
SSP Data
Data writer publishing deep dives and curating discussions around leading data/Big Data thinkers and resources.

Avoid AI’s ‘Vampiric Effect’—Prioritize Sleep Over Hype
AI is addictive; Steve Xegge calls it the «Vampiric Effect», as you won't go to sleep and keep trying to instruct your agents all night long. DHH said tough, there's no limited sales going on, AI will be around in a year or two still. So, there is no rush to stay up all night. Even more so, it's the worst version of AI today. Don't trade your sleep and health for shallow productivity, as I call it.

Open‑Source Data Stack Cuts Costs for Mid‑Scale Companies
Full open-source stack for running at low cost for mid-scale companies. Such as Dagster + DuckDB + dbt + Airbyte. https://www.ssp.sh/brain/open-data-stack

Digital Typewriter: Constraints Turn Into Productivity
The typewriter is back. Digital. Because constraints create focus. A device that only writes. That's not a limitation. That's productivity. https://www.ssp.sh/brain/distract-free-typewriter

Kimball’s Dimensional Modeling Still Guides Business Process Design
30 years later, Kimball's facts and dimensions and conformed dimensions transcend tooling. Dimensional modeling emphasizes identifying key business processes first, then progressively adding more. https://www.ssp.sh/brain/dimensional-modeling

AI Needs Human Judgment to Finish Quality Software
Models are not good at pushing back, saying no, saying: > Have you actually thought this through? There's not a lot of that going on. > Agents don't finish beautiful, ergonomic, desirable software. They just don't. That human finishing at...

30 Years Later, Inmon’s Data Warehouse Definition Still Holds
30+ years of proven patterns. Both still relevant. Inmon (1990): "A subject-oriented, integrated, time-variant, non-volatile collection for management decision-making." https://www.ssp.sh/brain/data-warehouse

Design Your Environment, Not Willpower, for Deep Work
How I get into deep work: 1. Journal before bed - write the 1-2 things for tomorrow 2. Go to bed early 3. Get up before distractions begin 4. Don't check the phone first thing 5. Change environments when stuck The key insight: deep work isn't...

Make AI Outputs Deterministic: Mark’s Practical Data Workflow
Most people vibe-code with AI agents and wonder why the output is unreliable. Mark spent weeks figuring out how to make it more deterministic. The AI space is moving fast, and everyone is figuring it out as they go. In this...

