
Aleksei Petrov
CTO at QuantFlow; builds AI agents that integrate with CI and issue trackers to automate coding and delivery with telemetry and controls.

SessionStart Hook Cuts Token Usage by Half
The nav-start skill used to make 6 Read calls at session start. Replaced them with a Claude Code SessionStart hook that injects state via additionalContext — before the first user turn. Same data, zero reads, ~35k tokens saved per session 🔥 Measured: 73.3k → 37.8k. Navigator v6.9.0 https://github.com/alekspetrov/navigator/releases/tag/v6.9.0
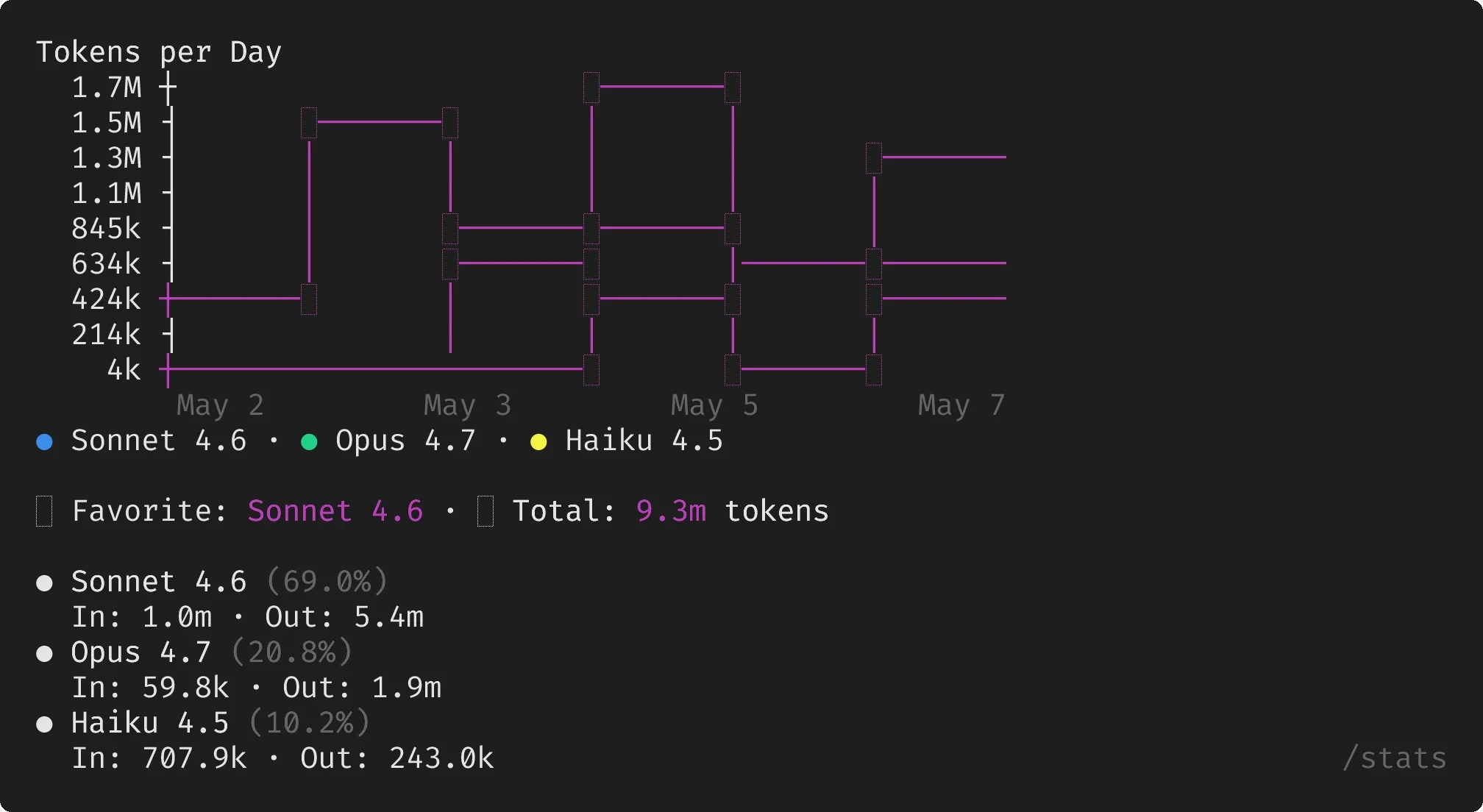
Sonnet Leads; Opus Powers Planning
Flexing on the stat after 9 releases. Sonnet is dominant model now, Opus – planning and research. Harness: ClaudeCode (opus) + Pilot agent (sonnet).
