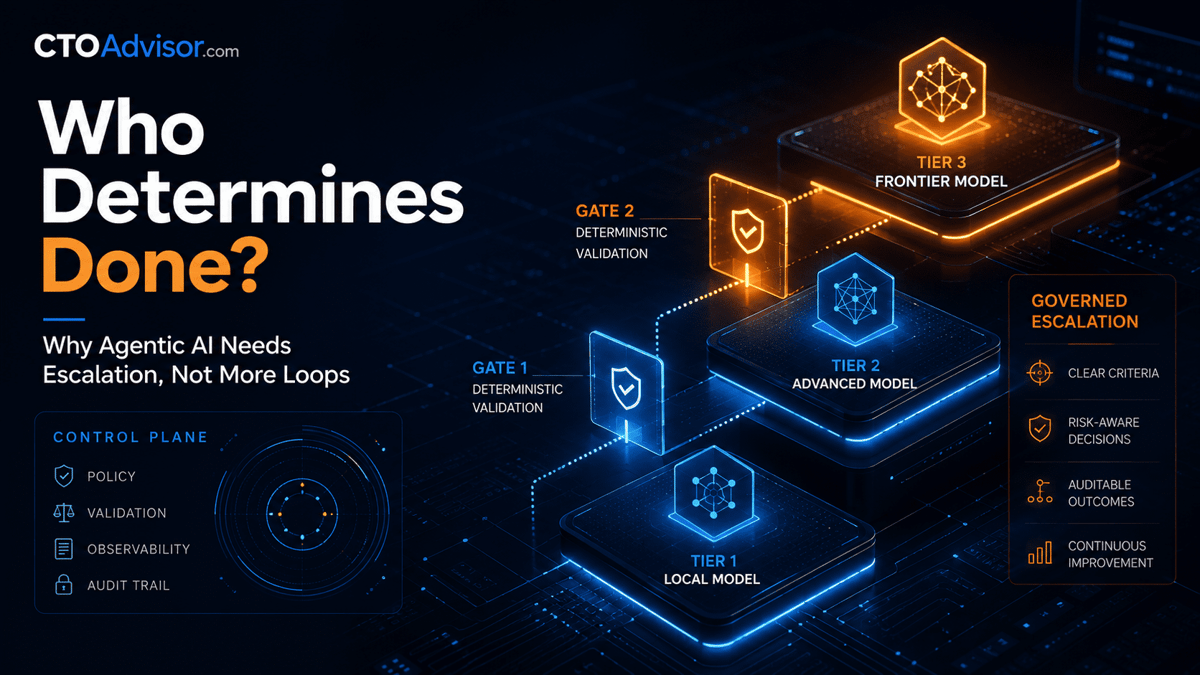
Who Determines Done? Why Agentic AI Needs Escalation, Not More Loops
The author ran a four‑day experiment on a DGX Spark, testing ten milestones across six local model configurations and frontier models (o3, gpt‑5.5). By comparing a single‑attempt local model, same‑tier repair loops, and a three‑tier escalation chain, he discovered that deterministic loops add no value, while an escalation policy dramatically improves success rates. The final architecture—local model → o3 → gpt‑5.5, gated by deterministic validators—achieved a 75% pass rate at an average cost of $0.13 per task, versus a $4,000 hardware outlay and $4.60 API spend.

Who Controls the Loop? A Requirements Document for Local-First Agentic AI
The author released a pre‑experiment requirements document to test loop‑control architectures for local‑first, agentic AI on a DGX Spark system using OpenClaw. The core hypothesis is that local models serve well as workers but are unreliable as governors, prompting a...

AI TRiSM Readiness Assessment
The AI TRiSM Readiness Assessment is a practical companion to the CTO Advisor Field Guide, helping enterprises verify that AI governance policies have been translated into operating reality. It evaluates four readiness levels—from aspirational language to auditable controls—across seven domains such...

Closing the Loop: Google Just Validated Deterministic Code in the Loop
Google’s AI and Infrastructure team announced a multi‑agent system that cut the time to migrate production models from TensorFlow to JAX by six times. The architecture combines a deterministic Planner that builds a static dependency graph, an Orchestrator that chunks...

Operationalizing AI TRiSM: A CTO Advisor Field Guide
The CTO Advisor’s field guide translates Gartner’s AI TRiSM framework into concrete architecture, controls, and operating decisions for enterprises. It introduces the Decision Authority Placement Model (DAPM), the 4+1 Layer AI Infrastructure, Layer 2C Reasoning Plane, Evidence Chain, and other patterns to...
The Industry Is Watching GPU Prices. Google Just Moved the Fight to the Judgment Layer.
Google Cloud Next didn’t unveil brand‑new primitives; instead it repackaged existing services into new judgment layers—Knowledge Catalog (Layer 1C) and the Agent Development Kit (Layer 2C). The event highlighted a strategic shift from competing on GPU pricing to building lock‑in through governance,...
Auditable Authority: When AI Can Advise, and Who Should Decide
Enterprises deploying large language models often feel a hidden unease because AI‑generated output looks flawless while the organization’s tacit judgment, voice, and risk posture disappear. The paper argues that the core problem is unplaced authority: AI recommendations are mistaken for...

I Just Wanted Endpoints
The author highlights a missing orchestration layer—dubbed Layer 2C or the Reasoning Plane—between AI hardware and inference endpoints. On a single NVIDIA DGX Spark, they manually juggle vLLM and Ollama containers, deciding model placement, memory swaps, and runtime selection. At cloud...

Layer 1A Is Table Stakes. The Real AI Infrastructure Question Is Above It.
Enterprises migrating AI workloads discover that the real lock‑in lies not in storage (Layer 1A) but in the reasoning and context layers above it, which the author calls “borrowed judgment.” Google announced a Knowledge Catalog that productizes this non‑portable layer, using...

One Problem, Five Frameworks: Why Enterprise AI Stalls — and How to Fix It
Enterprise AI projects are stalling not because of model selection but due to unclear responsibility for autonomous decisions. Keith Townsend’s revised 4+1 Enterprise AI Field Manual bundles five interrelated frameworks—4+1 Infrastructure Model, AI Factory Economics, Decision Authority Placement Model, Intra‑Loop...

Case Study: Decision Authority Drift in an AI-Assisted Writing Workflow
The case study details a failure mode called Decision Authority Drift in an AI‑assisted writing workflow. As the underlying language model became more capable, it silently assumed control over tasks—such as tone and structure—that were originally reserved for human authors....

You Know What’s Dumb? Using AI When It’s Not Needed.
Enterprises are increasingly applying AI to tasks that don’t need it, leading to inflated costs and fragile systems. The article cites OCR workflows, microservice over‑engineering, and a tax‑return case where calling a public LLM for every decision would cost millions...

Why Most AI Architectures Collapse Under Governance
The article explains why most AI architectures crumble when governance is imposed. Decision logic is dispersed across prompts, code, tool definitions, and the model, leaving no single control point. Attempts to add guardrails turn into patches because the system was...

AI Doesn’t Fail in the Demo – It Fails the First Time You Have to Trust It
Enterprises can quickly build AI agents with frameworks like NVIDIA NeMo, but demos mask a deeper problem. While models now meet capability thresholds, production failures stem from a lack of programmatic control and governance. The article argues that trust requires a...

544 Enterprises. One Number That Matters: 22.8%
HyperFRAME’s 1H 2026 enterprise AI survey of 544 firms shows only 22.8 % of AI/ML projects launched in the past year are successfully deployed and meeting ROI, leaving a 77 % execution gap. The data, released openly without gating, highlights that most failures...