

Pod DNS Not Working - Part 1
The video walks through a classic Kubernetes interview scenario: a pod cannot resolve DNS names and the engineer must pinpoint the failure point. It stresses that pods rarely use static IPs; instead they depend on the cluster’s DNS service (CoreDNS) to translate service names into IPs, making name resolution essential for dynamic workloads. The presenter outlines the DNS lookup chain: a pod reads /etc/resolv.conf, which points to the kube-dns service; the request reaches a CoreDNS pod, which resolves internal names like kubernetes.default and forwards external queries (e.g., google.com) to upstream resolvers. By running two simple dig or nslookup commands—one for an internal service and one for an external domain—operators can quickly isolate whether the problem lies in cluster DNS, external DNS, or network connectivity. He explains the diagnostic matrix: if both lookups fail, CoreDNS or network firewalls are likely down; if only the external lookup fails, forwarding or upstream DNS is broken; if only the internal lookup fails, the pod may be querying the wrong DNS server. The type of error matters too—NXDOMAIN signals a non‑existent name, while a timeout indicates the pod never reached a DNS server. Understanding this flow lets teams troubleshoot DNS outages faster, reducing application latency and downtime. It also highlights that seemingly “slow” DNS may simply be excessive retries rather than a true failure, guiding operators toward more precise remediation.
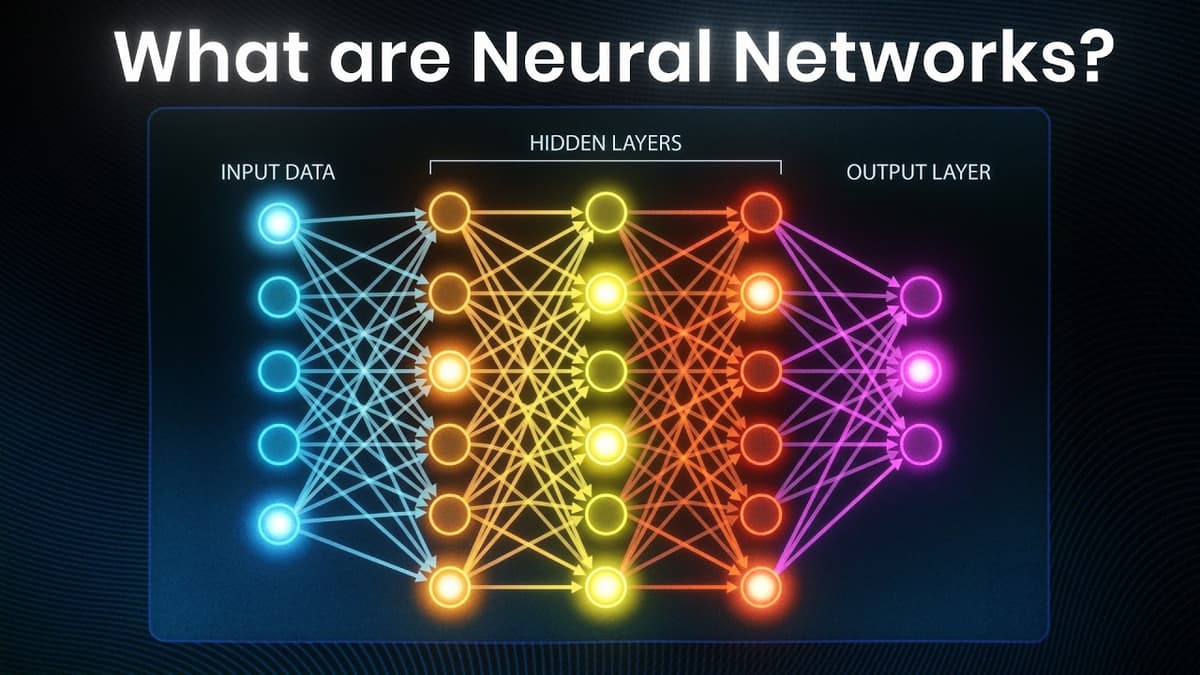
Neural Networks Explained in 3 Minutes
The video provides a rapid three‑minute tour of neural networks, tracing their evolution from early biological inspiration to the foundation of today’s large language models. It highlights three pivotal milestones: the 1943 neuron‑mimic model, the late‑1980s introduction of back‑propagation that made...