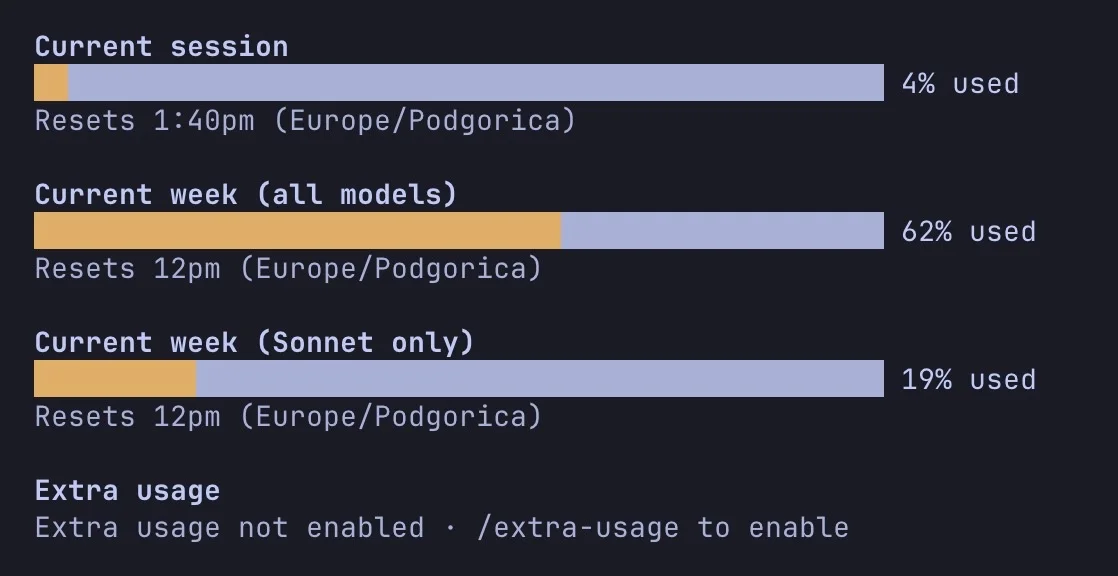
Optimizing AI Pipelines with Sonnet 4.6 and ClaudeCode Opus
I used Sonnet 4.6 as Pilot's core execution model. Plus turned ClaudeCode Opus 4.7 to medium thinking. Token usage 🤌
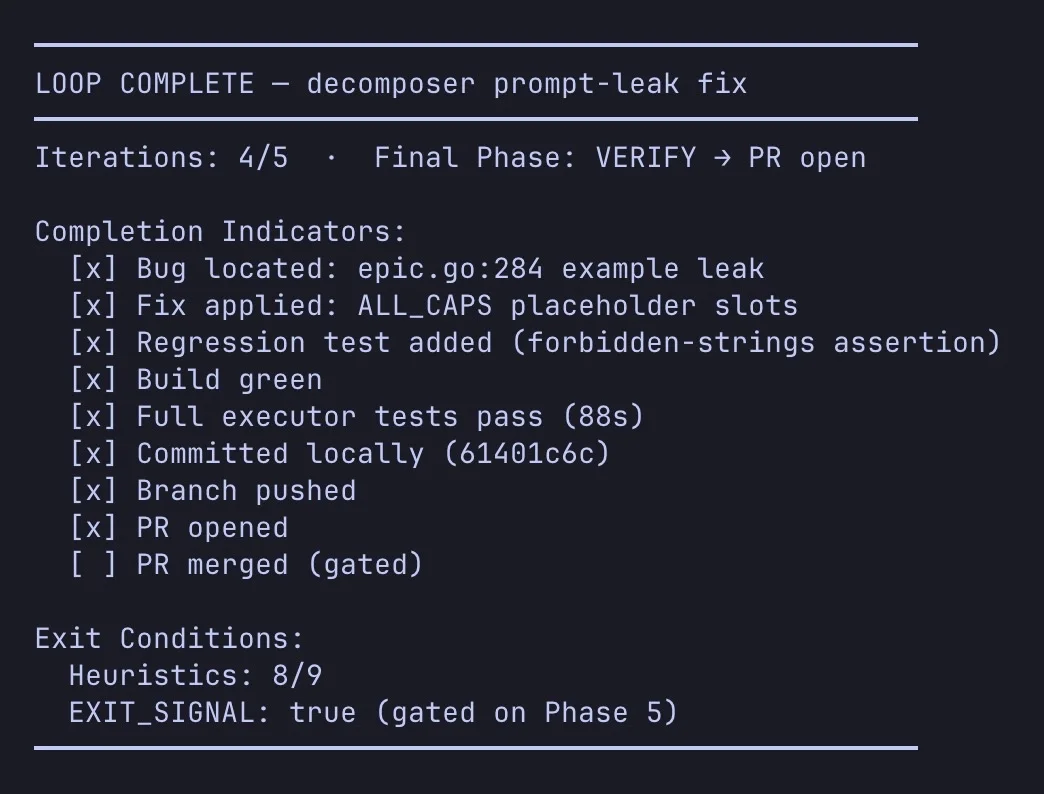
Navigator: Looping LLMs Into Convergent Senior‑Dev Performance
Loop is the whole game with LLMs. Navigator is a Claude Code plugin that loops research and execution until it actually converges, instead of bailing after one pass. I’ve been running it daily since 2025 – feels like a focused senior dev...
