

February's AI Explosion: Six New Models Debut
February is one of those months... - Moonshot AI's Kimi K2.5 (Feb 2) - z. AI GLM 5 (Feb 12) - MiniMax M2.5 (Feb 12) - ByteDance Seed-2.0 (Feb 13) - Nanbeige 4.1 3B (Feb 13) - Qwen 3.5 (Feb 15) - Cohere's Tiny Aya (Feb 17) (+Hopefully DeepSeek V4 soon) Anything I forgot?

AI Should Free Experts, Not Add Extra Tasks
Yeah, in an ideal world, we would use AI to enable experts to do higher-quality work. But in the real world, they are also expected take on a wide range of additional responsibilities that detract (& distract) from their core work.
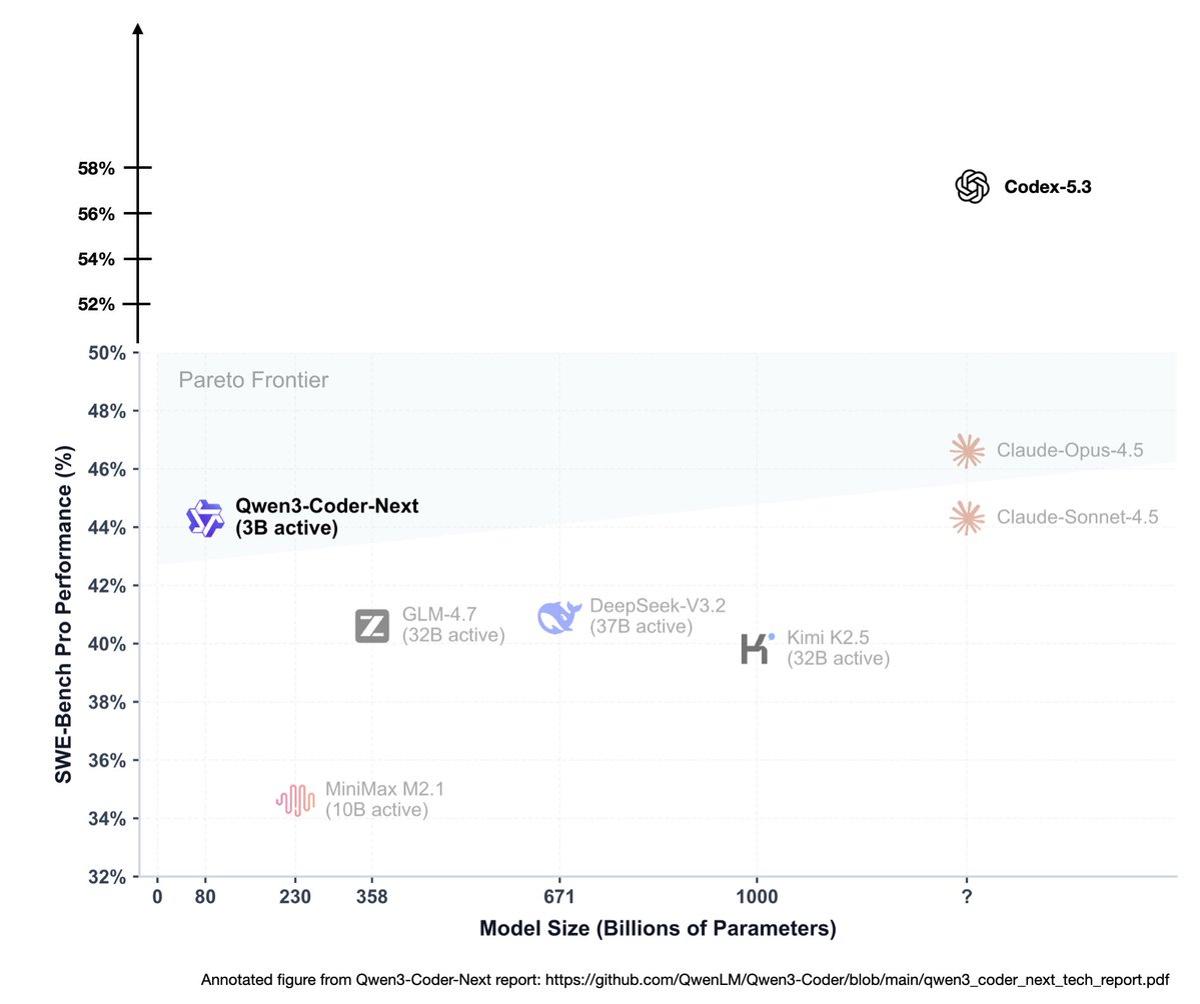
Half the Tokens, Same Performance: Efficiency Wins
> "Less than half the tokens of 5.2-Codex for same tasks" That one line already says a lot. There is no assumption anymore that compute or budget is infinite in 2026. But if you can get better modeling performance while using...

Moltbook Shows LLMs Remain Pure Next‑Token Predictors
Yes, Moltbook (by clawdbot) is still next-token prediction combined with some looping, orchestration, and recursion. And that is exactly what makes this so fascinating. (It is also why understanding how LLMs actually work really does pay off. Lets us see through the...

