

LLMs Will Evolve From Plain Text to Interactive HTML
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc. More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage: 1) raw text (hard/effortful to read) 2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default 3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default ...4,5,6,... n) interactive neural videos/simulations Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral https://t.co/z21CP5iQfu There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen. TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.

LLMs Unlock Code‑Free Apps, Natural Installations, Knowledge‑Base Power
Fireside chat at Sequoia Ascent 2026 from a ~week ago. Some highlights: The first theme I tried to push on is that LLMs are about a lot more than just speeding up what existed before (e.g. coding). Three examples of new...

Outdated Free AI Models Skew Public Perception of Cap
Judging by my tl there is a growing gap in understanding of AI capability. The first issue I think is around recency and tier of use. I think a lot of people tried the free tier of ChatGPT somewhere last...

AI Empowers Citizens to Make Governments Transparent and Accountable
Something I've been thinking about - I am bullish on people (empowered by AI) increasing the visibility, legibility and accountability of their governments. Historically, it is the governments that act to make society legible (e.g. "Seeing like a state" is the...

LLMs Turn Personal Wikis Into Dynamic Knowledge Bases
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more...

AI Research Needs Asynchronous, Community‑scale Collaboration Platform
The next step for autoresearch is that it has to be asynchronously massively collaborative for agents (think: SETI@home style). The goal is not to emulate a single PhD student, it's to emulate a research community of them. Current code synchronously grows...

Self‑Improving LLM Trainer Runs 5‑Minute Experiments Autonomously
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code,...

Memory Ops and Prompt Compaction Boost Continual Learning
There was a nice time where researchers talked about various ideas quite openly on twitter. (before they disappeared into the gold mines :)). My guess is that you can get quite far even in the current paradigm by introducing a number...

Multi‑agent NanoChat Experiments Fail to Remove Softcap
I had the same thought so I've been playing with it in nanochat. E.g. here's 8 agents (4 claude, 4 codex), with 1 GPU each running nanochat experiments (trying to delete logit softcap without regression). The TLDR is that it...

AI Coding Agents Suddenly Became Production‑ready This December
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks...

Legacy CLIs Empower AI Agents to Automate Everything
CLIs are super exciting precisely because they are a "legacy" technology, which means AI agents can natively and easily use them, combine them, interact with them via the entire terminal toolkit. E.g ask your Claude/Codex agent to install this new Polymarket...
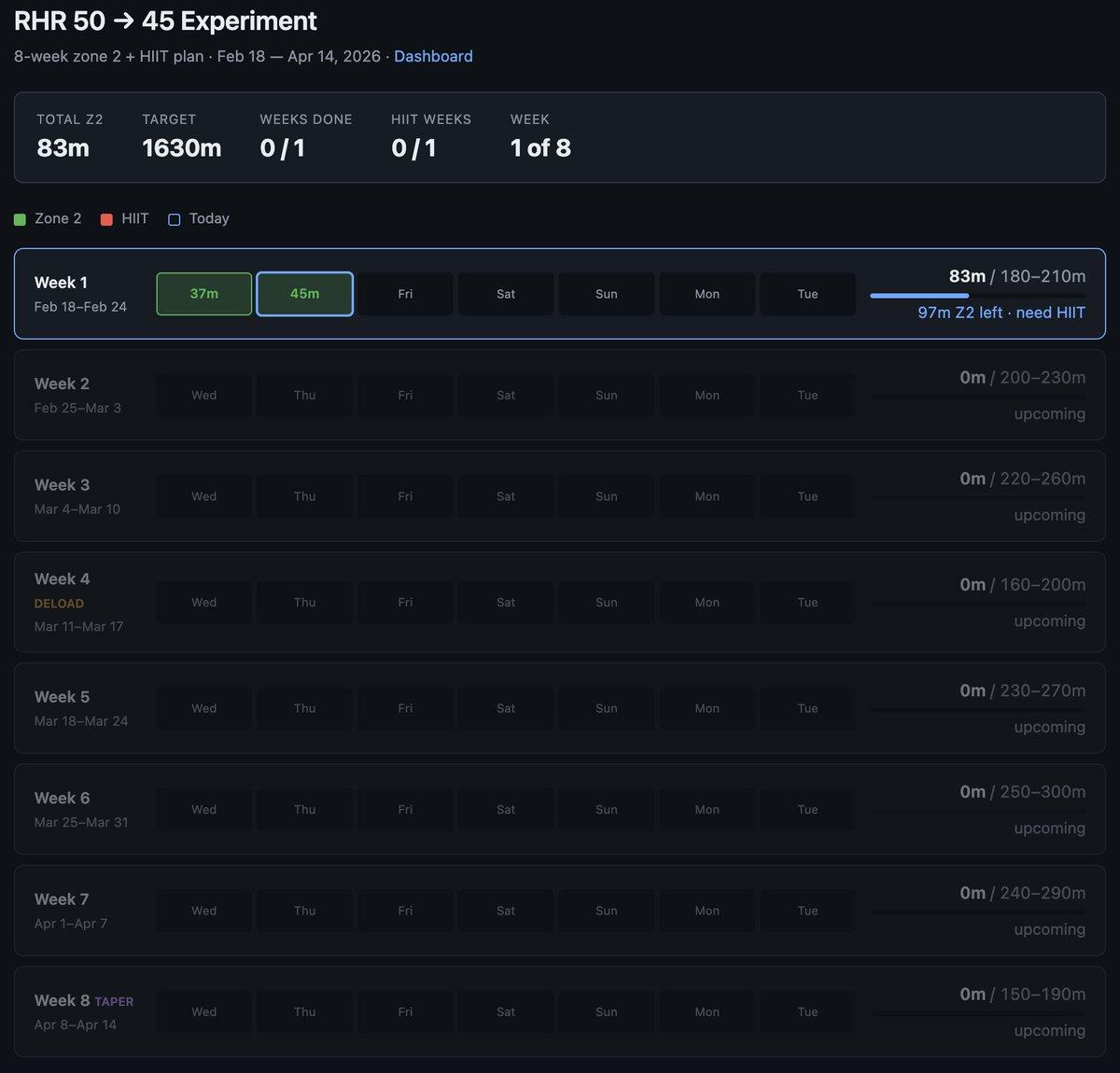
Bespoke Software Lets You Build Personal Health Dashboards
Very interested in what the coming era of highly bespoke software might look like. Example from this morning - I've become a bit loosy goosy with my cardio recently so I decided to do a more srs, regimented experiment to try...