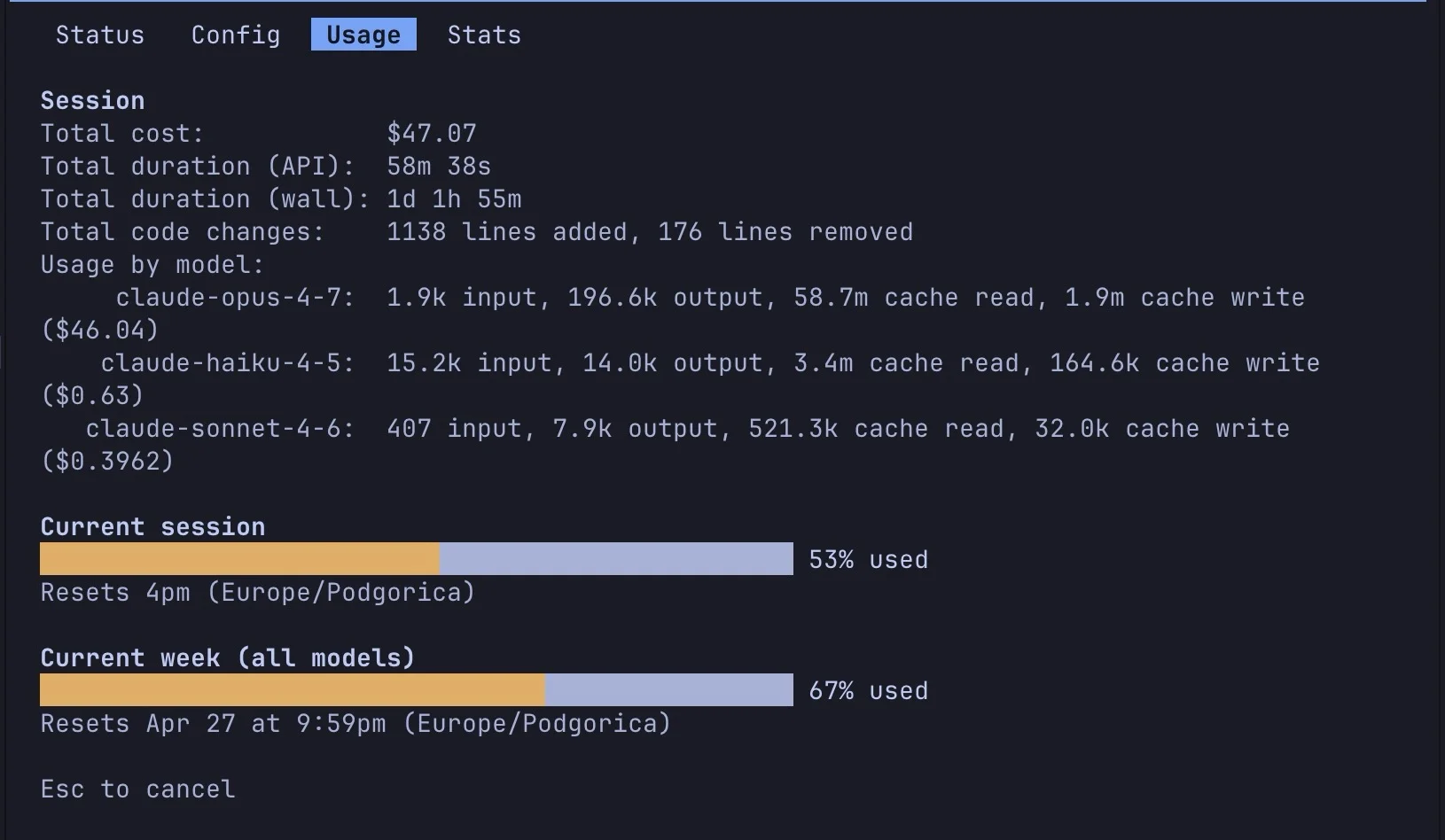
Claude's Usage Metrics Conflict Across Platforms, Causing Confusion
Claude’s limits and usage system is broken. I’m looking at 4 different usage sources — Terminal to Web — all showing different numbers for token usage, limits, model usage, and distribution. – Web says I’m out of weekly limit, but the account...