LLM Future: Transformers Evolve, Inference Scaling Takes Spotlight
Had a fun chat with @mattturck the other day where we talked about a bunch of interesting LLM stuff... Basically everything from the future of the transformer architecture to inference-time scaling as a recent MVP of LLM performance:
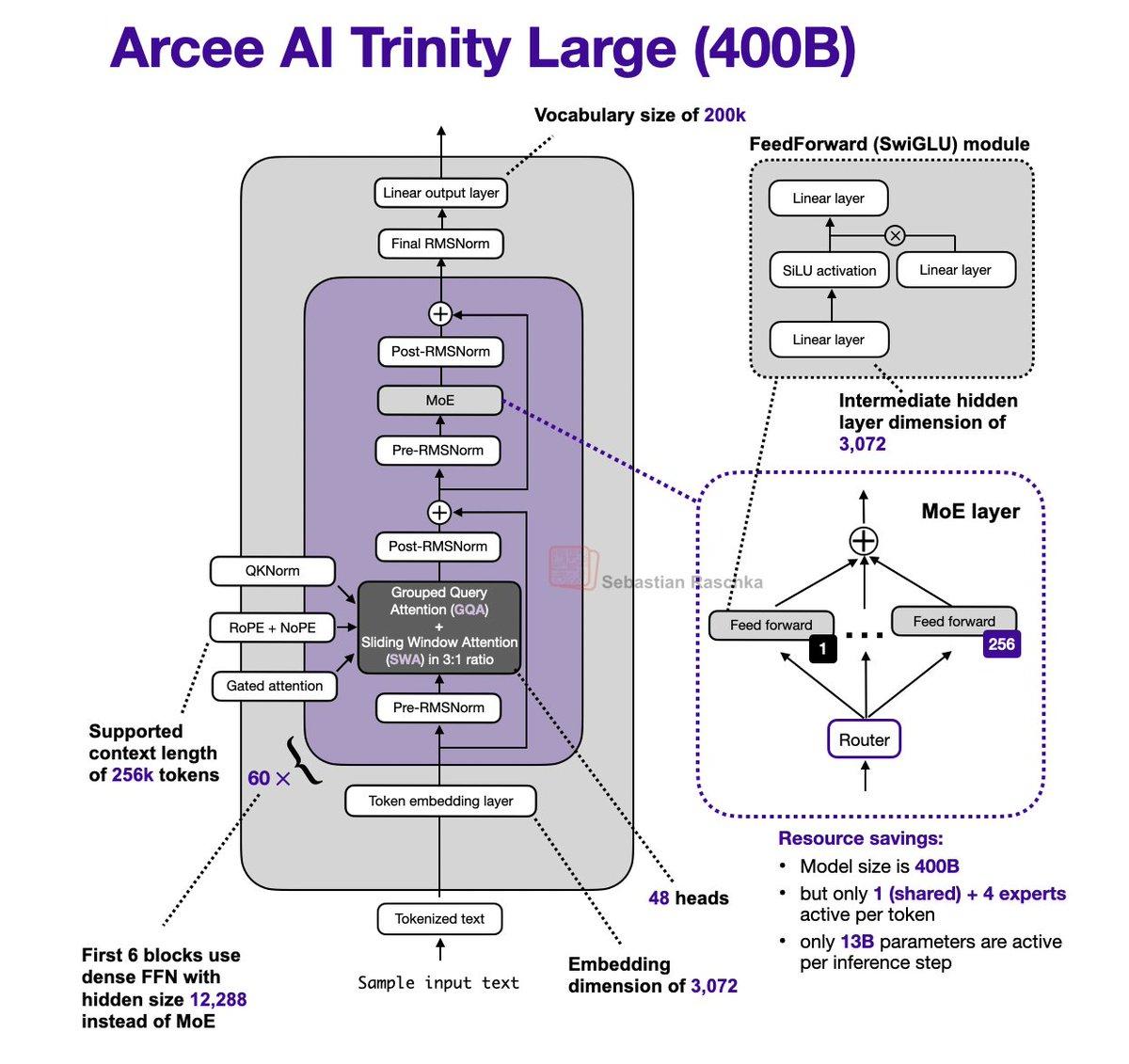
Arcee Trinity Large Merges MoE, Gated
It's been a while since I did an LLM architecture post. Just stumbled upon the Arcee AI Trinity Large release + technical report released yesterday and couldn't resist: - 400B param MoE (13B active params) - Base model performance similar to GLM...

RL Shines on Moderately Out‑of‑distribution Data
Another really interesting paper from my 2025 bookmarked papers: On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models (https://t.co/UjhiJW643U). In short, RL is most effective when applied to data that is neither too close to nor too far...

Hyper‑connections Residuals Boost Transformer Stability and Performance
Efficiency and performance tweaks in the transformer architecture usually focus(ed) on the normalization, attention, and FFN modules. For instance: Normalization: LayerNorm -> RMSNorm -> Dynamic TanH Attention: Grouped-query attention, sliding window, multi-head latent attention, sparse attention FFN: GeLU -> SiLU,...
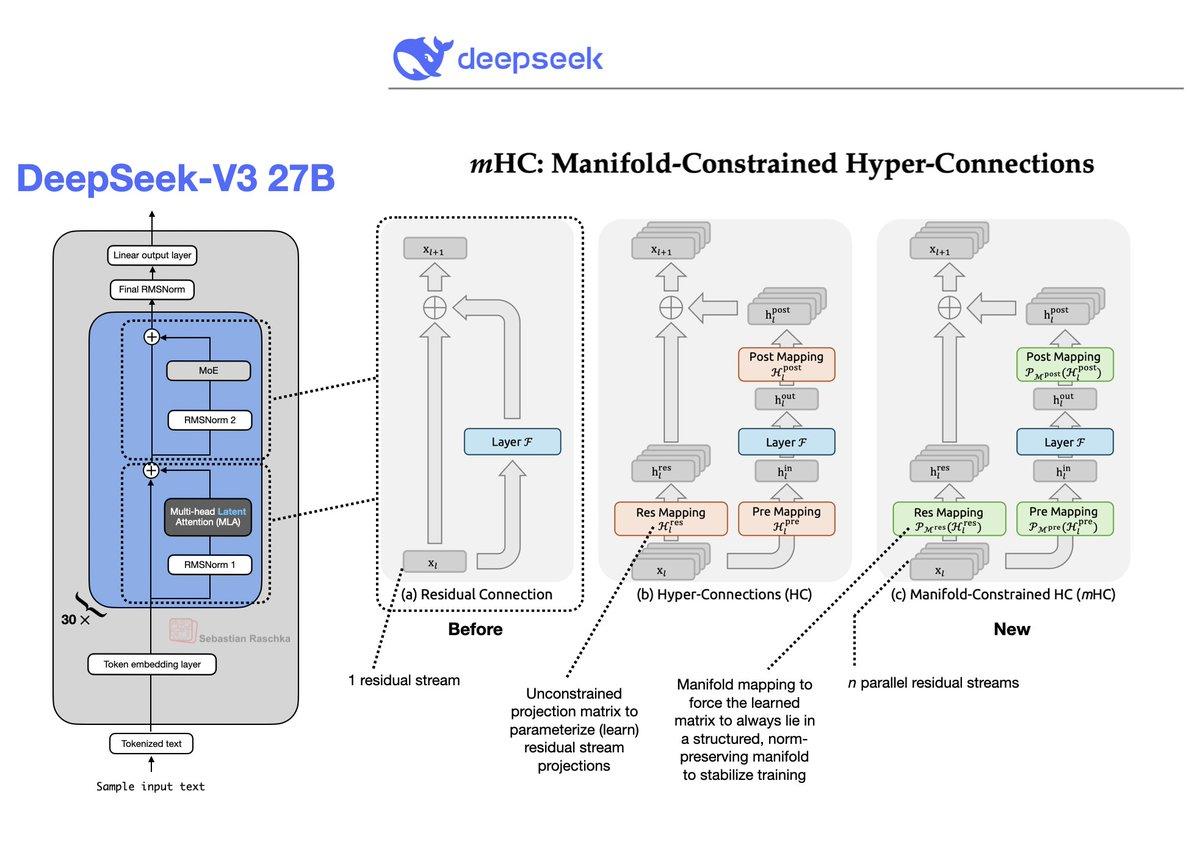
DeepSeek Introduces Residual Path Enhancements for Transformers
Efficiency and performance tweaks in the transformer architecture usually focus(ed) on the normalization, attention, and FFN modules. Well, here is a holiday gift from DeepSeek (https://t.co/ow1RpEG2Bv). Finally some improvements of the residual path as well. https://t.co/XhnZwfL5of

