

Humans Savor “Food for Thought”—LLMs Lack Intrinsic Reward
I love the expression “food for thought” as a concrete, mysterious cognitive capability humans experience but LLMs have no equivalent for. Definition: “something worth thinking about or considering, like a mental meal that nourishes your mind with ideas, insights, or issues that require deeper reflection. It's used for topics that challenge your perspective, offer new understanding, or make you ponder important questions, acting as intellectual stimulation.” So in LLM speak it’s a sequence of tokens such that when used as prompt for chain of thought, the samples are rewarding to attend over, via some yet undiscovered intrinsic reward function. Obsessed with what form it takes. Food for thought.

NanoGPT: First LLM Trained and Run in Space
nanoGPT - the first LLM to train and inference in space 🥹. It begins.

Future LLMs Retroactively Grade Decade-Old Hacker News
Quick new post: Auto-grading decade-old Hacker News discussions with hindsight I took all the 930 frontpage Hacker News article+discussion of December 2015 and asked the GPT 5.1 Thinking API to do an in-hindsight analysis to identify the most/least prescient comments. This...

Python's random.seed Ignores Sign, Yields Identical RNG
In today's episode of programming horror... In the Python docs of random.seed() def, we're told "If a is an int, it is used directly." [1] But if you seed with 3 or -3, you actually get the exact same rng object, producing...

Treat LLMs as Simulators, Not Personal Thinkers
Don't think of LLMs as entities but as simulators. For example, when exploring a topic, don't ask: "What do you think about xyz"? There is no "you". Next time try: "What would be a good group of people to explore xyz? What would...

New AI Tests Need Fresh Images; Recipe Finally Clarified
One more comment is that giving this image to an AI and asking about it is not sufficient to show the diff because it's all over the training data by now. You'd have to use a new, very recent image,...

Pretrain, Fine‑tune, and Let Big AI Solve Tasks
@matejhladky_dev AI has crushed it since this post way beyond expectation. I made the same category of mistake all of AI was making, of thinking we have to discover and write the algorithm. You don't. You pretrain and then finetune...

LLMs Know Popular APIs, Need Docs for Obscure Ones
I've had medium success asking LLMs if a thing exists, it works out of the box for some of the more well-known things (e.g. both GPT 5.1 and Gemini 3 know about this function if you describe the tensor transformation...

Assume AI in Homework; Grade In‑class, Teach AI Fluency
A number of people are talking about implications of AI to schools. I spoke about some of my thoughts to a school board earlier, some highlights: 1. You will never be able to detect the use of AI in homework. Full...
AI Often Glitches; Re‑roll Until It Works
@_thomasip haha yes it makes mistakes! You have to re-roll a few times until it's right. Sometimes it gets stuck in loops and you have to re-start in a new conversation. Example re-roll: https://t.co/dK3VcuJLDn

Gemini Nano Banana Pro Solves Exam Images, Catches ChatGPT Errors
Gemini Nano Banana Pro can solve exam questions *in* the exam page image. With doodles, diagrams, all that. ChatGPT thinks these solutions are all correct except Se_2P_2 should be "diselenium diphosphide" and a spelling mistake (should be "thiocyanic acid" not "thoicyanic") :O...
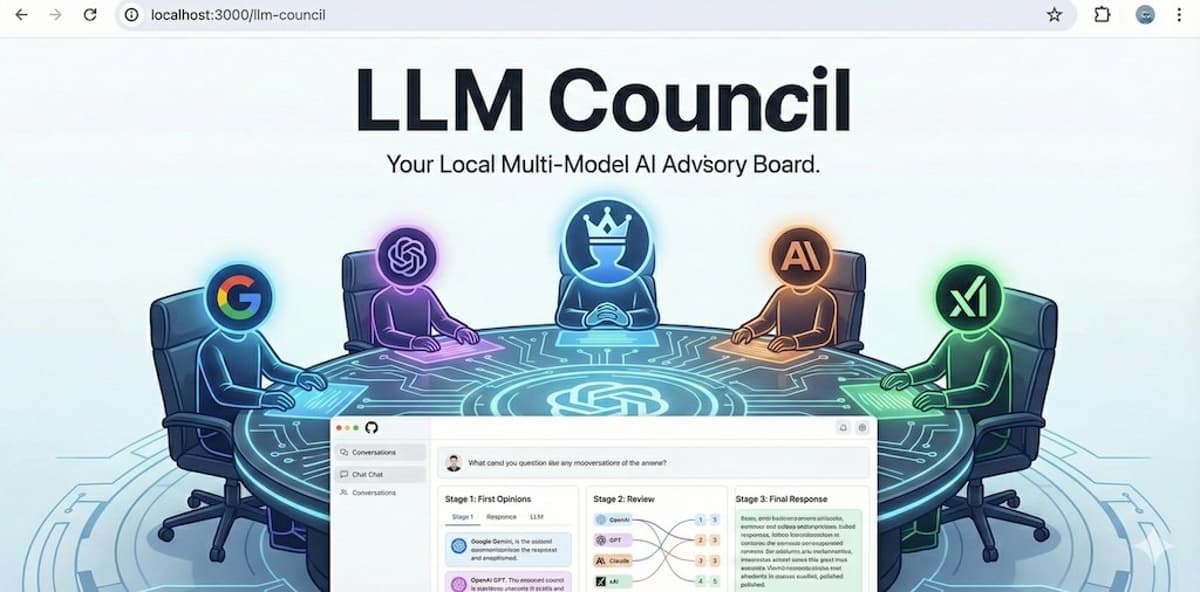
LLM Council Lets Models Rank Each Other’s Answers
As a fun Saturday vibe code project and following up on this tweet earlier, I hacked up an **llm-council** web app. It looks exactly like ChatGPT except each user query is 1) dispatched to multiple models on your council using...

Gemini 3 Shows Tier‑1 Performance, Yet Benchmark Gaming Persists
I played with Gemini 3 yesterday via early access. Few thoughts - First I usually urge caution with public benchmarks because imo they can be quite possible to game. It comes down to discipline and self-restraint of the team (who is...

Reading with LLMs Deepens Understanding, Shifts Writing Focus
I’m starting to get into a habit of reading everything (blogs, articles, book chapters,…) with LLMs. Usually pass 1 is manual, then pass 2 “explain/summarize”, pass 3 Q&A. I usually end up with a better/deeper understanding than if I moved...

Self‑Driving Cars Will Redefine Streets and Human Focus
I am unreasonably excited about self-driving. It will be the first technology in many decades to visibly terraform outdoor physical spaces and way of life. Less parked cars. Less parking lots. Much greater safety for people in and out of...

HW4 Model X FSD Feels Like a Maglev Ride
I took delivery of a beautiful new shiny HW4 Tesla Model X today, so I immediately took it out for an FSD test drive, a bit like I used to do almost daily for 5 years. Basically... I'm amazed -...

Teach Tiny LLMs New Skills with Synthetic SpellingBee Tasks
Last night I taught nanochat d32 how to count 'r' in strawberry (or similar variations). I thought this would be a good/fun example of how to add capabilities to nanochat and I wrote up a full guide here: https://t.co/fz1AMI5kqk This is done...

Text Diffusion: Simple Bi‑Directional Transformer Beats Autoregression
Nice, short post illustrating how simple text (discrete) diffusion can be. Diffusion (i.e. parallel, iterated denoising, top) is the pervasive generative paradigm in image/video, but autoregression (i.e. go left to right bottom) is the dominant paradigm in text. For audio I've...

Run Your Own ChatGPT Clone in Just Four Hours
Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single, dependency-minimal codebase....