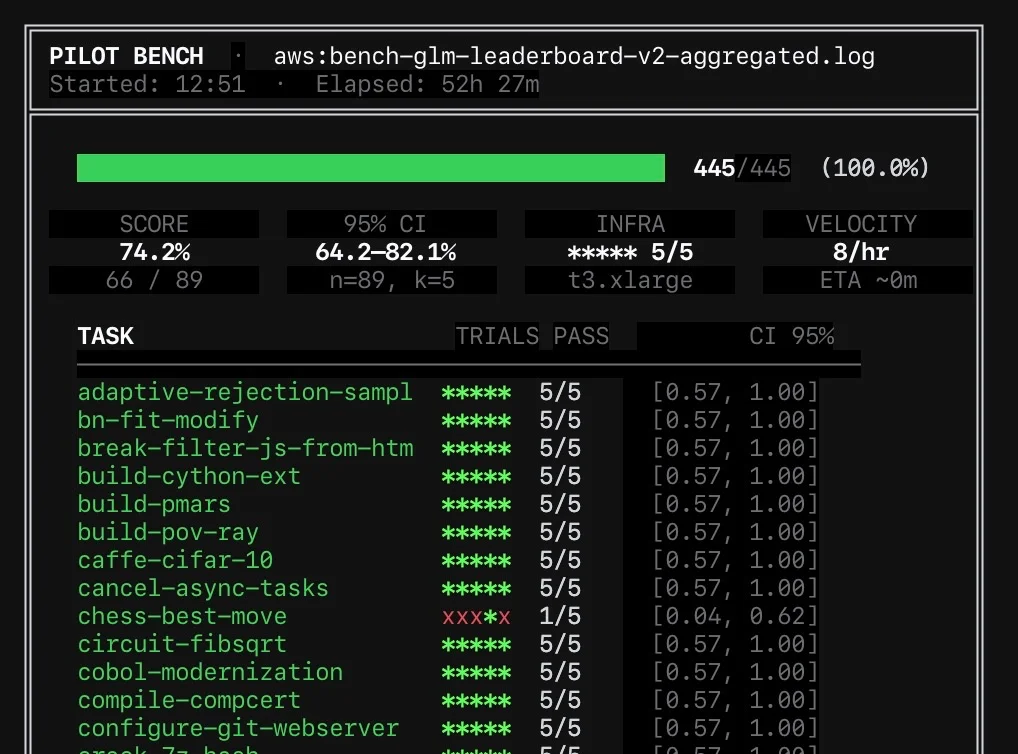
GLM 5.1 Hits 74.2%, Aiming for 12th Place
GLM 5.1 – Terminal Bench 2.0: 74.2% Harness: Pilot + ClaudeCode Autonomous run time: 52 hours Infra: AWS Likely landing around 12th on the leaderboard. Doing a few checks before we submit.
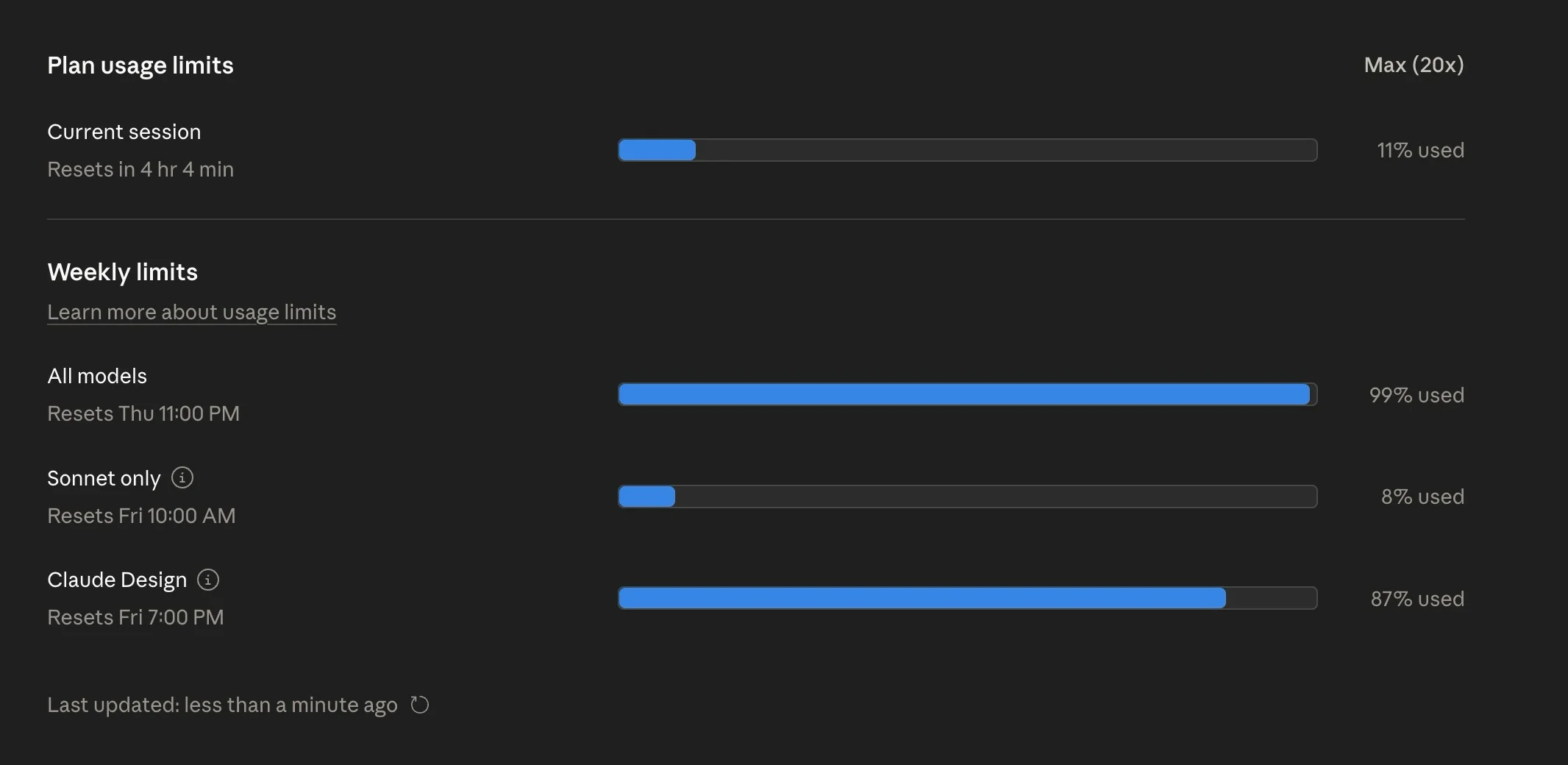
ClaudeCode Desktop Hits Weekly Limit After 3 Days
ClaudeCode desktop + Opus 4.7 + MAX plan 3rd day of usage – weekly limit hit. Looks like a bug 🐞 Tokens usage metrics: