

How AI Workflows Really Work (Part 1/2)
The video introduces AI workflows, systems where developers stitch together large language model (LLM) calls and external tools using predefined code paths. Unlike ad‑hoc prompting, the developer explicitly defines each step, letting the LLM handle heavy lifting while the surrounding logic controls execution. Two core patterns are highlighted. The sequential pattern breaks a task into ordered stages—e.g., one LLM drafts an email, a second refines it—allowing programmatic validation between calls. The routing pattern first classifies the user’s request, then dispatches it to the most suitable handler, enabling model selection based on difficulty. Concrete examples include an email‑draft‑and‑review loop and a classifier that routes simple queries to a lightweight model while reserving a premium model for complex travel planning. The presenter emphasizes that developers can embed checks, such as schema validation, before feeding output to the next LLM. By structuring LLM interactions as deterministic workflows, teams gain predictability, easier debugging, and cost control. Enterprises can scale AI services while balancing performance and expense, making workflow design a strategic capability in the emerging AI stack.
The Best AI Coding Assistant in 2026?
The video stages an eight‑way showdown of AI‑powered coding assistants, ranking them from Amazon Q to Cursor and declaring a winner for 2026. It emphasizes how quickly the landscape evolves, warning viewers the rankings will be stale in months. Amazon Q...
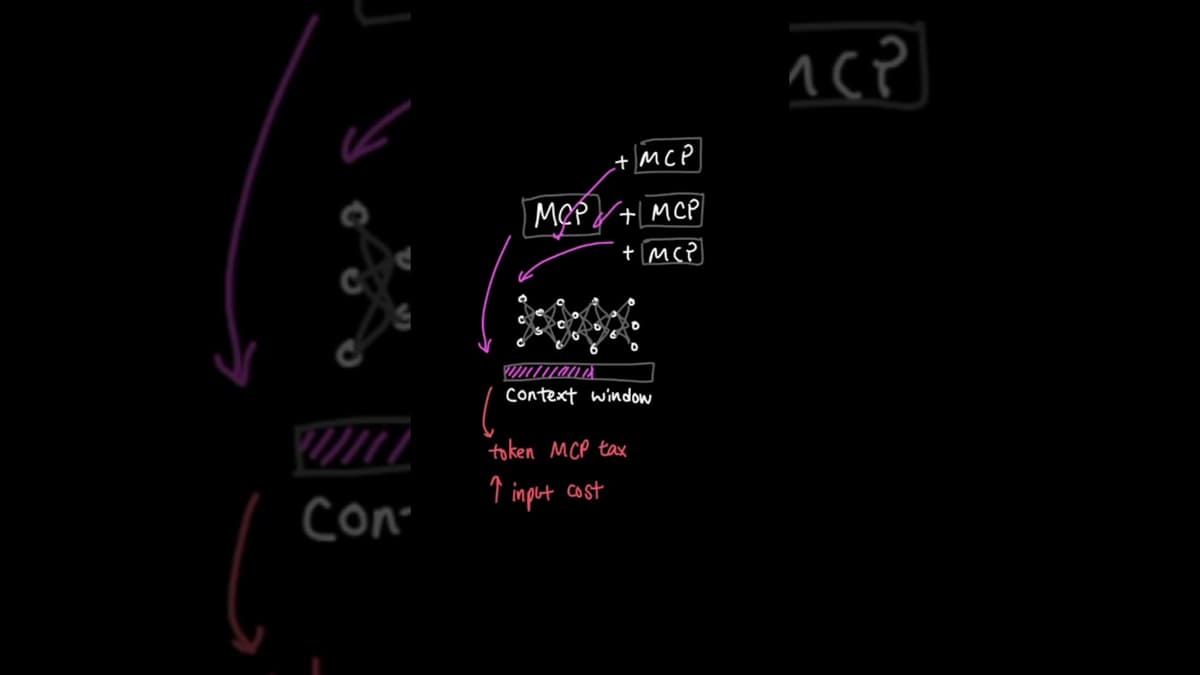
Everyone's Quitting MCP… Here's What They're Using Instead #shorts
The video highlights a shifting sentiment among AI developers: the once‑popular Model Control Protocol (MCP) is being abandoned in favor of leaner CLI and API‑only solutions. Recent posts from industry figures, including Y Combinator’s Gary Tan and the CTO of Propexity,...