2025 LLMs Reach Gold-Level Reasoning, Scaling Surge
I just uploaded my State of LLMs 2025 report, where I take a look at the progress, problems, and predictions for the year. Originally, I aimed for a concise overview and outlook, but (like always) that turned into quite the...

AI Should Be a Chess Partner, Not a Replacement
Maybe a good analogy for how we should use AI in a sustainable way is chess. Chess engines surpassed human players decades ago, yet professional chess played by humans is still active and thriving. I am not a chess expert, but...

LLM Training Evolves: From Pre‑training to RLVR
The LLM training eras: 202x Pre-training (foundation) 2022 RLHF + PPO 2023 LoRA SFT 2024 Mid-Training 2025 RLVR + GRPO

NVIDIA Opens Nemotron 3 Nano: 30B MoE‑Mamba Hybrid
I really didn't expect another major open-weight LLM release this December, but here we go: NVIDIA released their new Nemotron 3 series this week. It comes in 3 sizes: 1. Nano (30B-A3B), 2. Super (100B), 3. and Ultra (500B). Architecture-wise, the models are a Mixture-of-Experts...

Updated LLM Architecture Comparison Now Covers 17 Models
If you are interested in understanding the design and components of modern LLM architectures, I have extensively grown and updated the Big Architecture Comparison article I published last summer. It grew 2x in size since then: https://lnkd.in/g-dwdPqy 1. DeepSeek V3/R1...

Mistral 3 Large Halves Experts, Doubles Their Size
Hold on a sec, Mistral 3 Large uses the DeepSeek V3 architecture, including MLA? Just went through the config files; the only difference I could see is that Mistral 3 Large used 2x fewer experts but made each expert 2x...

From Random Forests to LLMs: A 12‑Year Evolution
My biennial update to the "Hello World"s of ML & AI: 2013: RandomForestClassifier on Iris 2015: XGBoost on Titanic 2017: MLPs on MNIST 2019: AlexNet on CIFAR-10 2021: DistilBERT on IMDb movie reviews 2023: Llama 2 with LoRA on Alpaca 50k 2025: Qwen3 with RLVR on MATH-500

Join Natolambert’s NeurIPS Research Spotlight Interviews
I couldn't make it to NeurIPS this year, but I had been looking forward to the research spotlight interviews my colleague @natolambert is hosting. If you want to chat for 10-15 min to promote your work & latest research, I...