Rollback Mistakes Instantly with Data Lake Time Travel
Accidentally deleted something? Roll back. Time travel in data lake table formats enables versioning of big data. Access any historical version through timestamps or version numbers. https://www.ssp.sh/brain/time-travel
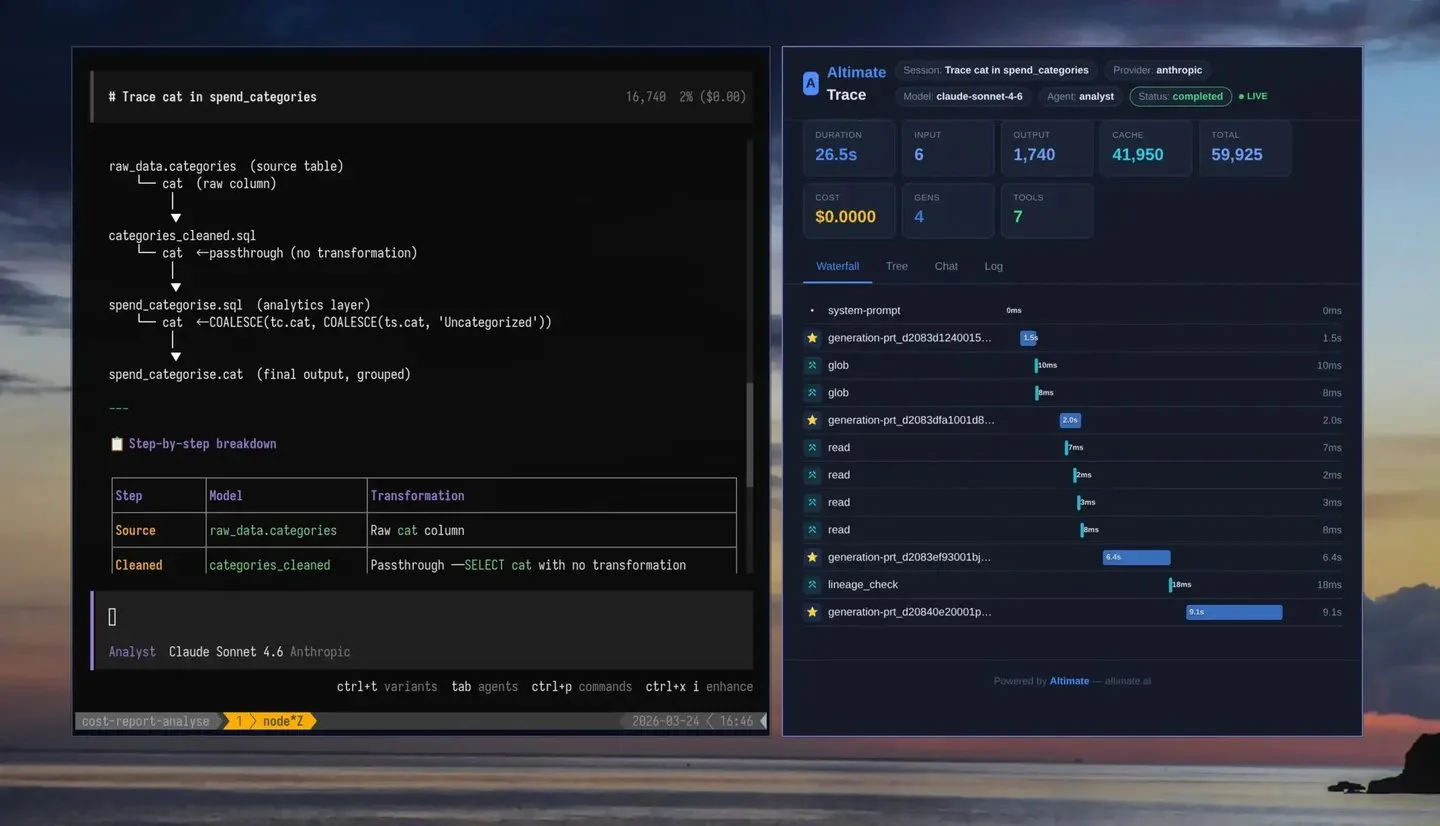
Altimate-Code: Open‑Source Terminal Editor Boosts Data Engineering
Altimate-code: a new open-source code editor for data engineering based on opencode. Easter comes early for every developer this year. Altimate-code is an OSS agentic code editor that works in the terminal, based on the admired OpenCode AI editor, with...

Old Kindle Highlights Resurface to Fuel New Writing
Most highlights die in Kindle. Readwise brings them back and connects them. The power isn't in the capturing. It's in the resurfacing. Sometimes a highlight from two years ago connects perfectly to what you're writing today. https://www.ssp.sh/brain/readwise

ELT Dominates: Load Fast, Transform In‑warehouse Layers
ETL (Extract, Transform, Load): Transform before loading into the warehouse ELT (Extract, Load, Transform): Load first, transform inside the warehouse The shift to ELT happened because cloud warehouses became cheap and powerful enough to do transformations. Why pay for a separate ETL server...

Dagster: Asset‑First Orchestration Over Task‑Centric Pipelines
Dagster has a steep learning curve but a payoff. It is Vim for orchestration. The mental model shift: Dagster thinks in assets, not tasks. You define what data should exist, not what steps to run. The engine figures out dependencies and...