AI Agents vs Workflows: What Changed (2026)
The video traces the evolution from rigid workflow automation to LLM‑driven AI agents, emphasizing how breakthroughs such as tool calling and expanding context windows have reshaped automation by 2026. Key insights include the transition from prompt engineering to context engineering as...
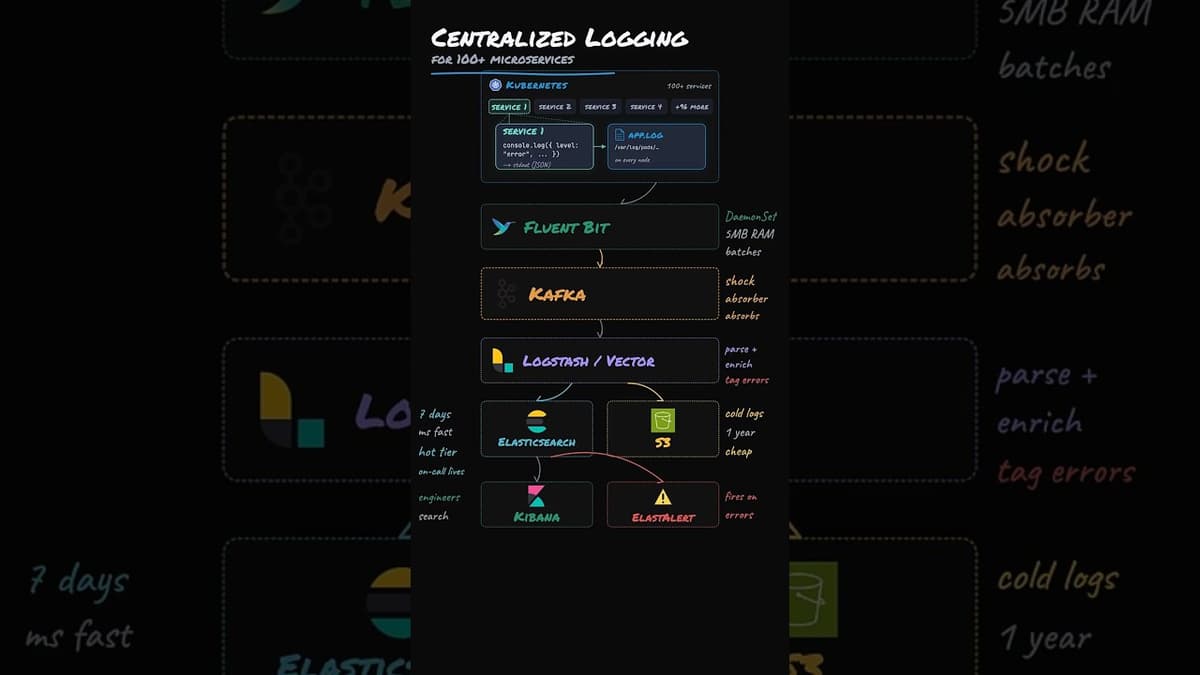
Design Centralized Logging System
The video walks through building a centralized logging pipeline for a Kubernetes deployment of over a hundred microservices, each emitting structured JSON to stdout. Logs are harvested by Fluent Bit running as a DaemonSet on every node, which reads the node‑level...
