

GLM‑5.2’s IndexShare Slashes 1M‑token Inference Cost
Just caught up with the recent GLM-5.2 release. The best open-weight model today. Architecture-wise, it's build on the GLM-5 and GLM-5.1 architecture that I covered previously, which means it's reusing the Multi-head Latent Attention (MLA) and DeepSeek Sparse Attention (DSA) mechanisms from DeepSeek V3.2. (I wrote about it a while back here: https://lnkd.in/g9fcKkmm) What's new is that they added an IndexShare mechanism. (That's a cross-layer reuse trick for DSA where instead of recomputing the sparse-attention top-k indexer in every layer, GLM-5.2 runs the full indexer only once every four layers and lets the following layers reuse those selected token indices. This keeps the same DSA idea but makes 1M-token inference much cheaper.)
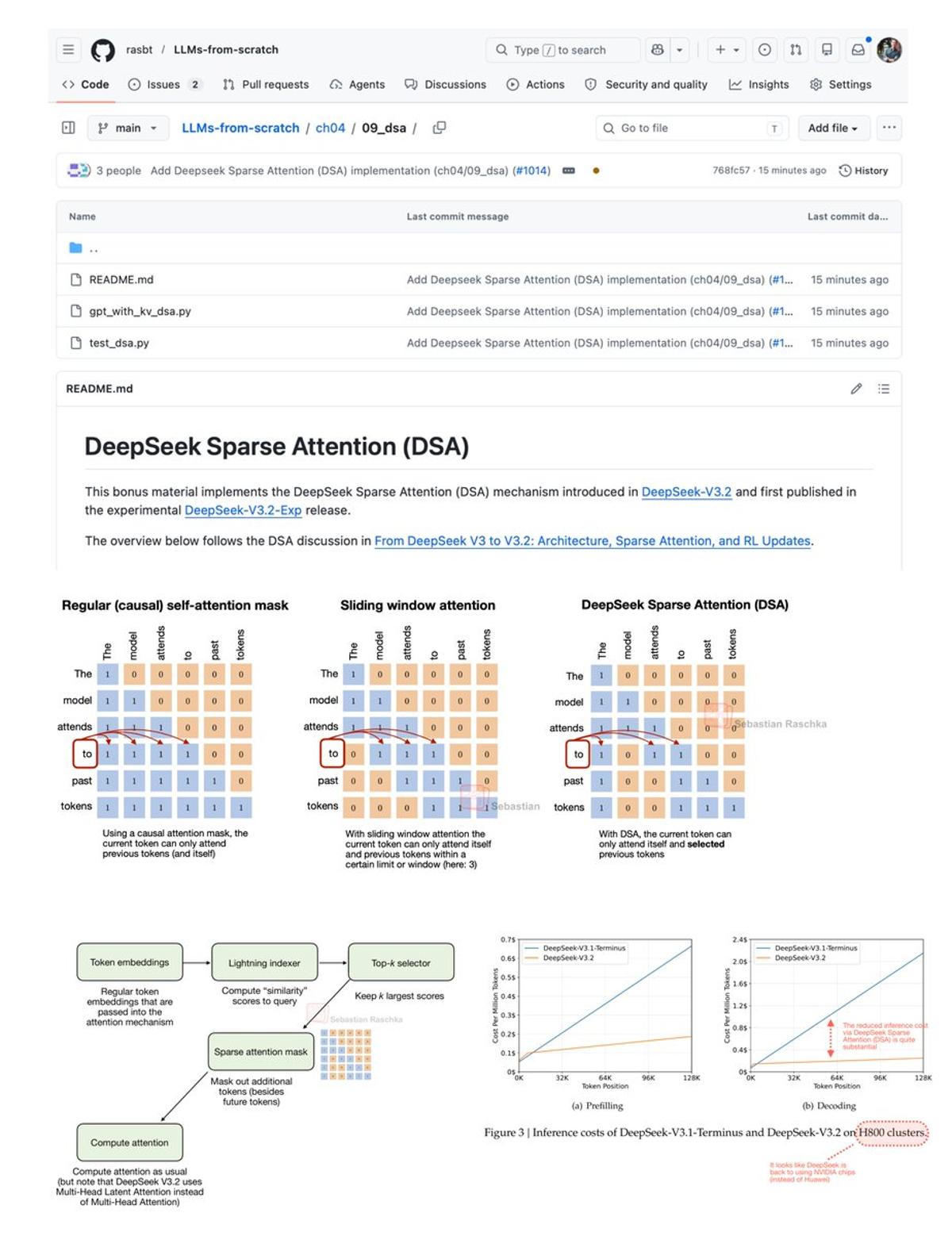
DeepSeek Sparse Attention Added to LLMs‑from‑scratch Repo
Added a DeepSeek Sparse Attention (DSA) from-scratch implementation to my LLMs-from-scratch repo thanks to an awesome new reader contrib. With motivation, overview, and GPT-style model reference implementation as standalone example code: https://t.co/o2PMhjF0TN https://t.co/jjKyt3aPcR
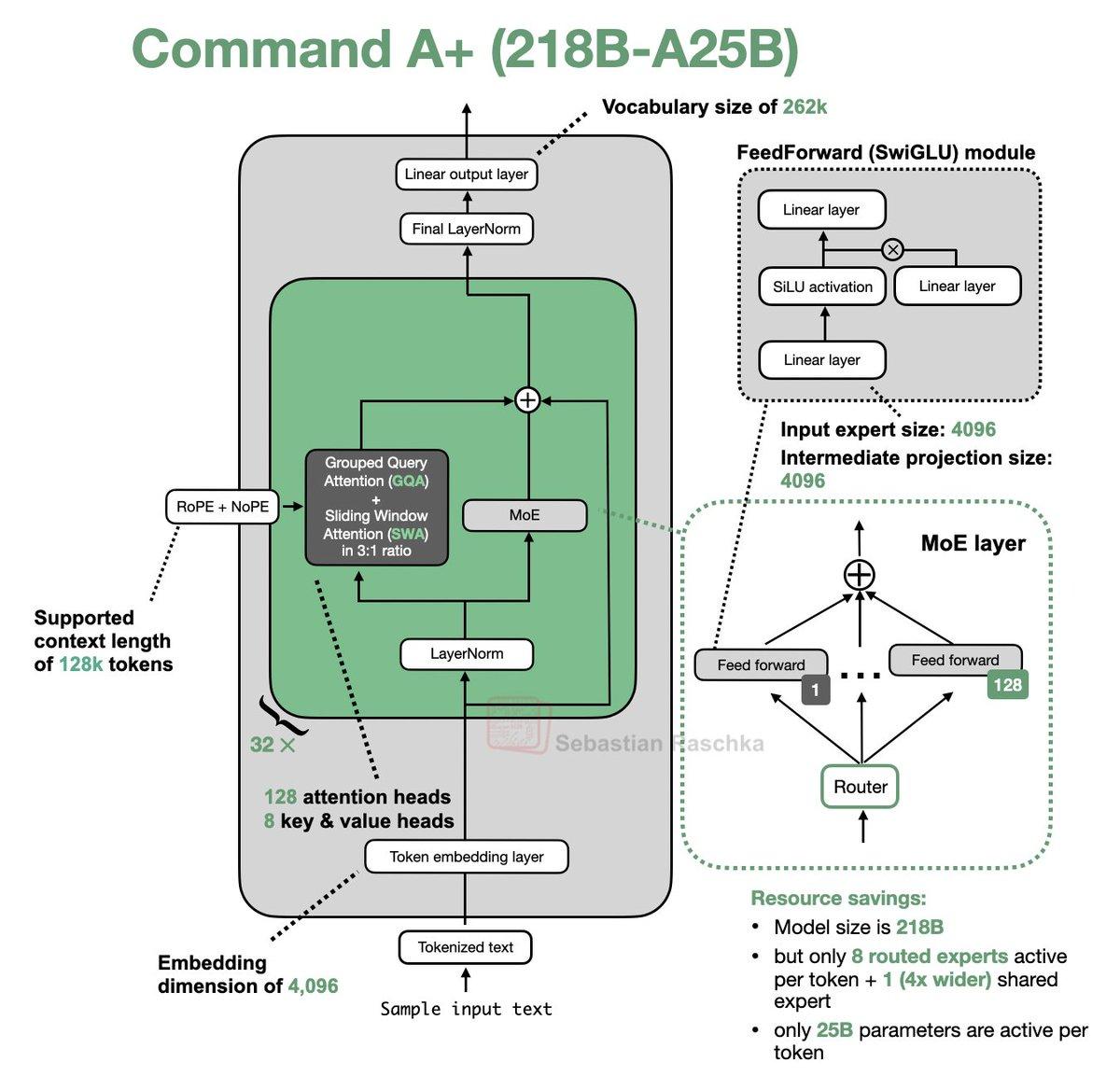
Parallel Transformer Blocks Boost Throughput Without Losing Performance
It's been *almost* a bit quiet around LLM architecture releases in the past two weeks 😅 Interesting tidbit is the parallel block design. Via the Cmd-A the tech report "equivalent performance but significant improvement in throughput compared to the vanilla transformer...