https://www.threads.com/@alekseipetrov.me/post/DXTqFbaDeh2?xmt=AQF0ZbjaxbwMsUY0e0v3hVyOCbRkX5pCCU6bLFjgOZU3Bw

TurboQuant Compresses LLM Cache to 3‑4 Bits, No Loss
TurboQuant from Google Research is wild. They basically found a way to compress LLM KV cache and vector search down to ~3–4 bits, with zero accuracy loss and even faster runtime than 32‑bit keys. https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/

Anthropic's Upcoming Autonomous Agent Mirrors Pilot
Anthropic’s new tool is on the horizon, pretty close to what the Pilot is - autonomous agent. Let’s see if it’s a good one ✌️
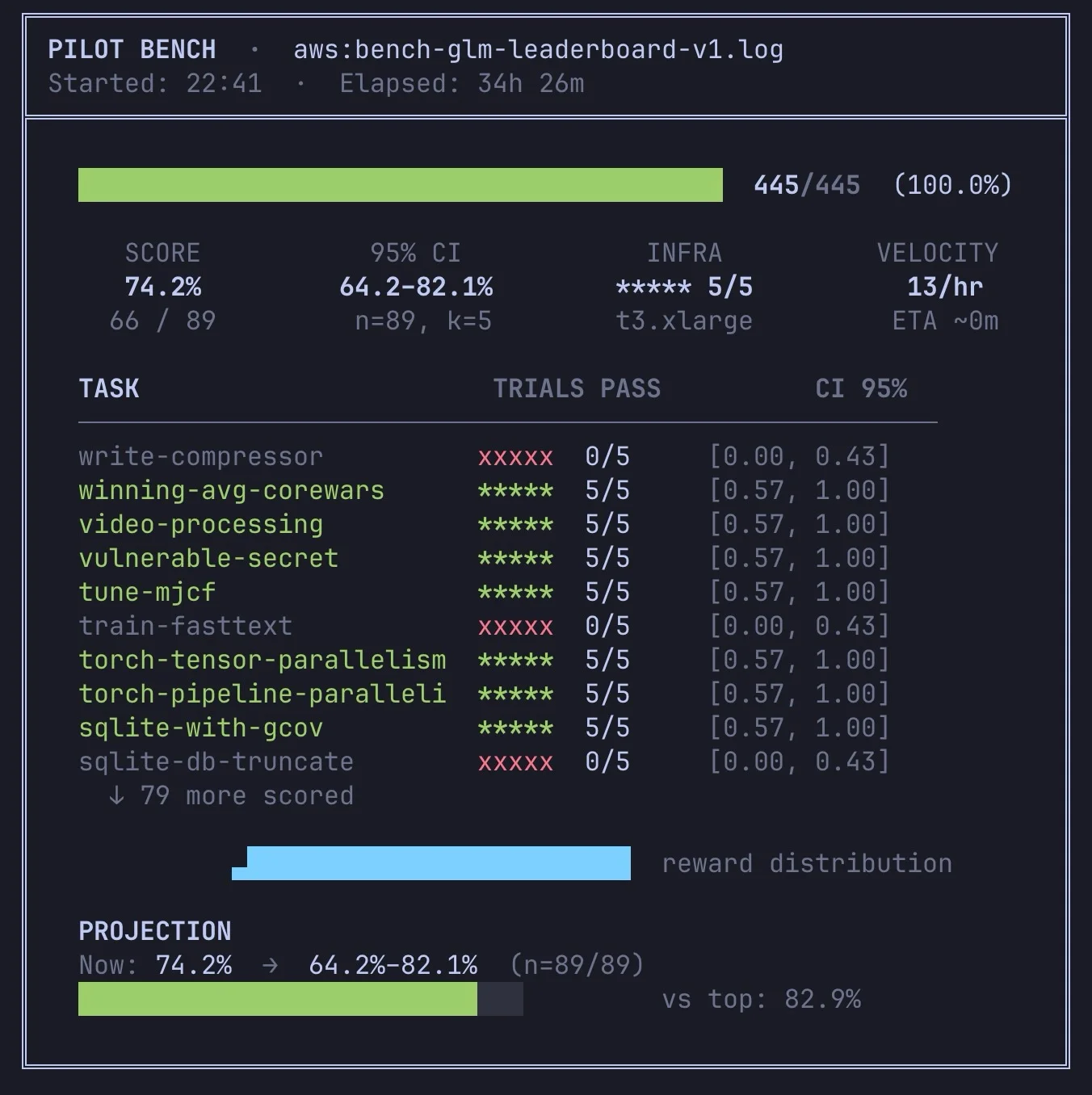
Pilot, ClaudeCode, GLM 5.1 Hit 74.2% Success
Pilot + ClaudeCode + GLM 5.1 74.2% success rate on Terminal Benchmark 2.0 full run. I have to check we didn't violate any rules 😁

Opus Plummets to 10th as Token Costs Rise
Opus dropped on the benchmark from 2nd to 10th place. Limits are tighter, tokens are more expensive now, this is how it all goes. Investment needs to be returned. Nice I don’t care, as my limits are cooked till the end...