Universal Semantic Layer Needed for Multi-Tool Data Access
The semantic layer isn't new. SAP BusinessObjects had one in 1991. What's new is the need for a universal semantic layer that works across BI tools, notebooks, and applications. When you only had one BI tool, that tool's semantic layer was enough....
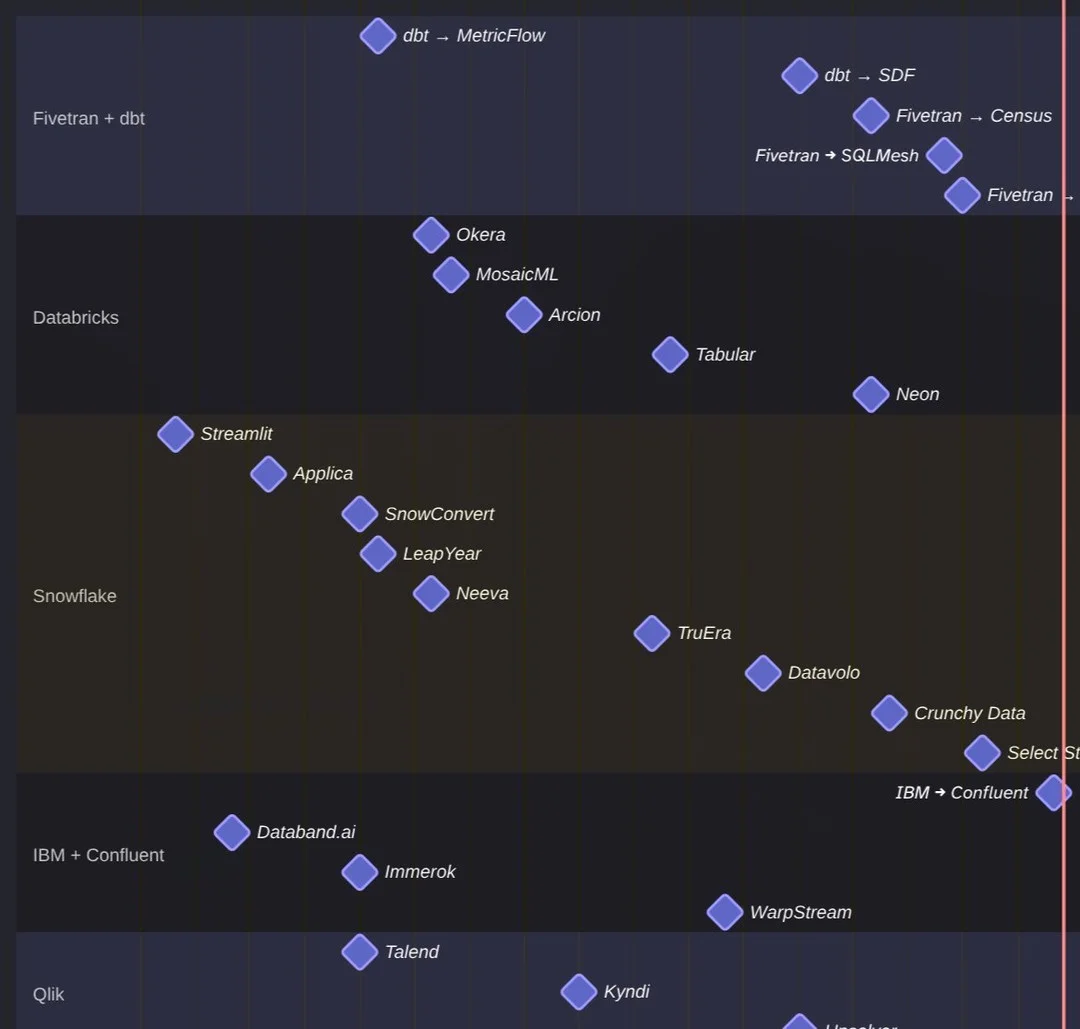
IBM Joins Data Platform Race with Confluent Acquisition
With the latest acquisition of Confluent by IBM, they follow up on the Fivetran, Databricks, and Snowflake stack. Or what do you think? With the latest acquisition in data engineering, it's a race of who gets the most complete data platform...

Orchestration Turns Data Stack Flexibility Into Cohesion
The Modern Data Stack promised best-of-breed tools that work together seamlessly. The paradox: the more tools you pick, the more integration work you create. One perspective I find helpful: Orchestration as the connective tissue. A good orchestrator doesn't just schedule jobs -...

Pick Data Modeling Pattern Based on Needs, Not One‑Size
I think about data modeling patterns in four main categories: 1. Dimensional modeling (Kimball) - optimized for queries 2. Data Vault - optimized for auditability and change 3. One Big Table - optimized for simplicity 4. Medallion Architecture - optimized for incremental refinement No pattern...

Writing Is Thinking: Build Ideas Through Continuous Notes
The key principle from "How to Take Smart Notes": writing is not the outcome of thinking. Writing is the medium in which thinking occurs. When you write about an idea, you're not recording a thought - you're developing it. This is why...