Visual Guide to LLM Long-Context Efficiency Innovations
New article: a visual tour of recent LLM architecture advances, from Gemma 4 to DeepSeek V4. I focus on long-context efficiency tweaks like KV sharing, per-layer embeddings, layer-wise attention budgets, compressed attention, and mHC. Link: https://t.co/KO81y3kTH7 https://t.co/wTx51QpQu4

Building LLMs From Scratch: Practical Python/PyTorch Insights
A little talk on what we can learn from implementing LLM architectures from scratch in Python and PyTorch. And how I approach new open-weight models, compare them against reference implementations etc: https://t.co/crKd2l9xGg

April’s LLMs Scale Up with Minor Architecture Tweaks
April was a pretty strong month for open-weight LLM architecture releases: 1. Gemma 4 Continues the local/global attention recipe with sliding window attention, which is a classic yet "easy" way to extend context while making it cheaper than full attention....

Loved PyCon DE: AI Community, Now on Family Break
Had a great time at PyCon & PyData DE. Highly recommend it. Great open-source, community-focused conference with lots of builders in the Python AI, LLM and agent space. Taking a short family break, my first "vacation" in years (hopefully, I won't...

New RSS Feed Simplifies Tracking LLM Architecture Updates
Added an RSS feed to the LLM Architecture Gallery so it is a bit easier to keep up with new additions over time: https://t.co/NO7z6XSRHS https://t.co/7PKrLT1A6S

Inside Coding Agents: Repo Context, Tools, Memory, Delegation
Components of a coding agent: a little write-up on the building blocks behind coding agents, from repo context and tool use to memory and delegation. Link: https://t.co/iF4DsMcnhj https://t.co/zImf32iegt

Build A Reasoning Model Chapters Now in Early Access
It’s done. All chapters of Build A Reasoning Model (From Scratch) are now available in early access. The book is currently in production and should be out in the next months, including full-color print and syntax highlighting. There’s also a preorder up on...

Open-Source Hard Distillation for Any LLM Released
The Ch08 Nb on distilling LLMs is now on GitHub: https://t.co/bPRyIU5BhH Hard distillation that works with any LLM (minding the terms of service, of course). https://t.co/KscPulkj7q

India's Sarvam 105B Matches Top LLMs Using MLA
While waiting for DeepSeek V4 we got two very strong open-weight LLMs from India yesterday. There are two size flavors, Sarvam 30B and Sarvam 105B model (both reasoning models). Interestingly, the smaller 30B model uses “classic” Grouped Query Attention (GQA), whereas the larger 105B variant switched...

Tiny Qwen3.5 Reimplementation: Top Small LLM For
A small Qwen3.5 from-scratch reimplementation for edu purposes: https://t.co/OnupgeE55l (probably the best "small" LLM today for on-device tinkering) https://t.co/LwyF8x6sle

New Tools Simplify Distillation Data From Open-Weight Models
Claude distillation has been a big topic this week while I am (coincidentally) writing Chapter 8 on model distillation. In that context, I shared some utilities to generate distillation data from all sorts of open-weight models via OpenRouter and Ollama: https://t.co/IsfNDpcGAw https://t.co/LKXuGrjO84
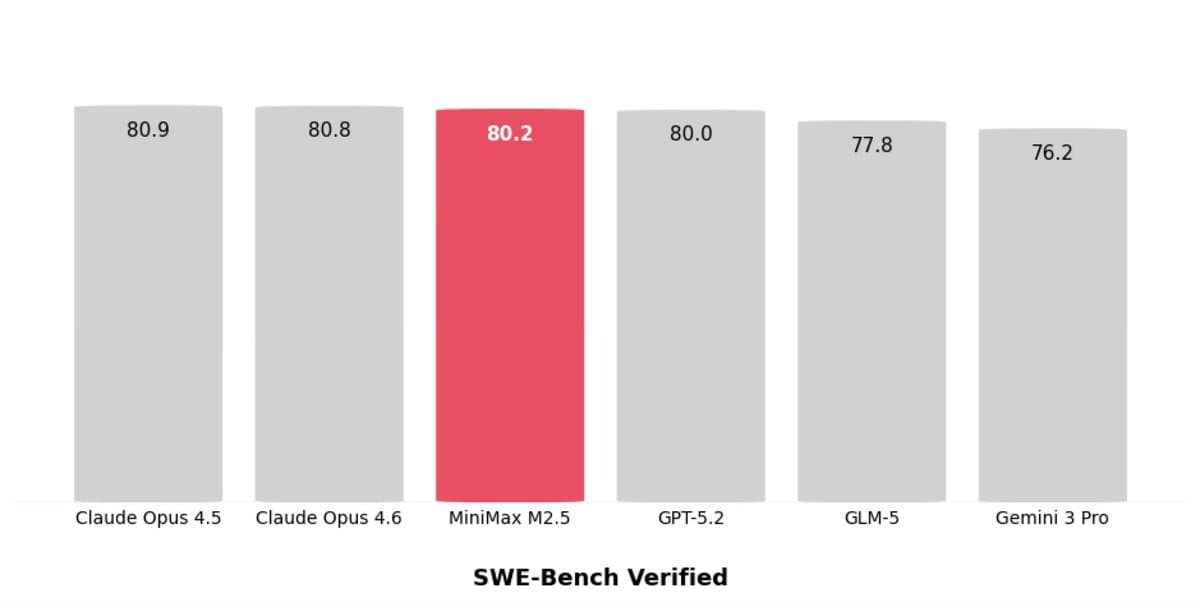
SWE‑Bench Verified Flawed Tests Reveal Data Leakage Issues
Am currently putting together an article, and yeah, the SWE-Bench Verified numbers are definitely a bit sus across all models -- the benchmark suggest they are more similar than they really are. So, I went down a rabbit hole looking into...