

Avoid Re‑encoding Decoded Tokens for Stable RL Training
Most people training agentic LLMs with RL right now have a silently broken training loop and have no idea. Here's the trap: single-turn RL works beautifully. Clean curves, sane rewards, everything converges. Then you add tools so the model can act mid-rollout, and things get weird. Loss spikes for no reason. Eventually a shape-mismatch error. The culprit: every time you parse the model's output to detect a tool call, then re-tokenize the updated conversation for the next turn, you're rolling the dice. Usually the round-trip gives back the same tokens. Sometimes it doesn't and your gradient lands on a sequence the model never actually sampled. No crash. Just quietly wrong math and a useless gradient signal. The fix is one rule: never re-encode tokens you've decoded. Keep the sampled tokens in one buffer, never re-render them, and both failure modes disappear. That's Token-In, Token-Out done right. Our team just published a beautiful deep-dive on exactly this, including an audit across the major open-weights model families showing most chat templates already support it. Required reading if you're doing multi-turn RL 🤗🔥 https://t.co/zmx0EQl3jM

On‑Prem AI with Hugging Face Solves GPU Shortage
I believe on-prem and local AI - based on Hugging Face open-source models - will be an important answer to the GPU shortages this year (because they are cheaper, faster, safer than cloud APIs)! Great collaboration between Hugging Face &...

Unified, Affordable Storage for AI Models and Data
AI teams shouldn’t have to choose between expensive object storage and painful git workflows. @huggingface Storage is built for model weights, datasets, checkpoints and artifacts: - simple per-TB pricing - built-in CDN - Xet deduplication - private by default when needed Store your AI data where...
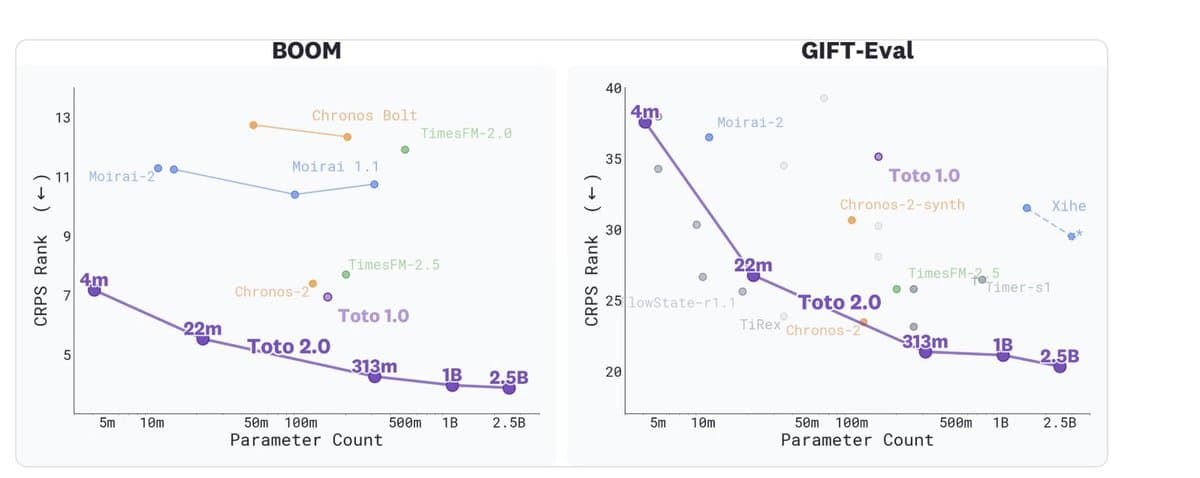
Scaling Laws Validate Performance Gains in Time‑Series Models
Are scaling laws finally working for time series foundation models? Today, @datadoghq is releasing Toto 2.0 weights in Apache 2.0 on @huggingface. It's a family of open-weights TSFMs from 4M to 2.5B parameters, where every size beats the last from a...

Prices Rise June 1; Grab Early‑Bird Deal Now
Reachy is mad, but RAM costs + tariffs are forcing our hand. Prices will go up on June 1st! Still at the early bird price until then though if you were looking for an excuse to get one now: https://t.co/veqPEwFIaP! https://t.co/UP45svdMr8

Create Reachy Mini App with 1920s Posh Voice
Can someone build the Reachy Mini app that lets it speak like Talkie from Alec Radford in a posh pre-1931 British voice? I want to hear a next-gen robot channeling the 1920s! Space: https://lnkd.in/eugi77Xv How to build a Reachy Mini...