DeepSeek V3.2 Boosts Efficiency with Sparse Attention and Verifiable RL
The DeepSeek team just shared another model this week: DeepSeek V3.2. I put together a technical tour that walks through the key ideas and earlier models that led to this release: 🔗 https://lnkd.in/g9fcKkmm In the article, I cover the main...
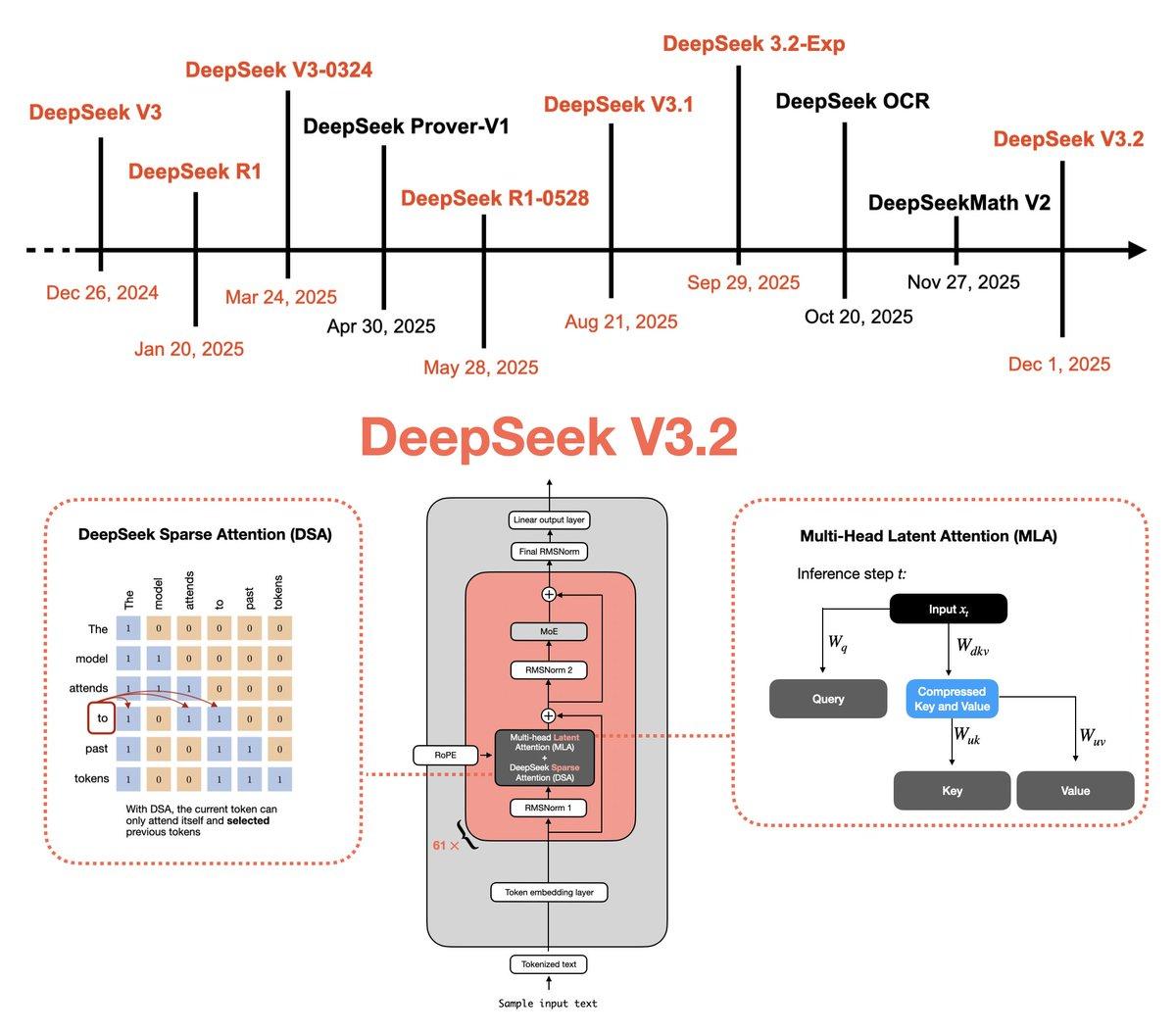
DeepSeek V3.2 Unveils Multi‑Head Latent Attention Evolution
This interesting week started with DeepSeek V3.2! I just wrote up a technical tour of the predecessors and components that led up to this: 🔗 https://t.co/JSAd9cx2s6 - Multi-Head Latent Attention - RLVR - Sparse Attention - Self-Verification - GRPO Updates https://t.co/5f965hR70I
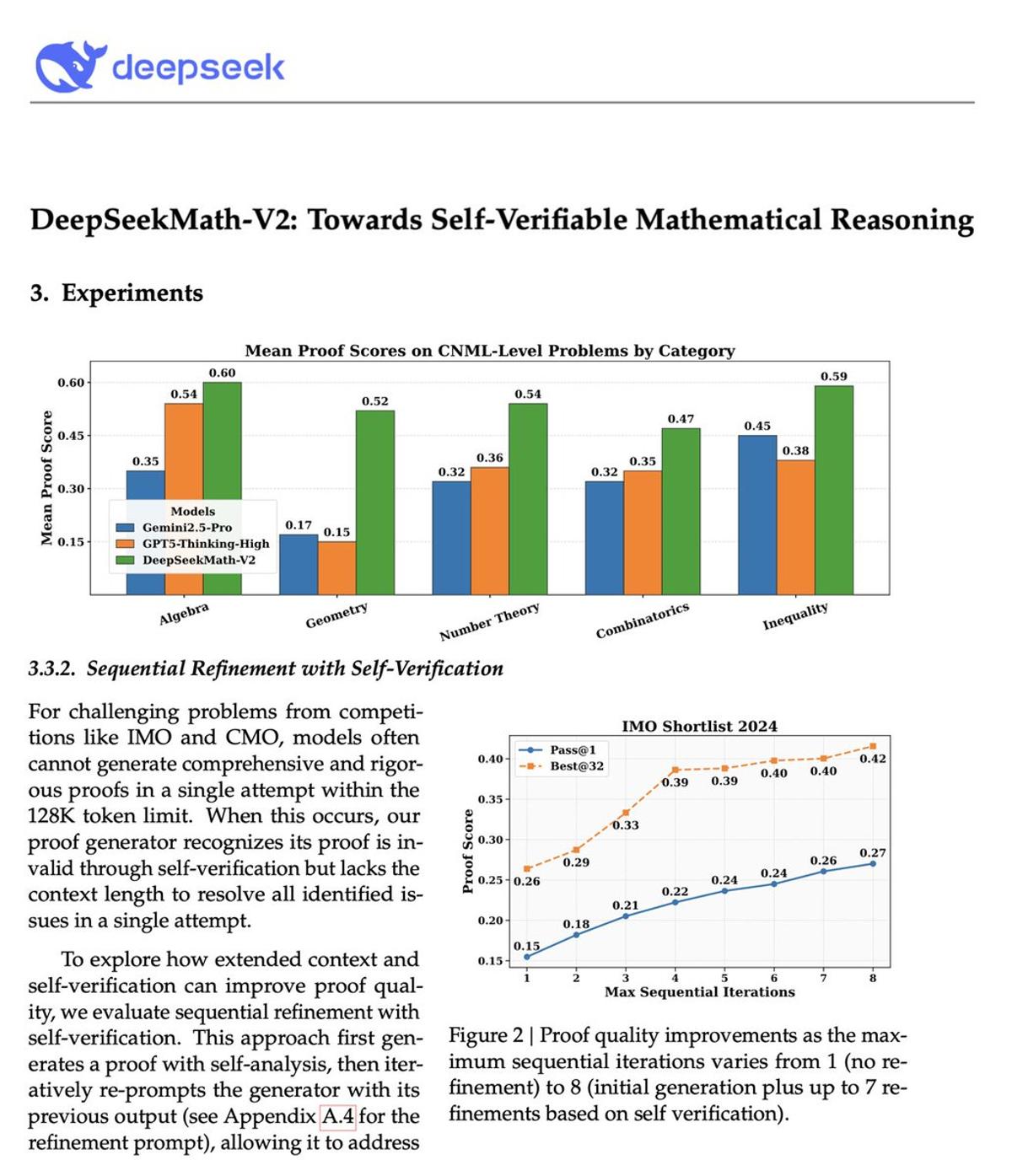
DeepSeek Model Hits Gold on IMO 2025, Boosts Self‑Refinement
Looks like we got a new DeepSeek model over the holidays (again) Basically pushes RLVR & self-refinement to gold-level scores on IMO 2025. Coincidentally, I am currently working on the self-refinement chapter, and this comes in handy as a nice, scaled-up case...