LLM Roles and Messages (Part - 2/3)
The video explains that the system role is a hidden instruction set given to a language model before any user input, analogous to briefing a new employee before their first customer call. It shows that without a system message, a generic...

Fine-Tuning LLMs with LoRA and QLoRA (Free Labs)
The video walks through practical steps for fine‑tuning large language models, emphasizing LoRA and its 4‑bit variant QLoRA as cost‑effective alternatives to full‑weight updates. It frames the shift from prompt engineering to model‑level customization as essential for companies that want...

8 Kubernetes Books Ranked — One Winner, and It's Not Even Close 🏆
The video pits eight popular Kubernetes books against each other to identify the most valuable resource for practitioners, ultimately crowning a single winner. The host evaluates each title on criteria such as foundational theory, day‑two operations, production‑grade troubleshooting, and breadth of...

How LLM API Calls Actually Work (OpenAI SDK vs Raw HTTP)
The video demystifies the mechanics behind calling large language models, contrasting the low‑level HTTP workflow with OpenAI’s Python SDK. When a user types a prompt, the client packages it, sends it to OpenAI’s servers, and the model emits tokens one at...

Prompting Basics - Part 3/3
The video explains advanced prompting techniques for large language models, emphasizing few-shot examples, role‑based system messages, positive instruction framing, and chain‑of‑thought sequencing. It contrasts zero‑shot prompts, which often produce verbose or mis‑formatted answers, with few‑shot prompts that include a sample...

Prompting Techniques Part 2/3
The video explains prompting techniques for OpenAI’s chat API, emphasizing that messages carry roles—system, user, and assistant. The system role, set by developers, dictates the model’s behavior, rules, and personality, while the user role supplies the query and the assistant...

Azure DevOps Engineer Question 28
The video explains how to configure an Azure DevOps pipeline so that it runs on every commit except when only documentation files, such as Markdown (*.md), are changed. The presenter walks through the AZ200 certification question, emphasizing the correct YAML...

Azure DevOps Engineer Question 27
The video walks through AZ‑400 question 27, which asks which Azure Pipelines task should be used to create a deployment artifact for a .NET application that must contain only compiled binaries and configuration files, not source code. It explains that the...

Azure DevOps Engineer Question 26
The video tackles Azure DevOps Engineer certification question 26, which asks how to ensure a SQL Server database returns to a known state before each integration‑test run in a pipeline. It emphasizes the need for an automated, repeatable solution rather...

AWS AI Practitioner Question 35
The video walks through AWS AI Practitioner exam question 35, which asks which AWS service best fits a retailer’s need to forecast inventory demand for 10,000 products across 200 stores using three years of sales, seasonality, promotions and weather data. The...

The Real Reason AI Loses Track of Your Conversation
The video explains that large language models forget earlier parts of a dialogue because their context window is limited. When a conversation exceeds this window, the system must decide which tokens to keep, and three primary strategies—truncation, summarization, and sliding...

How to Use Byobu to Keep Long SSH Commands Running
Byobu acts as a lightweight terminal multiplexer that lets users maintain persistent sessions on remote Linux servers. By wrapping long‑running commands inside Byobu’s “protective bubble,” the processes continue even if the SSH connection drops or the laptop powers off. The...

What Is a Context Window?
The video clarifies what a context window is—a hard limit on the number of tokens an LLM can process at once, encompassing system instructions, prior dialogue, the latest user prompt, and the model’s own generated text. It breaks down a typical...

Azure DevOps Engineer Question 24
The video addresses an AZ‑400 exam scenario where a team must validate an Azure Resource Manager (ARM) template’s syntax before deploying it through an Azure Pipelines build. It explains that the Azure Resource Group Deployment task includes a ‘validation mode’ that...