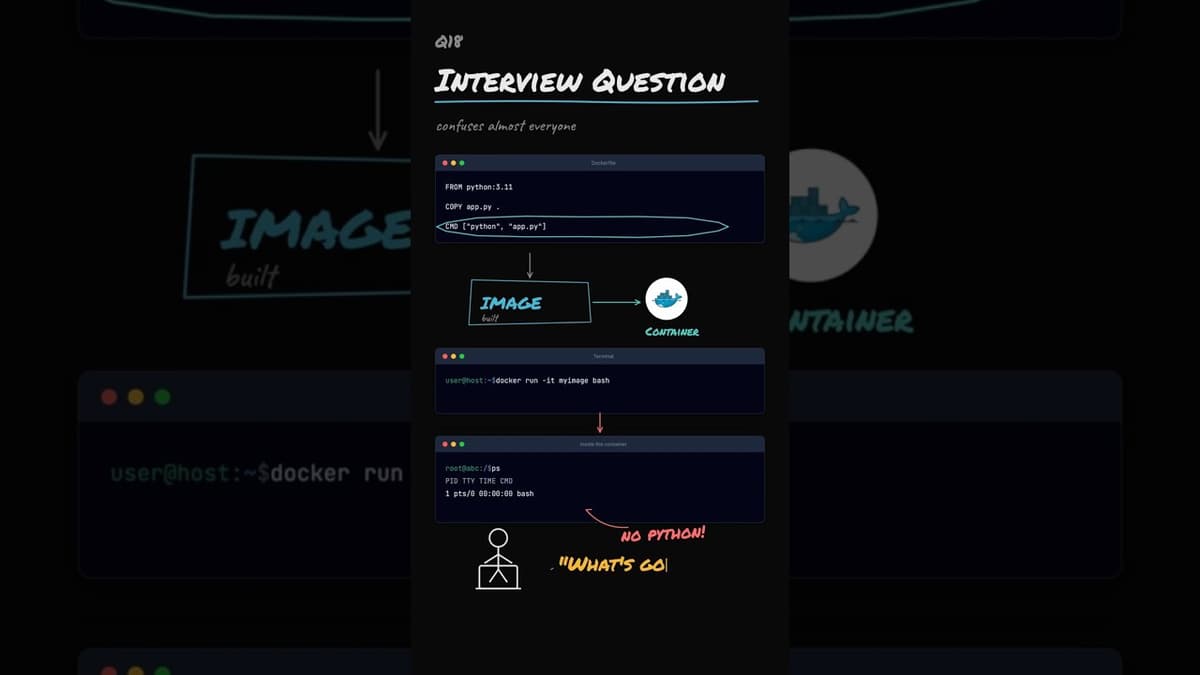
Container Interview Question
The video tackles a common Docker interview puzzle: why a container built with a CMD of python app.py shows only a Bash shell when launched with docker run -it myimage bash. It explains that docker run always starts a fresh container, and any command...
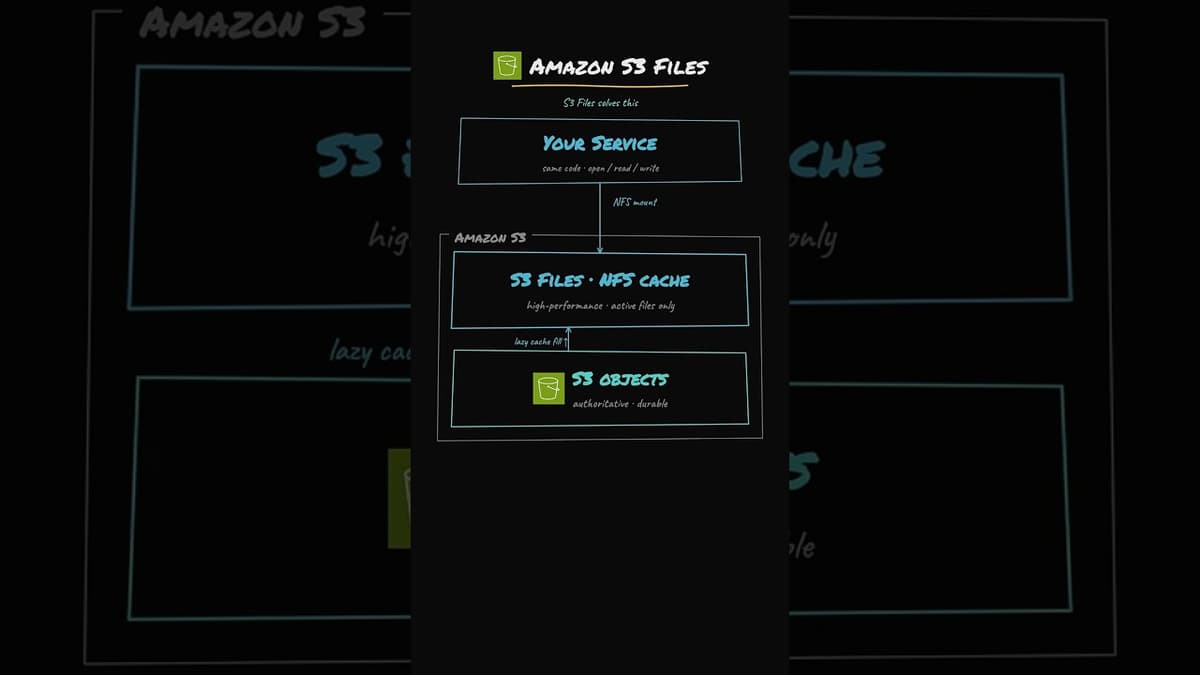
AWS Amazon S3 Files Explained
AWS introduced Amazon S3 Files, a service that lets customers mount an S3 bucket as an NFS file system, letting legacy Linux applications read and write files without code changes. Traditional architectures copy objects from S3 to an EFS volume, incurring...