Inference Scaling Boosts LLM Accuracy From 15% to 52%
As we head into a long weekend, some of you may be looking for reading material. Good news is that Chapter 4 on inference scaling was just released earlier this week! This chapter introduces the core ideas behind inference scaling...

Comparing GPT‑5.1‑Codex to GPT‑5.1‑Codex‑Max
@pagilgukey @JohnThilen @dwarkesh_sp @ilyasut Yes. With Codex I meant GPT-5.1-Codex versus GPT-5.1-Codex-Max

Spare Compute Needed to Accelerate Idea Testing
In some way, scaling is holding back progress. And either way these mega-size clusters are going to be useful. Right now, most of the capacity is used to do a crazy large run + serving existing customers. It would be good...

AI Breakthroughs Now Arrive in Just Five Years
@w3whq @kenwarner GANs were 2015ish, Denoising Diffusion Probabilistic Models were 2020ish, aka 5 years later. Timeline expectations are crazy these days!

GPT-5 Expected to Be Smaller Than GPT-4.5
@JohnThilen @dwarkesh_sp @ilyasut In addition, and that’s the important point, I think GPT-5 is smaller than GPT-4.5.

GPT‑5.1 and Gemini 3 Variants Share Identical Core Model
@JohnThilen @dwarkesh_sp @ilyasut I am speculating that all GPT-5.1 models (instant, thinking, Pro) are the same model but with different inference scaling budgets. Same for GPT-5 Codex. And Gemini 3 Pro and Gemini 3 Deep Think are probably also the same...

Scaling Pre‑training Hits Diminishing Returns for Future Generations
@GiorgioMantova @dwarkesh_sp @ilyasut I’d say this is the jump from last gen to current gen, but I think the argument is that further improvements will fizzle out in the next gen if we keep scaling pre-training. Ie it won’t give...

Scaling Boosts Benchmarks, Not Genuine Problem‑solving Ability
I think it is somewhat true though that scaling helps with benchmark performance but not necessarily with with new model capabilities. Like the example he mentioned > U: "Please code xyz." > M: "Ok here is xyz." > U: "You have a bug." >...

Beyond Scaling: Engineering Tricks Now Drive AI Progress
@dwarkesh_sp @ilyasut “The Age of Scaling is over.” I agree with that. Basically, since GPT 4.5 a lot of the perceived real-world progress was driven by clever engineering wrappers (context filtering, inference scaling, multi-turn tricks, retrieval, tool use, etc).