AWS AI Practitioner Question 34
The video walks through AWS AI Practitioner exam question 34, which asks which evaluation metric a maintenance team should prioritize after deploying a machine‑learning model that predicts equipment failures. Although the model boasts a 95% overall accuracy, it missed 40%...

Every AI Request Has a Price and It's Paid in Tokens.💲
The video explains that tokens are the fundamental unit of cost and capacity in large language models, acting like currency for each interaction. It details how tokenization works: common words become single tokens, while rarer or longer words are broken into...

How the vLLM Inference Engine Works?
The video walks through the architecture and practical use of the vLLM inference engine, showing how it transforms a basic single‑request LLM setup into a production‑ready, multi‑user service. It contrasts the naïve Hugging Face baseline with vLLM’s optimized pipeline, emphasizing...

Can AI Pass Humanity's Last Exam?
The video introduces “Humanity’s Last Exam,” a comprehensive benchmark designed to test AI models on hundreds of subjects—from advanced mathematics to ancient literature—by presenting some of the most difficult questions humanity can pose. Results show rapid progress: Gemini 3.5 Pro achieved a 45.9 %...

LLMs Limitations Explained
The video outlines the fundamental limitations of large language models (LLMs), emphasizing that while they excel at generating human‑like text, they remain constrained to pure language tasks. It highlights four core weaknesses: inaccurate arithmetic because the model predicts tokens rather than...

AWS AI Practitioner Question 32
The video addresses an AWS AI Practitioner exam scenario where a company builds a customer‑support chatbot on Amazon Bedrock and must block unrelated topics, profanity, and prompt‑injection attempts. It highlights the need for a safety mechanism that can enforce content...

Why Does AI Charge You MORE Every Time It Replies? 🤯
The video explains why AI providers such as Frontier Labs, OpenAI, Gemini, XAI and Anthropic charge substantially more for output tokens than for input tokens. It shifts the focus from subscription‑based pricing to a per‑token model, emphasizing that each token...

What Does GPT Actually Stand For? (Explained Simply) 🤖
The video demystifies the acronym GPT, explaining that ChatGPT merges a chat interface with the underlying Generative Pre‑trained Transformer model, the AI engine that powers the conversation. It breaks down each component: a transformer’s attention mechanism lets the model consider every...

AI Agents for Beginners Course - Part 1
The video introduces the first part of a beginner‑focused AI Agents course, led by instructor Pumshad Manhatt. It promises to strip away the intimidation surrounding artificial‑intelligence agents by starting from zero‑knowledge fundamentals and progressing to full‑stack agent construction. The curriculum covers...

What Is AIOps?
The video introduces AI Ops—artificial‑intelligence‑driven IT operations—as a response to the massive data streams generated by modern software stacks, where enterprises routinely produce tens of gigabytes of logs and run thousands of microservices. Traditional operations rely on human analysts to triage...

Azure DevOps Engineer Question 23
The video walks through Azure DevOps certification question 23, which asks candidates to select the proper configuration for a retention strategy that keeps pipeline artifacts for 30 days while preserving production release artifacts indefinitely. The correct answer is to set a...

AWS AI Practitioner Question 33
The video addresses a common challenge for marketing teams using Amazon Bedrock: generating multilingual product descriptions that are concise, free of competitor references, and factually accurate. The presenter outlines three distinct problems—excessive length, inadvertent mention of rivals, and hallucinated features—and...

What Is AWS MFA? ( Multi-Factor Authentication Explained )
The video introduces AWS Multi‑Factor Authentication (MFA) as a critical safeguard against credential compromise, explaining that a stolen username and password alone are insufficient when MFA is active. It outlines how MFA works: after entering standard credentials, users must supply a...

What Is an AWS IAM Policy?
The video introduces AWS Identity and Access Management (IAM) policies as JSON‑formatted documents that explicitly allow or deny actions on AWS services and resources. It explains that policies can be highly granular—down to individual API calls such as “s3:CreateBucket” while denying...

