
Recent Posts

Social•Feb 20, 2026
February's AI Explosion: Six New Models Debut
February is one of those months... - Moonshot AI's Kimi K2.5 (Feb 2) - z. AI GLM 5 (Feb 12) - MiniMax M2.5 (Feb 12) - ByteDance Seed-2.0 (Feb 13) - Nanbeige 4.1 3B (Feb 13) - Qwen 3.5 (Feb 15) - Cohere's Tiny Aya (Feb 17) (+Hopefully DeepSeek V4 soon) Anything I forgot?
By Sebastian Raschka

Social•Feb 10, 2026
AI Should Free Experts, Not Add Extra Tasks
Yeah, in an ideal world, we would use AI to enable experts to do higher-quality work. But in the real world, they are also expected take on a wide range of additional responsibilities that detract (& distract) from their core work.
By Sebastian Raschka
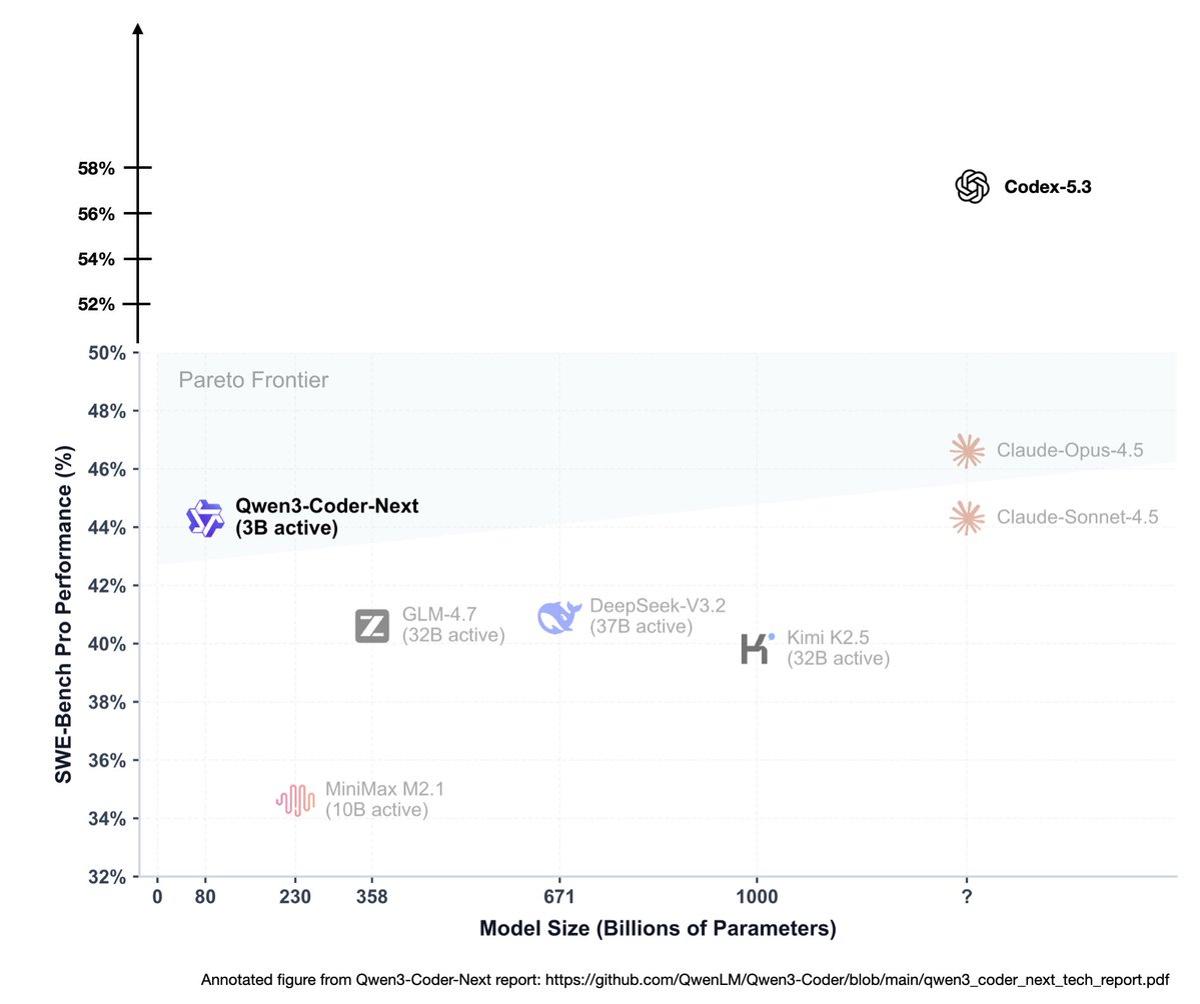
Social•Feb 5, 2026
Half the Tokens, Same Performance: Efficiency Wins
> "Less than half the tokens of 5.2-Codex for same tasks" That one line already says a lot. There is no assumption anymore that compute or budget is infinite in 2026. But if you can get better modeling performance while using...
By Sebastian Raschka