Effective Data Lineage Connects SQL and Python Pipelines
Data lineage traces your data's journey from source to destination. Where did this number come from? What would break if I changed this table? Who's using this data? Good lineage answers these questions. Bad lineage makes you grep through code. Tools like dbt...
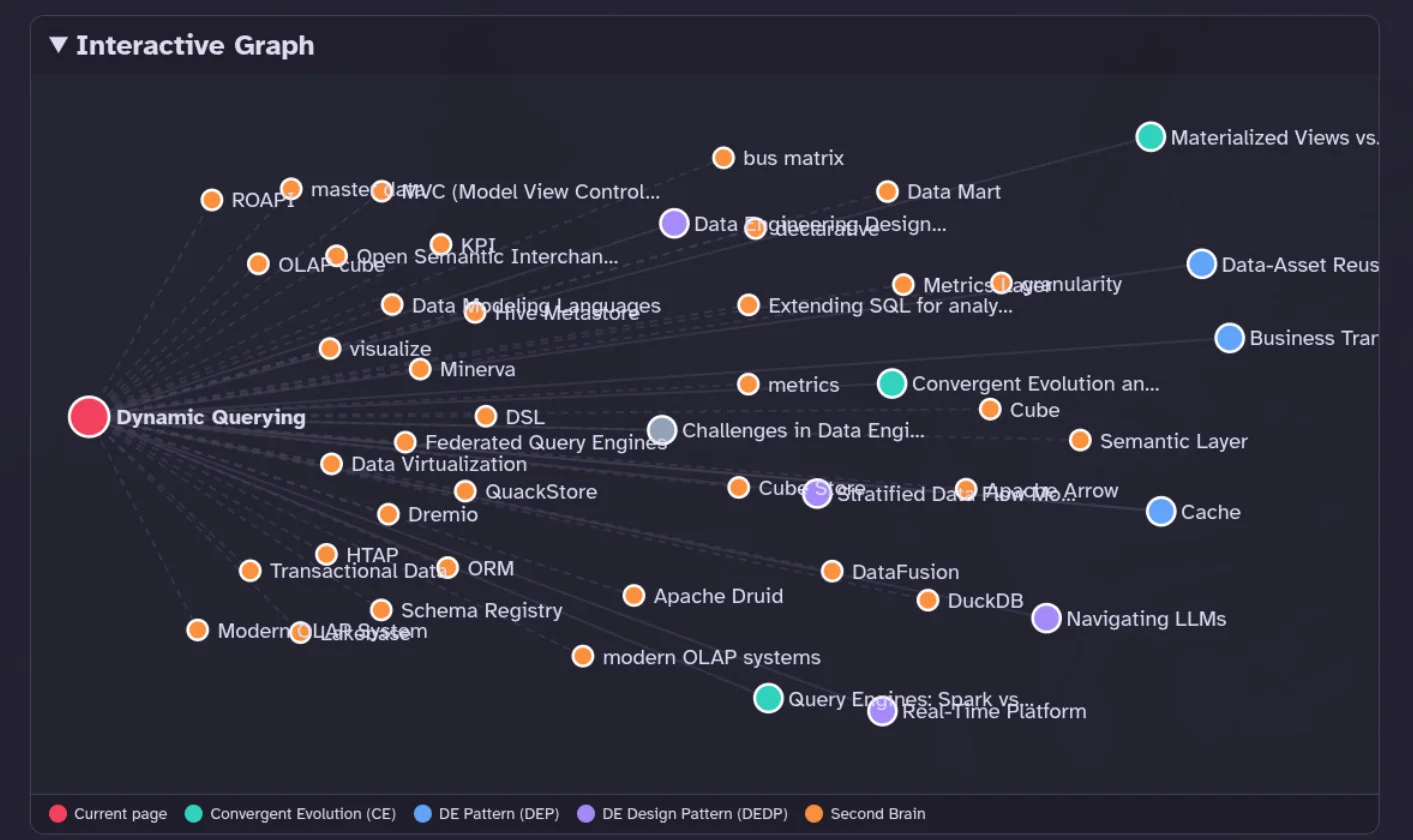
Dynamic Query Pattern Enables Immediate, Flexible Data Retrieval
Big news, I added a new design pattern chapter, called «Dynamic Query Design Pattern». This design pattern problem statement goes like this: 1. Provide immediate answers 2. How you model it matters 3. Dumping everything into the lake is painful The core challenge is enabling...

