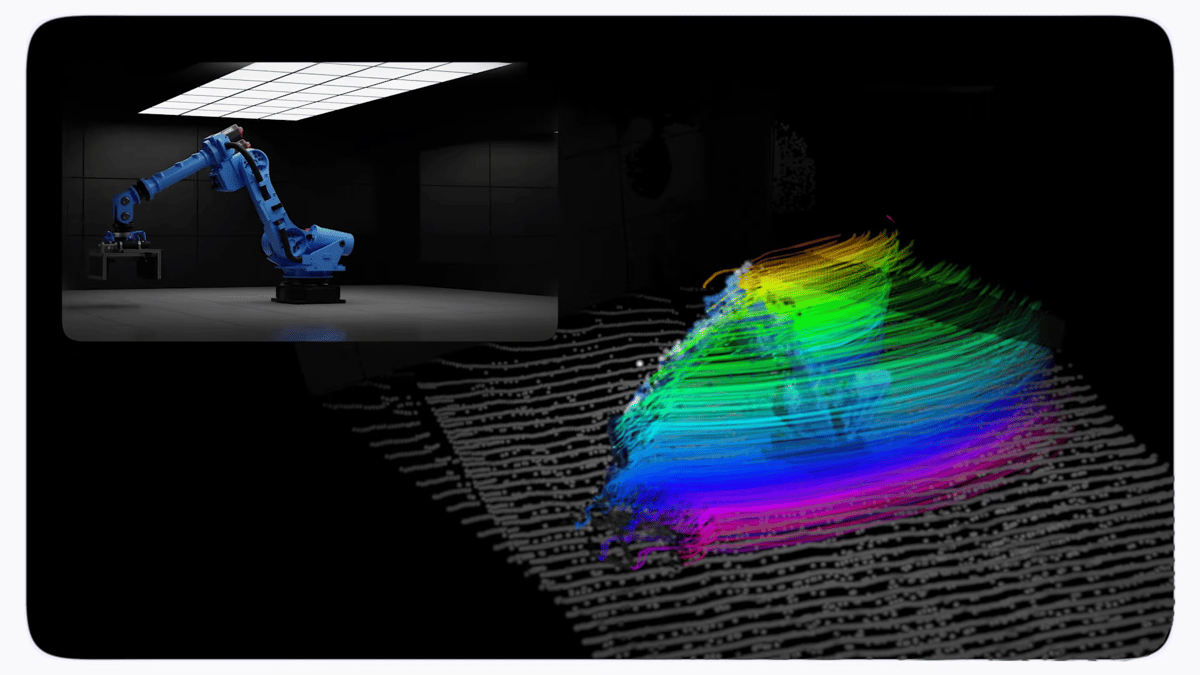
The quest for true spatial cognition has long hampered AI agents that must navigate dynamic environments. Traditional pipelines stitch together separate depth, motion, and pose networks, incurring heavy optimization overhead and limiting scalability. DeepMind’s D4RT sidesteps this fragmentation by employing a Scene Representation Transformer that encodes an entire video sequence into a global latent map. A lightweight decoder then extracts only the needed spatiotemporal points, allowing each query to run independently and be massively parallelized on modern accelerators.
Performance gains are dramatic. In internal tests D4RT processes a 60‑second video in roughly five seconds on a single TPU, a speedup ranging from 18‑to‑300× over competing approaches. For camera‑pose estimation it achieves over 200 fps, outpacing VGGT by ninefold and MegaSaM by two orders of magnitude, while also delivering superior accuracy on depth and point‑cloud metrics. The model’s unified decoder eliminates redundant computation, making it far more efficient than multi‑model stacks that require iterative refinement.
Beyond raw speed, D4RT’s ability to infer object locations even when occluded positions it as a practical engine for on‑device robotics and augmented‑reality applications. Real‑time 4D reconstruction enables robots to anticipate motion trajectories and AR glasses to anchor virtual objects with millimeter precision. In the longer view, DeepMind frames the work as a building block toward comprehensive world models—core to the next generation of AGI systems that learn from continuous experience rather than static token prediction. As hardware continues to evolve, D4RT could become a foundational perception layer for a wide range of intelligent products.
Google Deepmind's D4RT model aims to give robots and AR devices more human-like spatial awareness
0
Comments
Want to join the conversation?
Loading comments...