Azure DevOps Engineer Exam: Question 20
The video addresses a practice‑exam question for the Azure DevOps Engineer certification, asking which integration lets a team receive Microsoft Teams notifications when a pull‑request (poll) request is approved. It explains that Azure DevOps service hooks—or webhooks—can be configured to push...

What Is AWS Secrets Manager?
The video introduces AWS Secrets Manager, a fully managed service that centralizes the storage of sensitive configuration data such as database passwords, API keys, and tokens. By moving secrets out of code repositories and environment files, the service eliminates the...

AWS IAM Explained in 60 Seconds
The video delivers a rapid overview of AWS Identity and Access Management (IAM), positioning it as the foundational security layer that must be configured before any compute or storage services are launched. It explains that IAM creates user accounts for humans,...

AWS AI Practitioner Question 24
The video explains a common exam question for the AWS AI Practitioner certification, asking which prompting technique involves inserting three ideal question‑answer pairs before a new customer query. The correct answer is few‑shot prompting, a method that supplies a small...

AWS AI Practitioner Question 22
The video explains a practice question from the AWS Certified AI Practitioner exam that asks candidates to identify why a fraud‑detection model performs perfectly on training data yet poorly on unseen transactions. The presenter highlights the stark contrast—99% accuracy on the...

Docker vs Kubernetes – What's the Difference and Why It Matters
The video contrasts Docker, a tool for building and running individual container images, with Kubernetes, a platform that orchestrates large fleets of those containers. It walks through a simple Dockerfile that pulls a Python base, installs Flask, copies code, and...

Deploying a Multi-Tier App on Kubernetes
The video walks through deploying a three‑tier voting application on a local Kubernetes cluster using Minikube, illustrating how each component—frontend, worker, and result services—can be orchestrated as separate pods. After applying the manifests, the voting front‑end is exposed on port 3004...

How Kubernetes Services Work Across Multiple Nodes
The video explains how Kubernetes services operate when pods are distributed across multiple nodes. When a Service is created, Kubernetes automatically provisions it across every node in the cluster, mapping the target port to a uniform NodePort—illustrated with port 3008—so...

Generate SSH Keys in 10 Seconds (Windows, Mac & Linux)
The video demonstrates how to generate SSH key pairs in under ten seconds on Windows, macOS, and Linux, positioning key‑based authentication as a faster, more secure alternative to password‑based logins. It explains that an SSH key consists of a public component,...

How to Verify Your Minikube Kubernetes Cluster Is Running
The video walks viewers through confirming that a Minikube Kubernetes cluster is correctly initialized. It begins by clearing the console and executing the `minikube status` command, which should report the control‑plane, kubelet, API server, and configuration as both “Running” and...
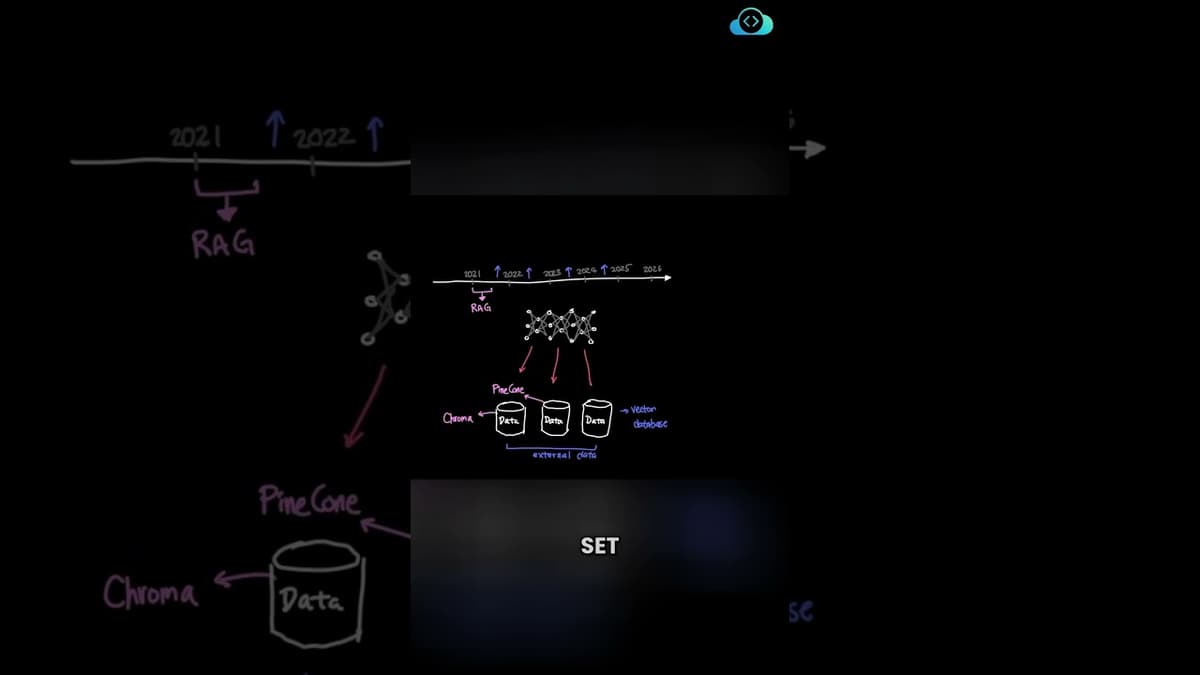
RAG Explained: How Retrieval Augmented Generation Actually Works
Retrieval-augmented generation (RAG), introduced in early 2021, augments large language models by letting them retrieve relevant information from external data stores before generating answers, overcoming the limits of small context windows. RAG workflows convert documents into vector embeddings using models...