Validate Data at Source: Shift Left for Quality
"Shift left" comes from software engineering - finding bugs earlier in the development process. In data, shifting left means: validate data at the source, not after it breaks your dashboard. Instead of hoping bad data doesn't show up in your warehouse, you...

SQLMesh Adds Semantic SQL, Auto-Dialect Translation for Dbt
SQLMesh takes dbt's concept and adds semantic understanding of SQL. It parses SQL statements, translates between dialects automatically, and offers compile-time validation. Built by Tobiko Data (now Fivetran). If you're starting fresh, it deserves serious consideration. https://www.ssp.sh/brain/sqlmesh

AI Erases Craftsmanship and Personal Connection in Creation
Is craftsmanship gone with AI? You can vibe code something on demand, but you have no attachment to what it's built, so how are you gonna sell or rave about something you don't even have any connection to? No hardship,...

CLI‑first Analytics: DuckDB, MotherDuck, and Rill Empower Agents
CLI-first is eating development. Email, calendar—they all have CLIs now. Why not your business metrics? For data/analytics engineers building with agents: DuckDB + MotherDuck + Rill give you an agentfriendly, #localfirst frontend—exact context via SQL and YAML. https://www.rilldata.com/blog/building-an-agent-friendly-local-first-analytics-stack-with-motherduck-and-rill

Think in Assets, Not Jobs, for Data Reliability
Dagster's key innovation is software-defined assets. Instead of: "Run this job on a schedule" You declare: "I need this table to exist, here's how to build it" The difference is subtle but profound. Assets have identities, dependencies, and history. Jobs are just tasks. When...

Template‑Based Pipelines Offer Flexibility, Demand SQL Skill
I spent years working with data warehouse automation tools before the modern data stack existed. The biggest lesson? There are two approaches to generating pipelines: Parametric - you define parameters, the tool generates SQL Template-based - you write SQL templates with variables Most modern...

DuckDB Lets You Query 10GB Parquet Locally, Ditch Clusters
There's a moment in every data engineer's career when they discover they can query a 10GB Parquet file on their laptop in seconds. That's the DuckDB moment. It changes how you think about what requires a cluster and what doesn't. Spoiler: most...

Treat Data as Assets, Not Just Jobs.
Data Product: why do we need this data? Data Asset: what is this data and how do we maintain it? I've found the most practical definition of data products comes from Dagster's software-defined assets. Each asset has a clear definition, dependencies, and...

Managed Iceberg Lets Providers Own the Metadata Control Plane
Why are hyperscalers racing to offer managed Iceberg? Because whoever controls the catalog controls the ecosystem. If your tables are in a managed Iceberg service, you can query them from any engine - Spark, Trino, DuckDB, whatever. But your metadata stays with...
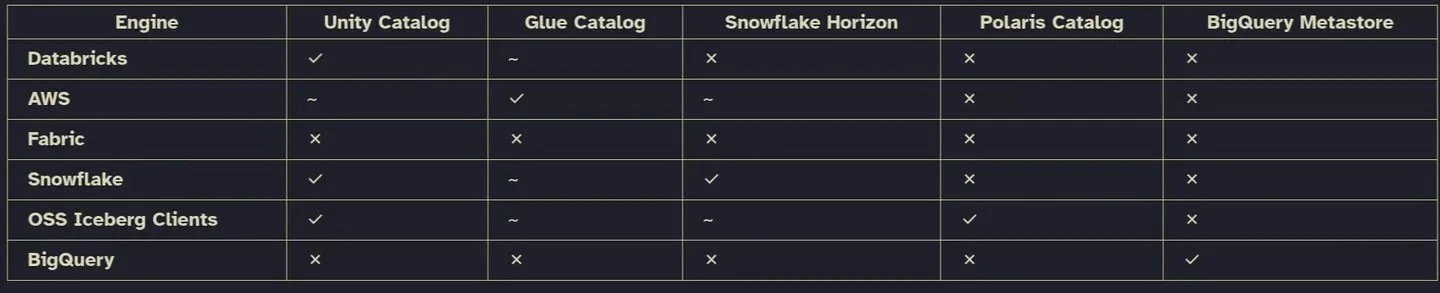
Choosing Optional Catalogs for Open Table Formats
Are we still using table catalogs for open table formats? Haven't heard too much lately. I like OTFs, but making it non-optional to have a catalog isn't great. That's why I like prefer the option to use one without. But if you...