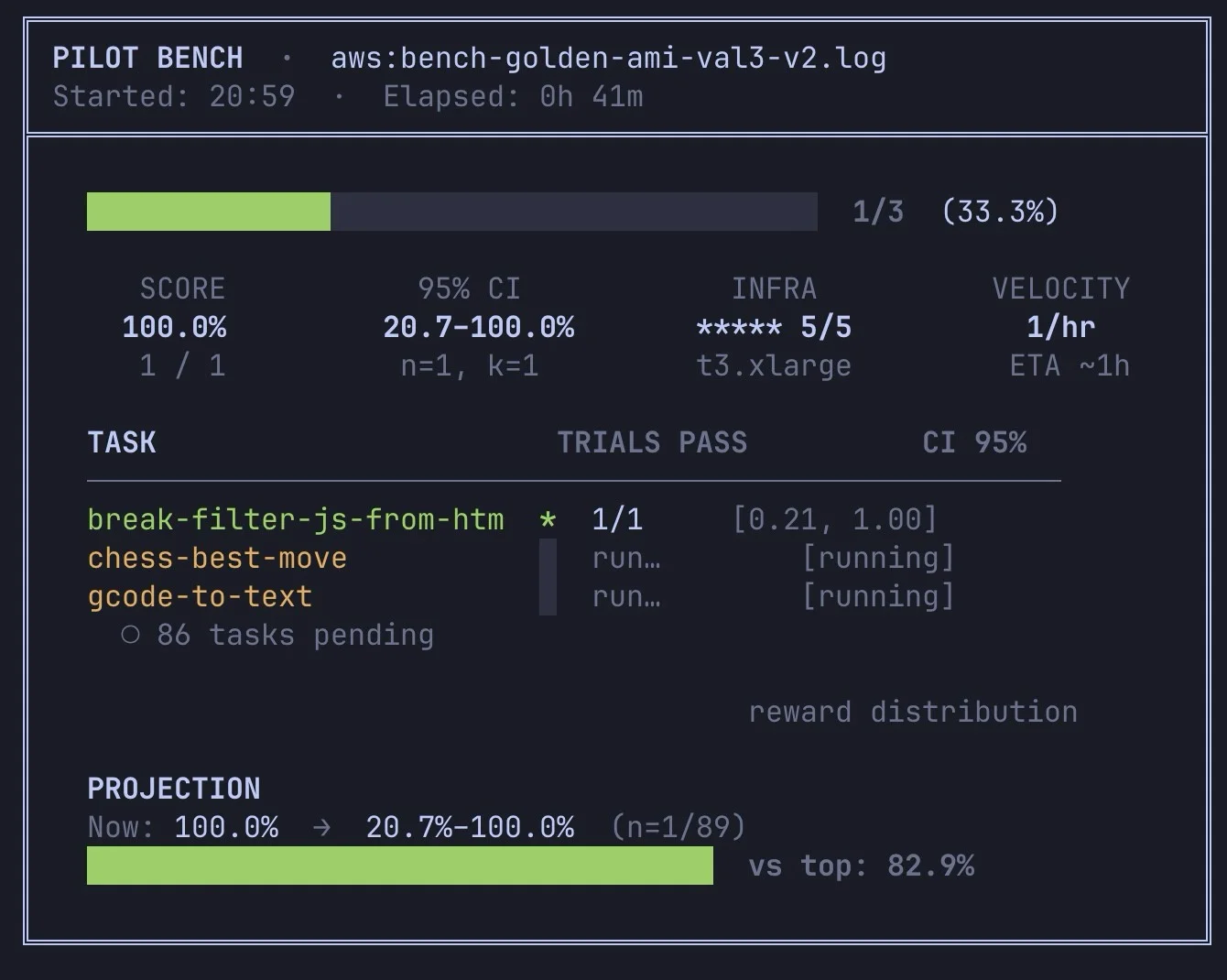
GLM Tackles Tough
GLM caught the “chess-best-move” trial on this test run — the nasty one. It’s been grinding on it for ~40 minutes already, ~20 left on the clock. Let’s see if it clears it; Opus only managed to pull it off a...
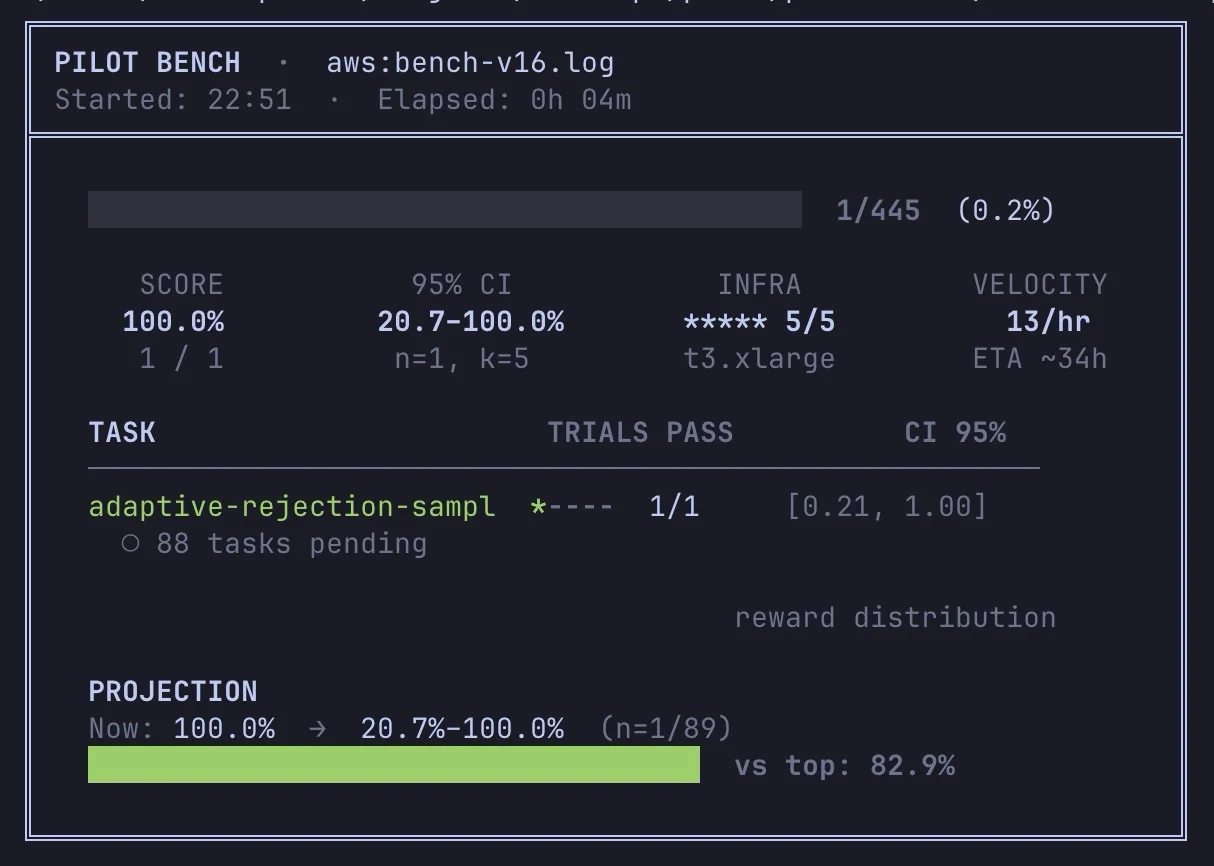
Reduced to One Worker, Now Runs Overnight
Scaled infra down to a single worker. Last run was burning tokens way too fast. Now it’s crawling… so this one runs overnight.