RAG Chunking Strategies Explained (Fixed Size vs Semantic Chunking)
The video contrasts fixed-size chunking with semantic chunking for retrieval-augmented generation (RAG). Fixed-size chunking — by characters, words, sentences, or tokens — is simple to implement but can split documents at arbitrary points and ignore topical boundaries. Semantic chunking groups...

RAG Retrieval Metrics Explained: Recall, Precision, MRR & NDCG
The video explains key evaluation metrics for retrieval-augmented generation (RAG), focusing on relevance, comprehensiveness and correctness of retrieved documents. It defines recall@K (how many relevant documents are found within the top K), precision@K (proportion of top-K results that are relevant),...

Kubernetes YAML File Structure Explained
The video explains the required structure of Kubernetes YAML definition files, emphasizing four top-level fields: apiVersion, kind, metadata, and spec. It details each field’s purpose—apiVersion selects the Kubernetes API version, kind specifies the object type (case-sensitive), metadata holds identifying information...

What Is a Kubernetes Deployment? (Rolling Updates & Rollbacks Explained)
Kubernetes Deployments sit above Pods and ReplicaSets, providing a declarative layer for managing application lifecycles. They automate the creation and scaling of ReplicaSets while handling versioned rollouts without service disruption. Features such as rolling updates, instant rollbacks, and the ability...

How Kubernetes Services Connect Microservices (ClusterIP & NodePort Explained)
The video walks through Kubernetes service types—ClusterIP and NodePort—to illustrate how microservices discover and communicate with each other inside a cluster. It starts by showing why a voting app should not reference a Redis pod’s IP directly; instead, a Service...

How OpenAI Scaled ChatGPT to 800 Million Users with ONE Postgres Database
OpenAI’s latest blog post reveals that its ChatGPT service, now serving over 800 million users, still relies on a single primary PostgreSQL instance. The company’s disciplined engineering approach—eschewing premature sharding—has allowed it to scale from a handful of users in 2015...

What Is a Pod in Kubernetes? (K8s Basics Explained)
A pod in Kubernetes is the smallest deployable object and typically represents a single instance of an application, encapsulating one or more containers. Scaling is achieved by creating additional pods rather than adding containers to an existing pod, though sidecar/helper...

What Is a ReplicaSet in Kubernetes? (High Availability Explained)
A ReplicaSet in Kubernetes guarantees that a specified number of pod instances remain active at all times. When a pod crashes, the ReplicaSet automatically creates a replacement, preventing service interruption. It also spreads pods across available nodes, balancing load and...