Social•Jan 30, 2026
Moltbook Shows LLMs Remain Pure Next‑Token Predictors
Yes, Moltbook (by clawdbot) is still next-token prediction combined with some looping, orchestration, and recursion. And that is exactly what makes this so fascinating. (It is also why understanding how LLMs actually work really does pay off. Lets us see through the...
By Sebastian Raschka

Social•Jan 29, 2026
LLM Future: Transformers Evolve, Inference Scaling Takes Spotlight
Had a fun chat with @mattturck the other day where we talked about a bunch of interesting LLM stuff... Basically everything from the future of the transformer architecture to inference-time scaling as a recent MVP of LLM performance:
By Sebastian Raschka
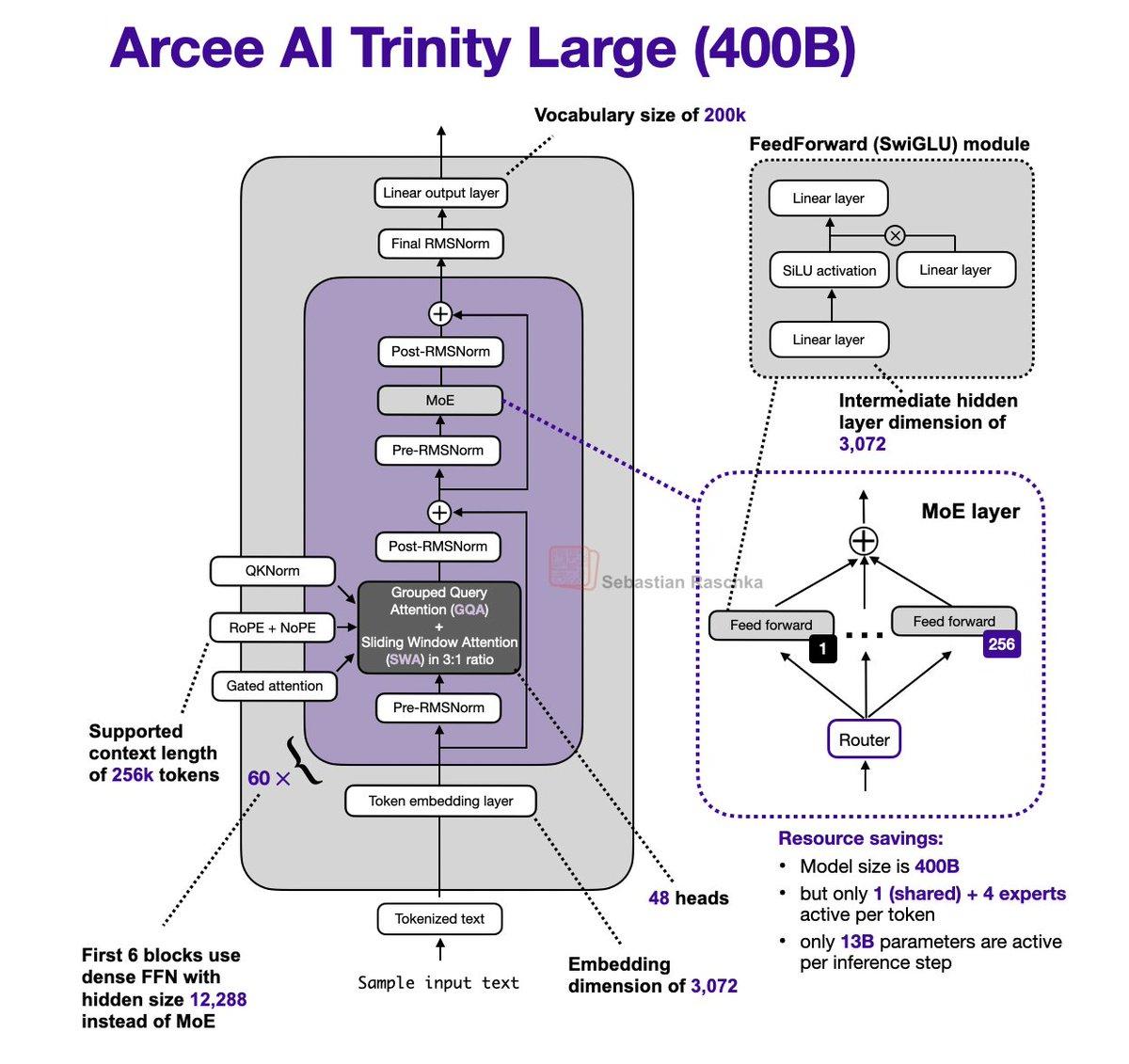
Social•Jan 29, 2026
Arcee Trinity Large Merges MoE, Gated
It's been a while since I did an LLM architecture post. Just stumbled upon the Arcee AI Trinity Large release + technical report released yesterday and couldn't resist: - 400B param MoE (13B active params) - Base model performance similar to GLM...
By Sebastian Raschka

Social•Jan 2, 2026
RL Shines on Moderately Out‑of‑distribution Data
Another really interesting paper from my 2025 bookmarked papers: On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models (https://t.co/UjhiJW643U). In short, RL is most effective when applied to data that is neither too close to nor too far...
By Sebastian Raschka