Exploring Emerging Git‑Style Tools for Data Management
Git for data is still underexplored, and it is an area that is changing so fast. That's why we look at actual tools/features that showcase how to apply a Git-like workflow for data. I compared Git-like tools for data I could...

Flowrs: New TUI for Managing Airflow Jobs
A TUI for managing Airflow jobs? Something like k9s? Flowrs seems to be just that - haven't tried yet, but looks really cool. Will try next time I have to use Airflow :) https://github.com/jvanbuel/flowrs

Skip Semantic Layer Early; Use Native Metrics First
Controversial opinion: don't start with a semantic layer. A semantic layer makes sense when: - You have multiple consumers (BI, notebooks, apps) - KPIs are defined inconsistently across teams - You need a universal API for metrics If you're early stage with one BI tool,...

Rust Powers Python's Data Engineering, Not Replaces It
Will Rust kill Python in data engineering? No. But it has already consumed much of the JavaScript tooling ecosystem. And it's quietly doing the same in data. The pattern: Python remains the interface, Rust becomes the engine. Polars, DataFusion, DuckDB's internals - all Rust...

Browse S3 Files Locally in One Fast Command
I quickly recorded how easily and conveniently it is to browse S3 files locally with a single command, blazingly fast. Even preview works with DuckDB integration. https://youtu.be/cimUvBd_9Ns

Use Exponential Backoff with Jitter for Effective Retries
Not all retries are created equal. Immediate retry: usually fails again Exponential backoff: gives systems time to recover Exponential backoff with jitter: prevents thundering herd Most orchestrators have this built in. But you need to understand what's happening or you'll wonder why your retries...

Semantic Layer: Serve Data Like a Menu, Hide Complexity
The semantic layer is like a restaurant menu: you know what you're ordering, but not how it's made. This analogy comes from Maxime Beauchemin and I think it's perfect. Users shouldn't need to understand your star schema to calculate revenue. They should...

Pivot Tables: Business Data’s Everlasting REPL
Hot take: Pivot tables are the REPL for business data. Just like programmers use REPLs to quickly test code, business users use pivot tables to quickly test hypotheses about their data. Drag a field. See a result. Adjust. Repeat. This feedback loop is...

Integrate Data Quality Assertions Directly Into Orchestration
I see data contracts and data quality as overlapping but different: Data contracts: what is the data and how do we enforce it Data products: why do we need this data In practice, I'd argue for asset-based data quality assertions. Every time a...

Three Red Flags of Non‑Idempotent Data Pipelines
From Zach Wilson, three signs your pipeline isn't idempotent: 1. It uses INSERT INTO instead of INSERT OVERWRITE or MERGE 2. Date filters have "date > start" but no "date < end" - this causes exponential backfill costs 3. Source tables are always...

Data Engineering: Experience Beats Tutorials Through Pattern Recognition
After years in data engineering, I've realized the job is mostly pattern recognition. You see a problem. You recognize it as a variant of a problem you've solved before. You apply a known solution with modifications. This is why experience matters more...

StarRocks Delivers DWH‑Level Joins on Lakehouse Natively
Today, I dig into the details of StarRocks and how it is gaining traction in the real-time database world. DWH-like joins and fast retrieval from a #Lakehouse-native data architecture, without additional data engineering work to persist and ingest data. https://www.ssp.sh/blog/starrocks-lakehouse-native-joins/

Modern Tools Reshape Kimball’s Data Modeling Techniques
What's changed since Kimball wrote The Data Warehouse Toolkit: 1. Surrogate keys are less necessary with better databases 2. Denormalization for performance matters less with modern engines 3. Snapshotting dimensions beats complex SCD2 logic 4. Collaboration requirements mean looser conformance Kimball's principles still matter. But...