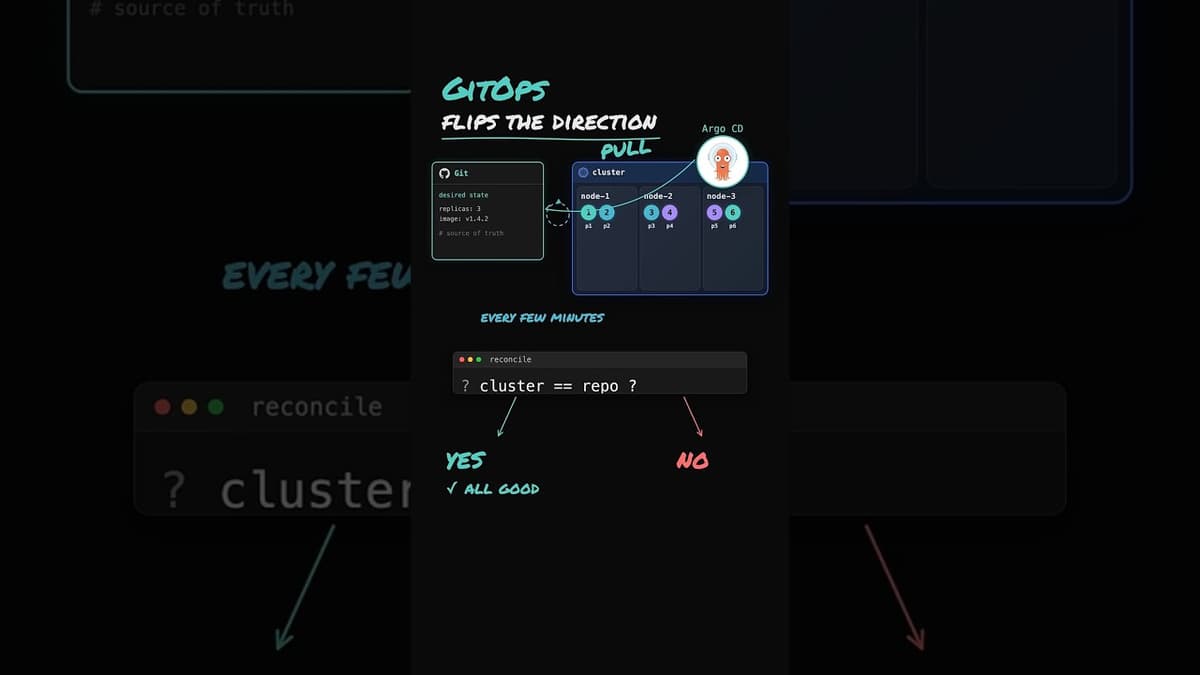
Why GitOps Exists (And Why CI/CD Alone Wasn't Enough)
The video asks why GitOps emerged despite the existence of continuous deployment pipelines. Traditional CD tools such as Jenkins or GitHub Actions push manifests to Kubernetes, but they leave no mechanism to verify that the live cluster still mirrors the...

How Reasoning Models Actually Work
The video explains how reasoning models work, focusing on OpenAI's O1 release in September 2024 that added a reasoning layer, shifting AI performance beyond simple scaling of data, parameters, and GPUs. It describes the chain‑of‑thought process: the model first generates a...