Seeing Benchmaxxing, Ilya Launches Company for Proper LLM Development
Ok, so what Ilya saw was extreme benchmaxxing, which in turn prompted him to create his own company to do LLM development the proper way?! Makes sense, I sympathize with that.
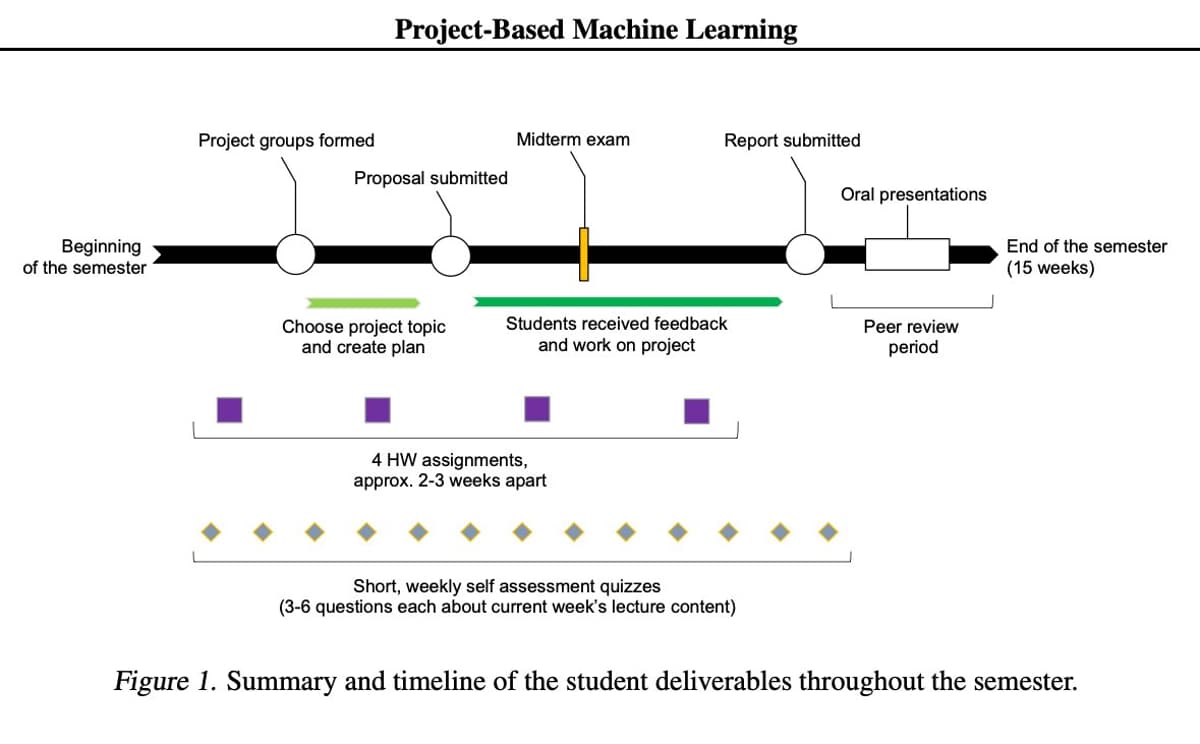
Assume AI on Take‑home Exams; Avoid Knowledge‑based Tests
In my classes, a big portion of the grade was HW and project-based (https://t.co/gDwMlp0iwV) but I still had to include traditional exams. And then, during COVID, we had to redesign the exams so that students can take them at home. It...
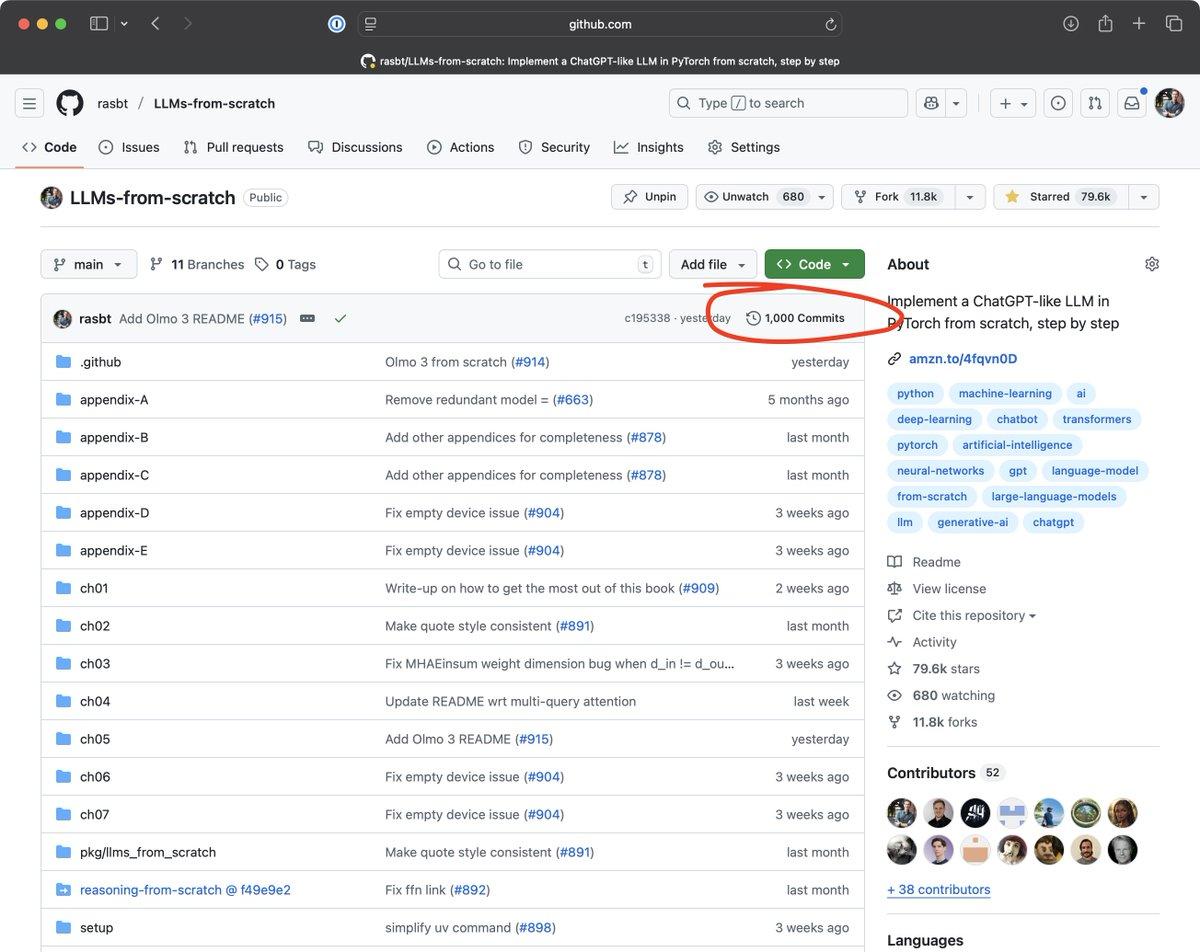
LLMs‑from‑scratch Hits 1,000 Commits on Monday
Just a regular Monday morning. Saw that LLMs-from-scratch got its 1000th commit. Feels a bit surreal 🤯😊 https://t.co/n3EWkoEMHp