Governments Should Adopt Open‑Source Sovereign AI
More governments and public agencies should use HF and open-source AI in general. Let’s go sovereign AI!
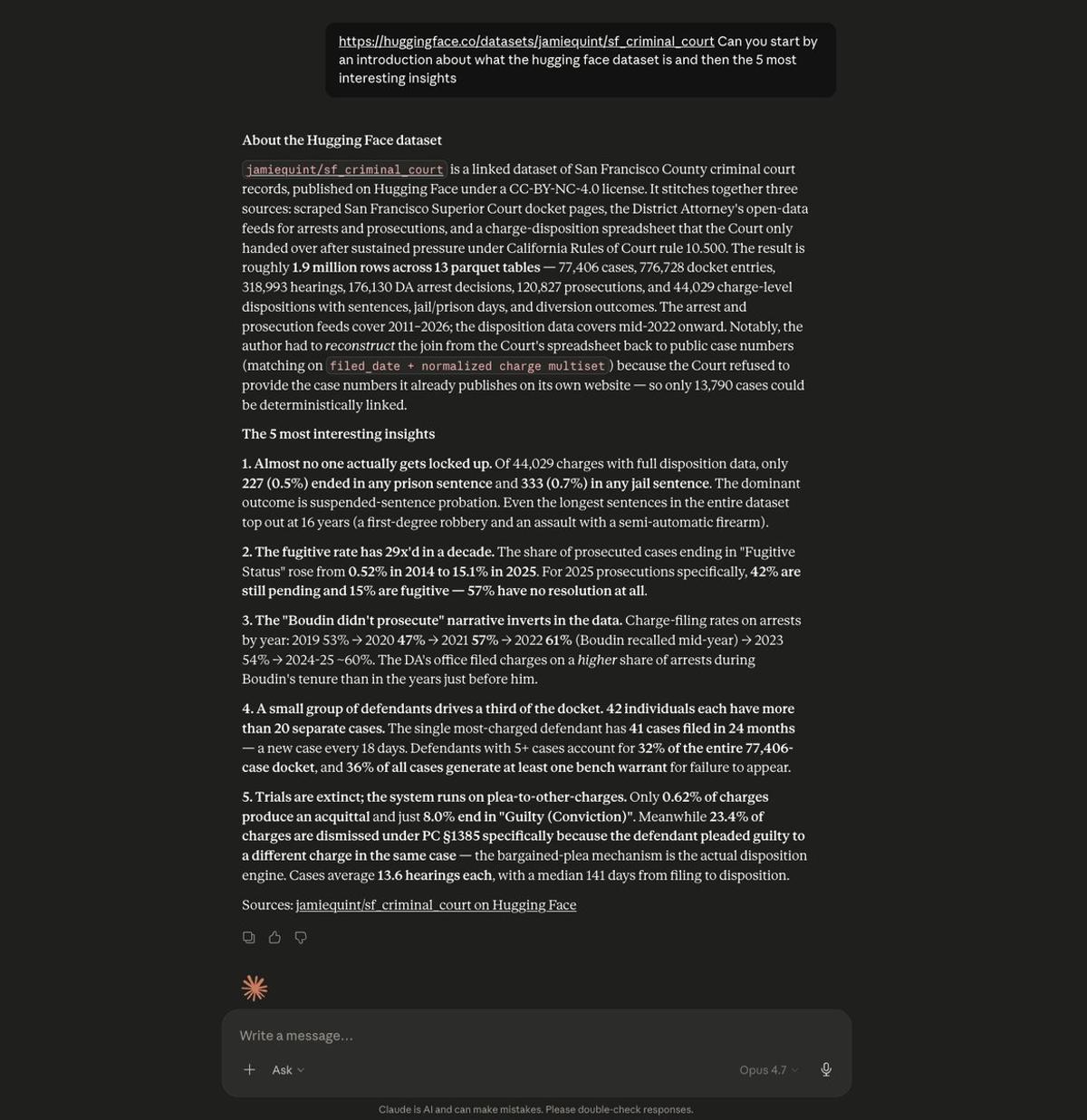
Share Datasets on Hugging Face to Unlock Collective Insights
By sharing datasets on @huggingface, you help agents being able to analyze them, giving everyone the ability to make sense of complex data. For example, this is some of the insights I uncovered from @jamiequint's fascinating data: https://t.co/PW4GH7Uxna What other...

AI Labs Use Web Distillation, Then Block Competition
I think the expression is “pulling the ladder”! All labs trained their models by distilling (at the very least distilling the web) which allowed them to become the fastest growing businesses in the history of humanity and now that they...