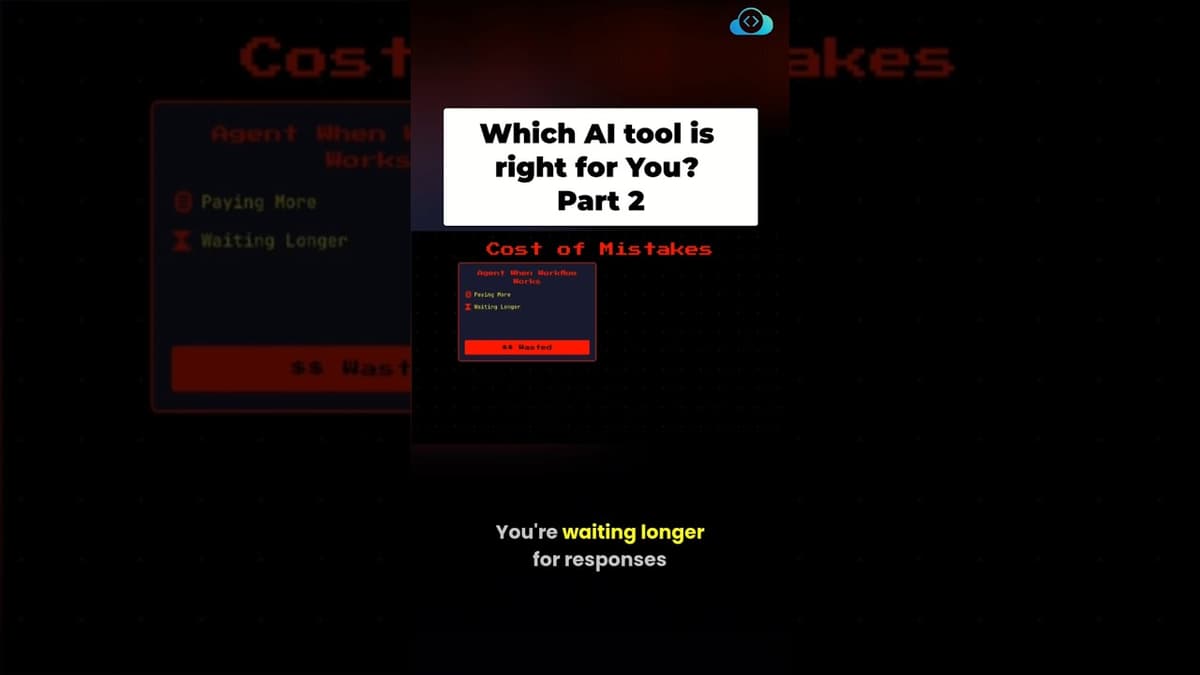
(Part 2/2) Agent vs Workflow - Which Should You Choose?
The video explains how to choose between large‑language‑model agents and deterministic workflows for automating tasks. It emphasizes that the wrong choice can increase expenses, latency, and debugging effort, while the right choice aligns tool complexity with business needs. Four decision criteria...
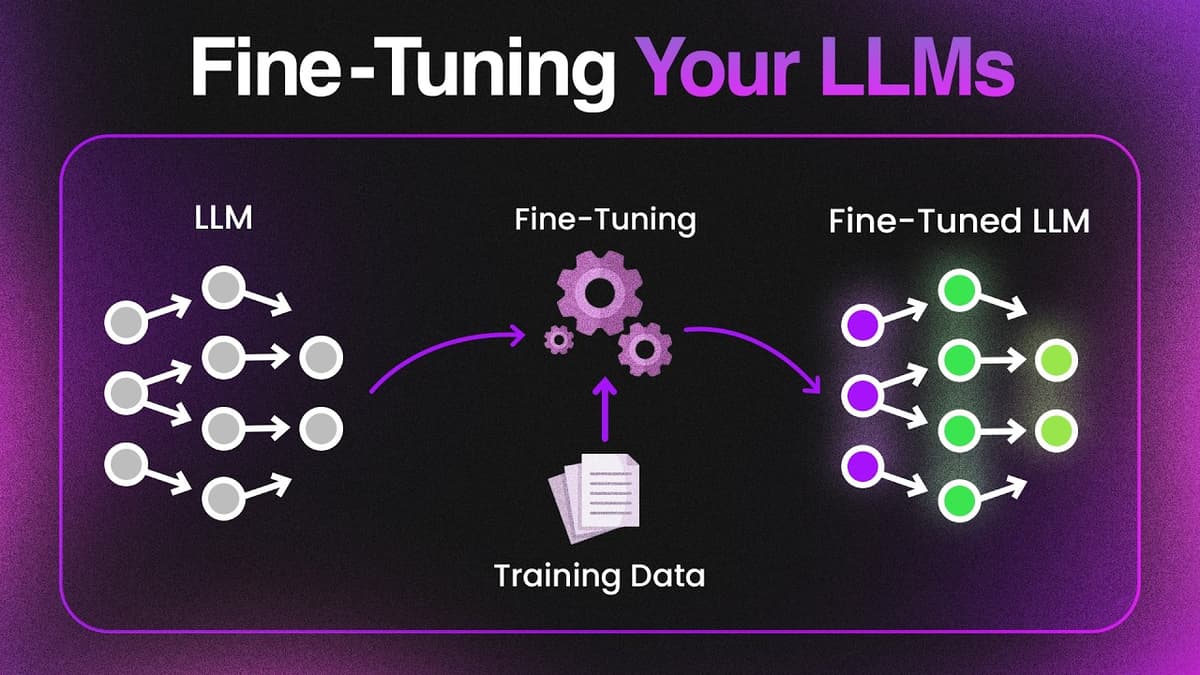
LLM Fine Tuning Tutorial (Free Labs)
The video introduces fine‑tuning of large language models as a practical alternative to prompt engineering for building specialist agents that require consistent, domain‑specific behavior. It explains why prompts are fragile—users can inject jailbreak instructions that override system prompts—while fine‑tuning directly alters...

