

One OpenCV Adapter Chooses Fastest Vendor Code
(HAL & Universal Intrinsics — Part 2) One adapter between OpenCV and any chip. Vendors plug in their optimized code, you keep one interface on top, and OpenCV picks the fastest path automatically. KleidiCV for ARM. FastCV for Snapdragon. RISC-V Vector for open hardware. Full deep-dive 👇 https://t.co/kYwl17noU9 #OpenCV5 #ComputerVision #EdgeAI

Write Vision Code Once, Run Anywhere with OpenCV5 HAL
Write your computer vision code once. Run it fast on a CPU, a GPU, or a dedicated AI accelerator — without changing a single line. That's the promise of the Hardware Abstraction Layer (HAL) in OpenCV 5. Part 1 https://t.co/hzs5CNr1kd #OpenCV5 #ComputerVision...

Pointing Ability Boosts AI Agent Speed and Accuracy
Part 2: The future of AI agents may depend on something basic — not just whether they can see, but whether they can point. LocateAnything-3B: 12.7 boxes/sec, ~2.5x faster than Rex-Omni, and more accurate. Speed + precision is the whole game. https://t.co/HZQ19AwHYk...

Speed Makes NVIDIA's LocateAnything Truly Actionable AI
Part 1: NVIDIA's LocateAnything is built for the moment AI stops answering questions and starts pointing, clicking, reading, and acting. Speed isn't a luxury — it's the difference between a useful agent and a confused one. https://t.co/kHFOKMDYOB https://t.co/lyEEc5ADUB

OpenCV 5 DNN Engine Boosts ONNX Support, Speed
The Three DNN Engines of OpenCV 5. The old 4.x DNN engine imported ~22% of ONNX. The new graph-based engine pushes past 80%, fuses MatMul→Softmax→MatMul into one FlashAttention layer, and runs YOLO26n 41% faster than ONNX Runtime — no code changes. Deep...

YOLOE-26 Enables Open‑Vocabulary Detection via Text, Visual, or No Prompt
YOLOE-26 turns object detection into three ways of saying "find this": → Text prompt (name it) → Visual prompt (show it) → Prompt-free (let the model decide) Closed-set rigidity → open-vocabulary conversation. Tutorial + benchmarks: https://t.co/od9zkfvMaX https://t.co/t1bXsIl1HJ

YOLOE Enables Zero‑Overhead Open‑Vocabulary Detection
Object detection is shifting from "models that recognize fixed categories" to "models that understand concepts described in language." YOLOE delivers open-vocabulary detection at full YOLO speed — text module fused into the head, zero runtime overhead. Full tutorial + code: https://t.co/JKzMcctoGw

Robotic “Eyeball” Ensures Vision Pro Quality
This robot's only job is to pretend it's your eyeball 👁️🤖 At Display Week 2026, Dr. Satya Mallick visits Gamma Scientific — the 6-axis robot AR/VR brands use to QA every headset before launch. 18+ tests in one rig: contrast, parallax,...

MoE Training Amplifies Tiny Expertise Into Mastery
MoE Training, Part 2 — in one tweet: You start with random weights. By chance, one expert is slightly better at legal questions. Router notices, sends more its way. It gets better. Snowballs. Same compounding loop that turns a slightly-talented 7-year-old into...

Specialization Emerges Naturally in MoE Training
MoE Training, Part 1 — in one tweet: You do NOT assign "this expert handles medicine, this one handles law." You start with 9 random experts + a router. The router learns to pick 2–3 per question. Specialization emerges from data, not...

Frontier LLMs Adopt Mixture‑of‑Experts for Efficient Compute
Why every frontier LLM is converging on Mixture of Experts 🧵 Trillion-parameter model. Single query. You don't need the whole thing. A router picks a subset of "experts." Medical question → medical expert. Legal → legal. Some models keep one generalist always...