Olmo 3 Shows Transparent Architecture with Sliding‑Window Attention
There have been lots of interesting LLM releases last week. My favorite was actually the Olmo 3 release. Olmo models are always a highlight since they are fully transparent (including training methods and datasets) and come with very detailed technical...
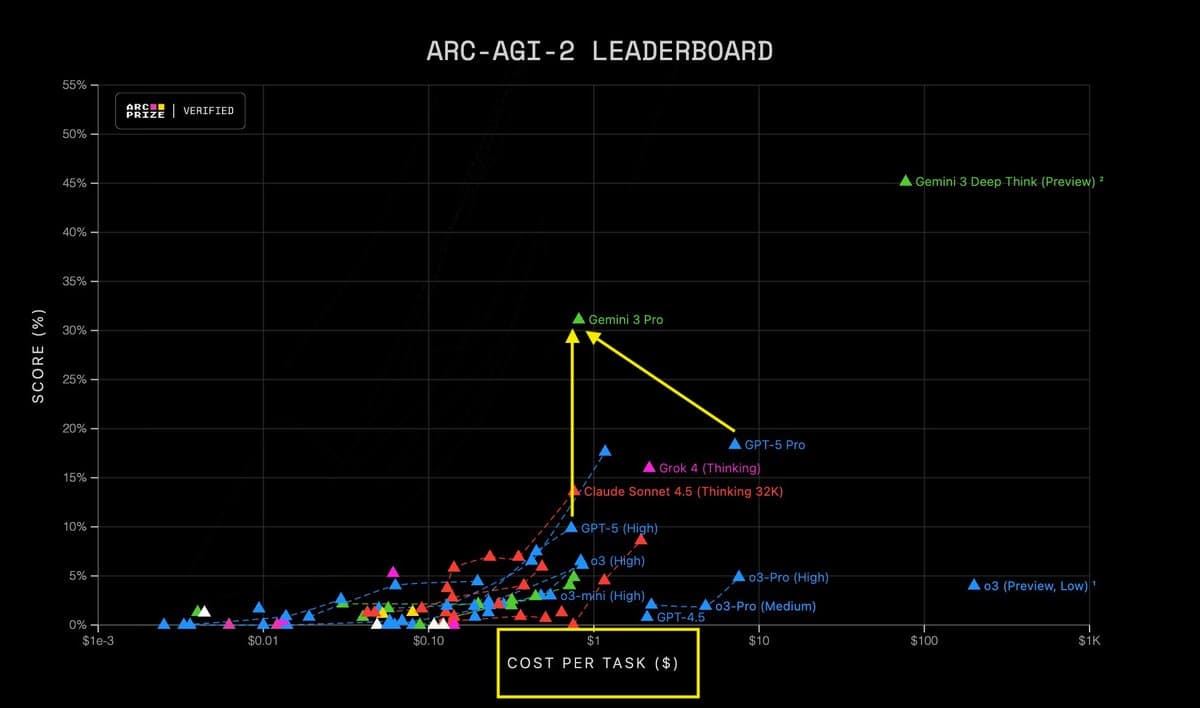
Own Hardware Pipelines Enable Aggressive, Low‑cost Inference Scaling
Wanted to say this is because the competition focused on cheaper models. But that eve doesn't seem true. What seems more plausible is that teams with strong training pipelines and their own hardware can push much more aggressive inference-time scaling at...
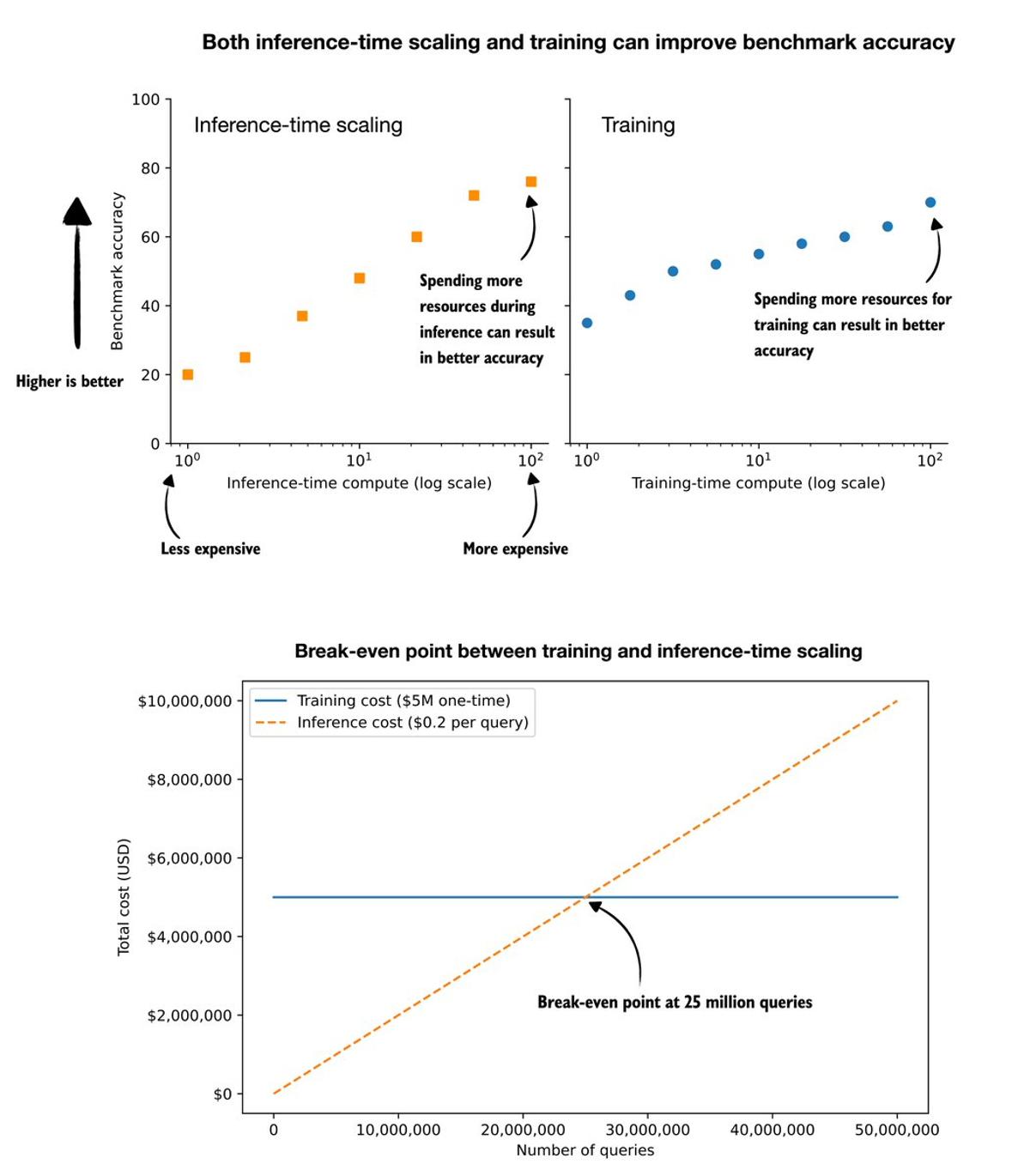
Training Vs. Inference: Break‑Even at 25 Million Queries
What should we focus on, (more) LLM training or inference scaling? (A question I got asked multiple times now, so here are some thoughts.) Training is usually very, very expensive, but it is a one-time cost. Inference-scaling is comparatively cheap, but...