LLMs Will Redefine Languages, Prompt Massive Code Rewrites
I think it must be a very interesting time to be in programming languages and formal methods because LLMs change the whole constraints landscape of software completely. Hints of this can already be seen, e.g. in the rising momentum behind...
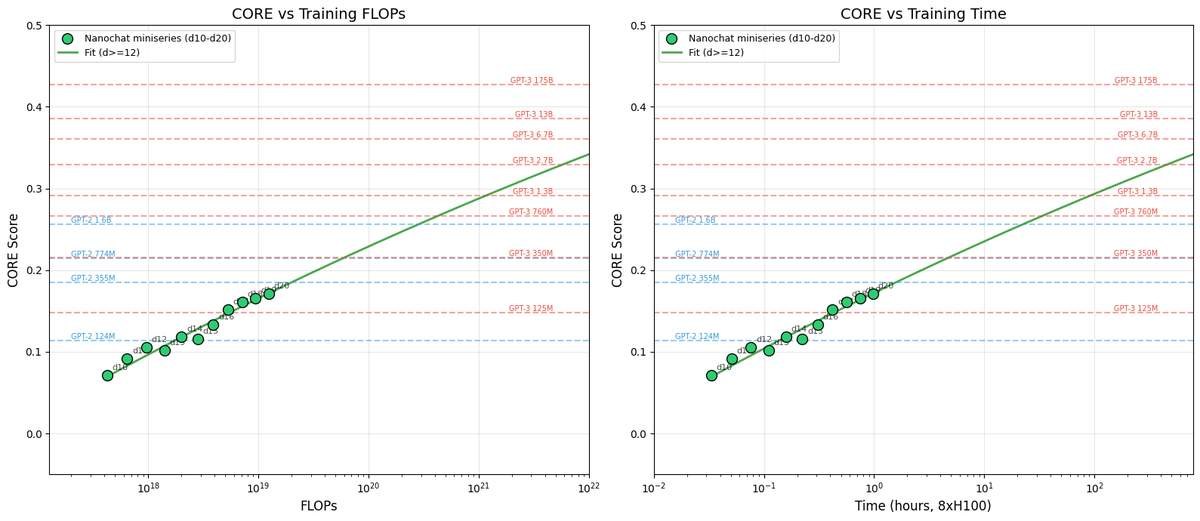
Think of LLMs as a Compute‑Dial Family
New post: nanochat miniseries v1 The correct way to think about LLMs is that you are not optimizing for a single specific model but for a family models controlled by a single dial (the compute you wish to spend) to achieve...

Programmers Must Master AI Agent Stack to Stay Relevant
I've never felt this much behind as a programmer. The profession is being dramatically refactored as the bits contributed by the programmer are increasingly sparse and between. I have a sense that I could be 10X more powerful if I...