Distillation Deserves Fair‑use Protection for Open‑source AI
What people call "distillation" is a super common practice (you use other models to benchmark your model, to evaluate your inputs or to add a little bit to your datasets) that in my opinion should be covered by fair use...
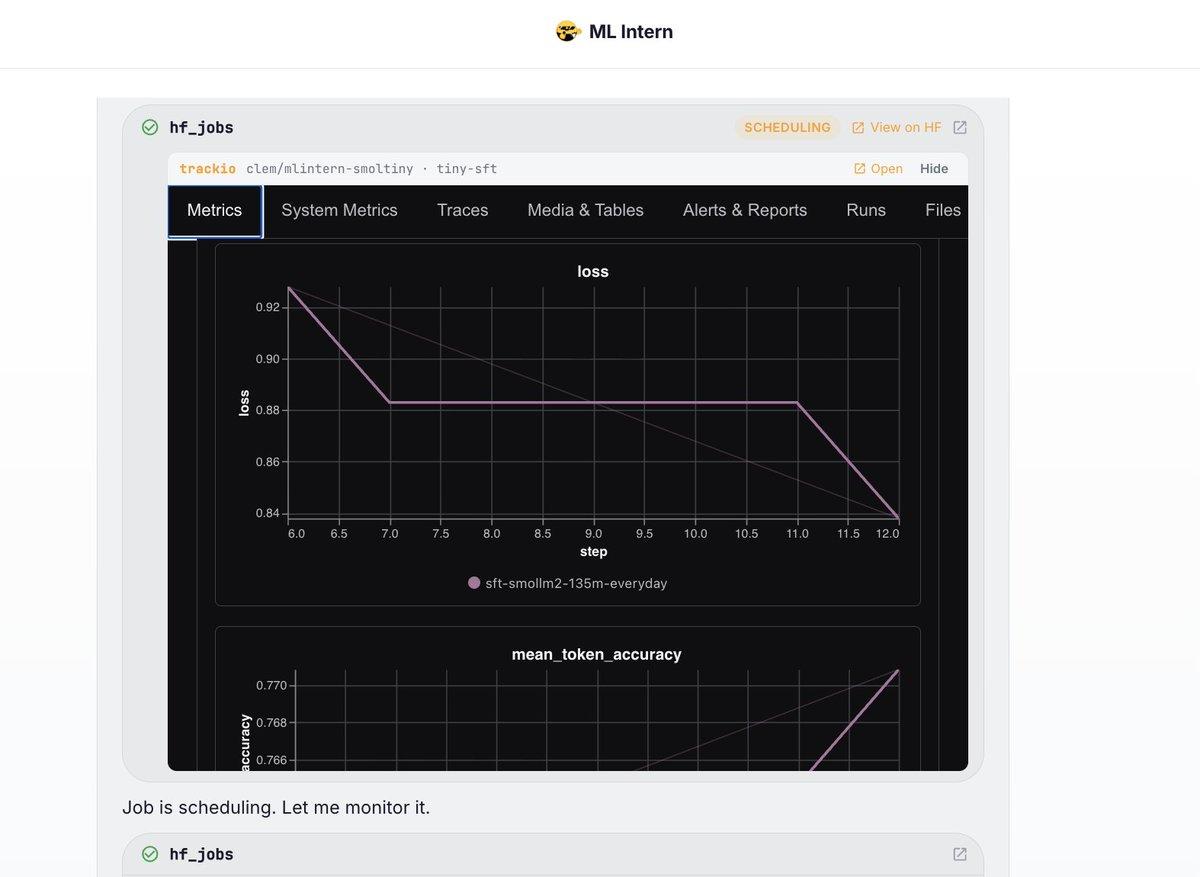
Real‑time Training Metrics Now Built Into ML Intern
Added native metric logging + @TrackioApp integration to ml intern so that you can follow every training run it kicks off in real time. Try it by asking "train a tiny model on a tiny dataset, find something super small/super...

Top 3 Trending HF Models: DeepSeek AI, OpenAI, Qwen
Top 3 trending models of the week on HF: DeepSeek AI , OpenAI & Qwen !

Llamacpp: Local, Free, Fast, Secure AI Future
llamacpp is the future of AI (local + free + fast + secure + powerful)!

Beyond Growth: Prioritizing Moats and Quality in AI
I'm always baffled how most investors seem to obsess over top revenue growth numbers these days and seem to take that as a universal prediction of future success in AI. Maybe we're finally starting to get back to more sanity...

Model Races to #1 on Hugging Face in Minutes
500+ likes in 28 mins. On their way to be the fastest model ever to get to #1 trending on HF! https://t.co/kxmwUEnwyY https://t.co/lvkbh2gXGi