Slow Database Interview Question
The video tackles a common DevOps interview scenario where a developer blames a 30‑second four‑table join on insufficient hardware and proposes moving to a larger database instance. The presenter explains that the root cause is almost always a query‑level problem: missing...
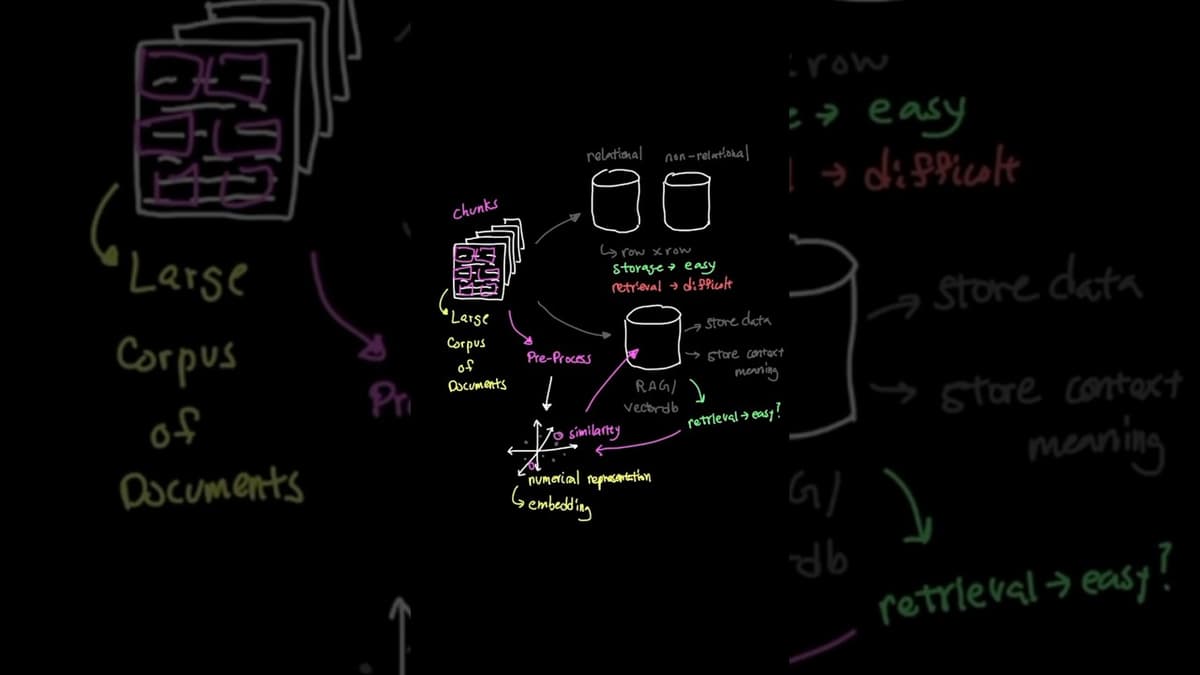
What Is RAG? How AI Chatbots Access Your Custom Data (Explained Simply)
The video explains Retrieval‑Augmented Generation (RAG), a technique that enables AI chatbots to pull information from proprietary data sources such as company policies, medical records, or custom databases, rather than relying solely on pre‑trained knowledge. RAG works by pre‑processing large document...