VLMs Share Label Role, Differ Vastly in Capabilities
"VLM" is doing a lot of heavy lifting as a label. CLIP → image-text alignment, zero-shot recognition Moondream → grounding ("find the guy in red") Qwen3-VL → agentic + GUI + long video understanding Same category. Wildly different tools. Dr. Satya Mallick explains → https://t.co/4AZvwlbKDm #VLM...
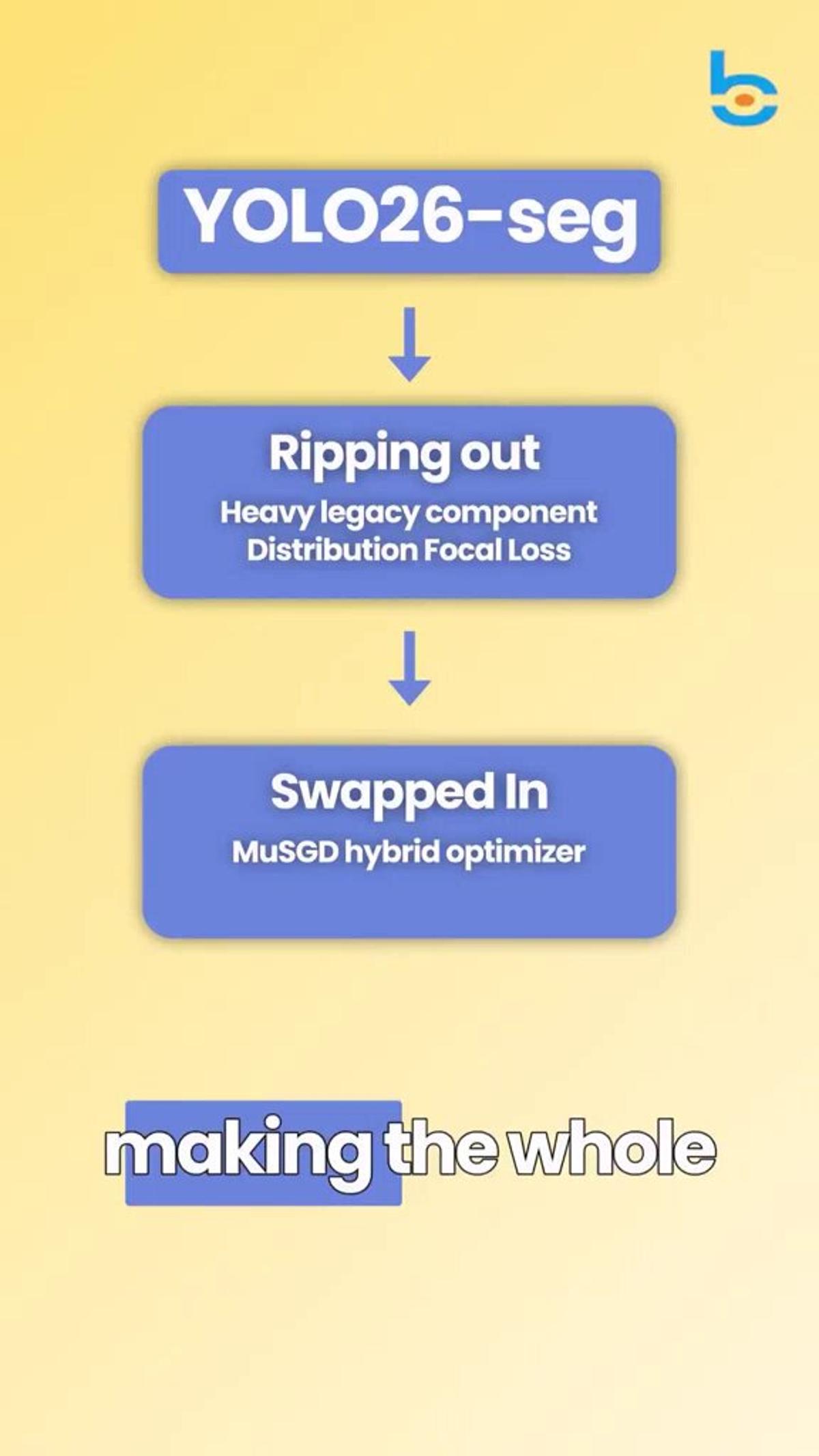
YOLO26‑Seg Delivers Razor‑sharp Masks, 43% CPU Speed Boost
Pt. 2 — YOLO26-Seg is wild: → Distribution Focal Loss removed → MuSGD optimizer (hybrid borrowed from LLM training) → NMS baked into the model → Boundary-aware supervision = razor-sharp masks → Up to 43% faster on CPU → One ONNX export → Pi, drone, phone Deep...

Real‑Time Monocular Depth From One Camera: Depth Anything V2
What if accurate depth maps could be generated from a single RGB image — without LiDAR or stereo cameras? That’s exactly what Depth Anything V2 achieves. In 2024, monocular depth estimation reached a major breakthrough: ✔ Fast ✔ Lightweight ✔ Temporally stable ✔ Edge-device friendly Instead of...

Experts Use Regularization; Novices Skip Its Top Benefits
The four benefits in order of impact: 1. Prevents overfitting (the big one) 2. Adversarial robustness 3. Augments small datasets 4. Softer decision boundaries Used by experts. Skipped by most novices. Don't be a novice. https://t.co/eK6lhglg6o