AI Agent Automates Dev Issue Resolution on AWS
AI Agent passing development issues, online. Join the Thread 🍿 AWS infra. ClaudeCode. Pilot. Hit the star: https://github.com/qf-studio/pilot
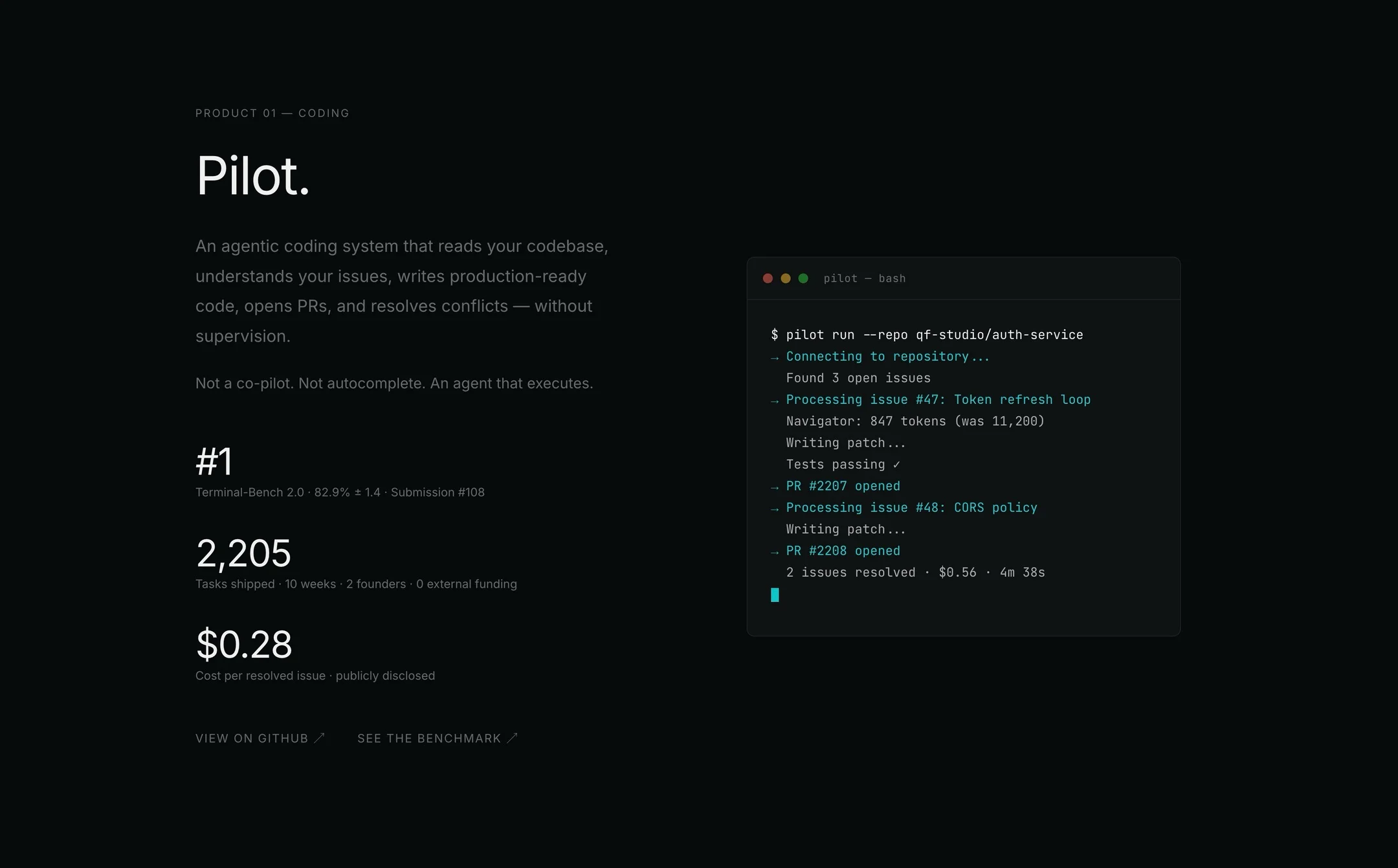
Design a Website with One AI
Website Design w/ Claude is so much fun. NO SKILLS NEEDED. Sonnet 4.6 made a quick sketch to refresh our website. Not bad for the single prompt 👏 Screenshot: Product section. Terminal animated.