AI Agents vs AI Workflows (Part - 1/2)
The video contrasts two AI paradigms: static workflows, where every step is mapped before execution, and adaptive agents, which decide the next action in real time. A workflow resembles a flowchart—once the sequence is drawn, the process follows it until...
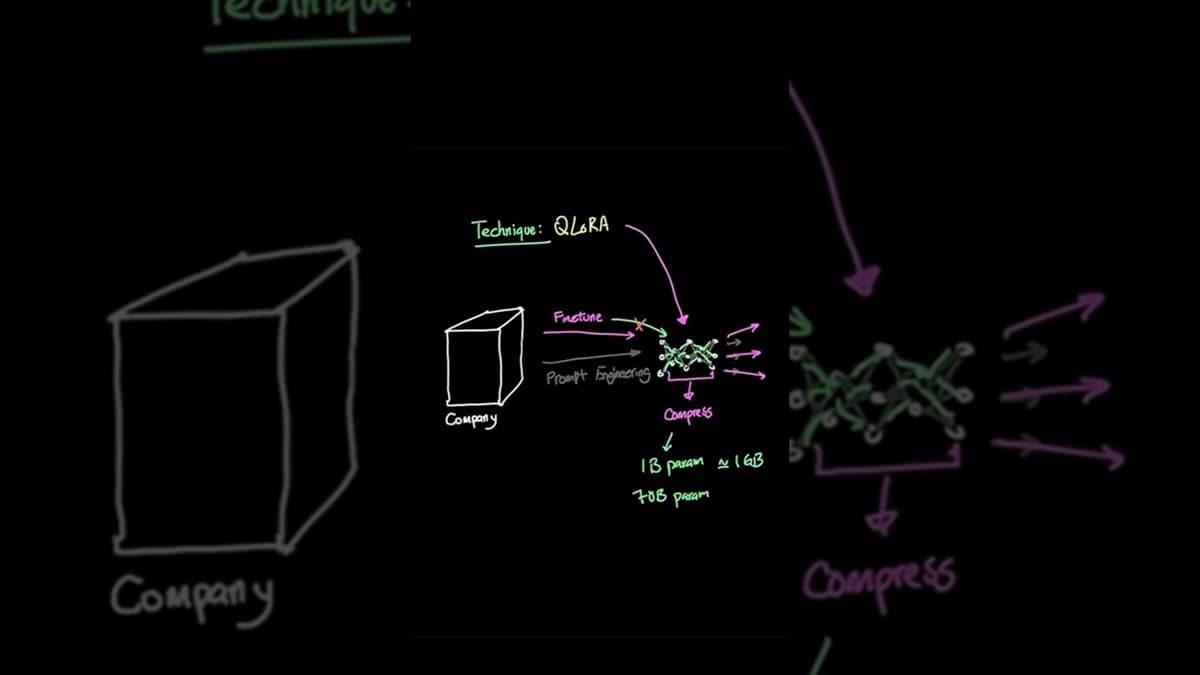
Why Prompt Engineering Is DEAD (Do This to Your LLM Instead)
The video argues that traditional prompt engineering is reaching its limits for building company‑specific AI agents, and that fine‑tuning large language models (LLMs) is the next logical step. By adjusting the model itself rather than crafting ever‑more complex prompts, organizations...
How AI Workflows Really Work (Part 2/2)
The video explains advanced AI workflow patterns that go beyond simple prompt‑response chains, highlighting how developers can orchestrate large language models (LLMs) to run multiple subtasks, reach consensus, or iteratively refine outputs. It describes three core mechanisms: (1) parallel sectioning, where...