Inference Scaling Boosts LLM Accuracy From 15% to 52%
Inference-scaling lets us trade extra compute for better modeling accuracy. Next to reinforcement learning, it has become one of the most important concepts in today's LLMs, so the book will cover it in two chapters instead of just one. I...

Read Offline First, Then Code to Master LLM Books
I often get questions from readers about how to read and get the most out of my book(s) on building LLMs from scratch. My advice is usually based on how I read technical books myself. This is not a one-size-fits-all...

Read Offline First, Then Type and Run Code
I often get questions from readers about how to read and get the most out of my book(s) on building LLMs from scratch. My advice is usually based on how I read technical books myself. This is not a one-size-fits-all...

Key LLM Architecture Insights in 25‑Minute Talk
My "The Building Blocks of Today’s and Tomorrow’s Language Models" talk at the PyTorch Conference is now up on YouTube! https://t.co/bGV5w1Aqyq If you have 25 min this weekend, it's a whirlwind tour to catch you up on the key LLM architecture...
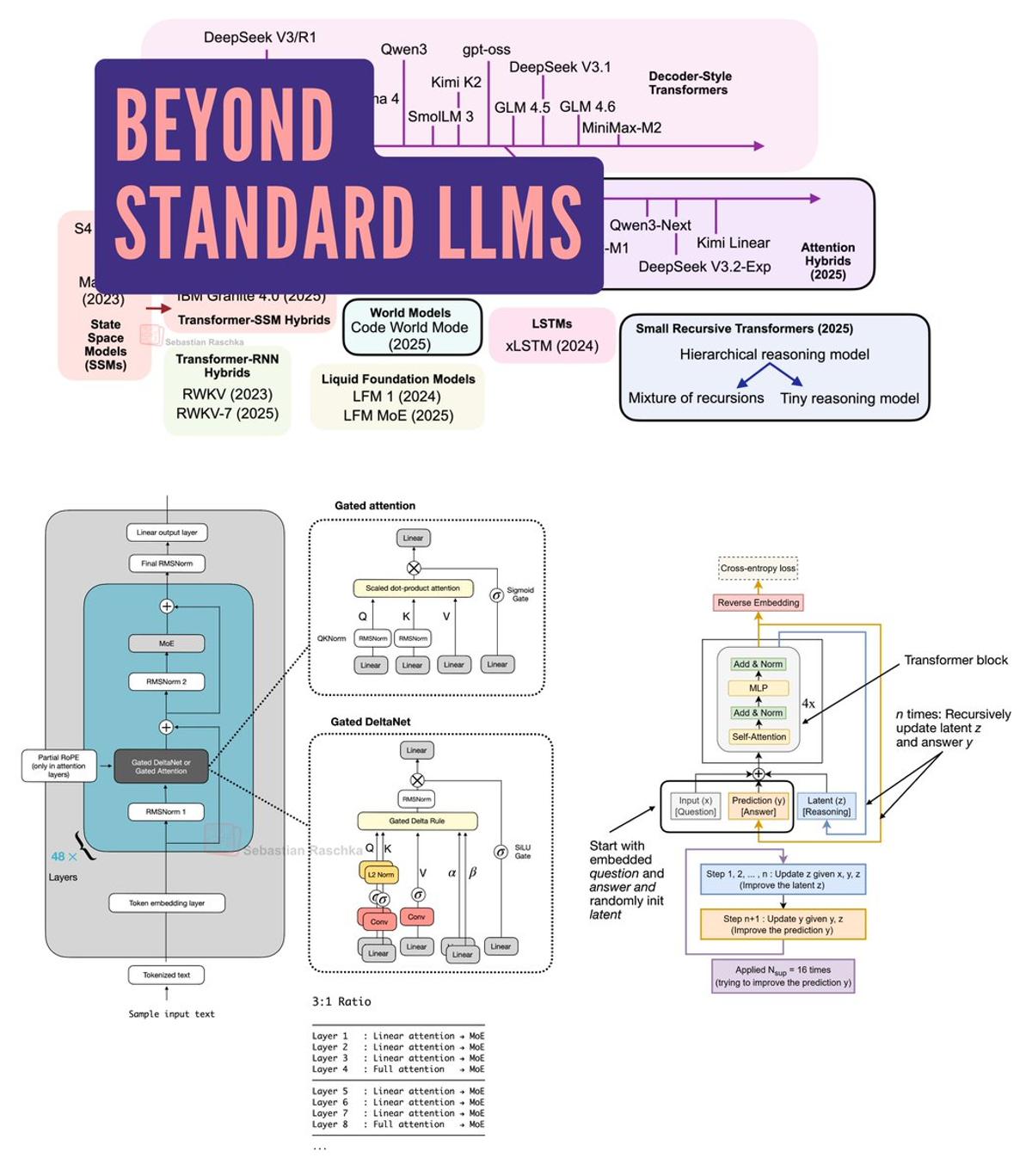
Exploring Emerging Alternatives to Standard Large Language Models
My new field guide to alternatives to standard LLMs: Gated DeltaNet hybrids (Qwen3-Next, Kimi Linear), text diffusion, code world models, and small reasoning transformers. https://t.co/ZpWugAccgQ https://t.co/255yQXaDcM
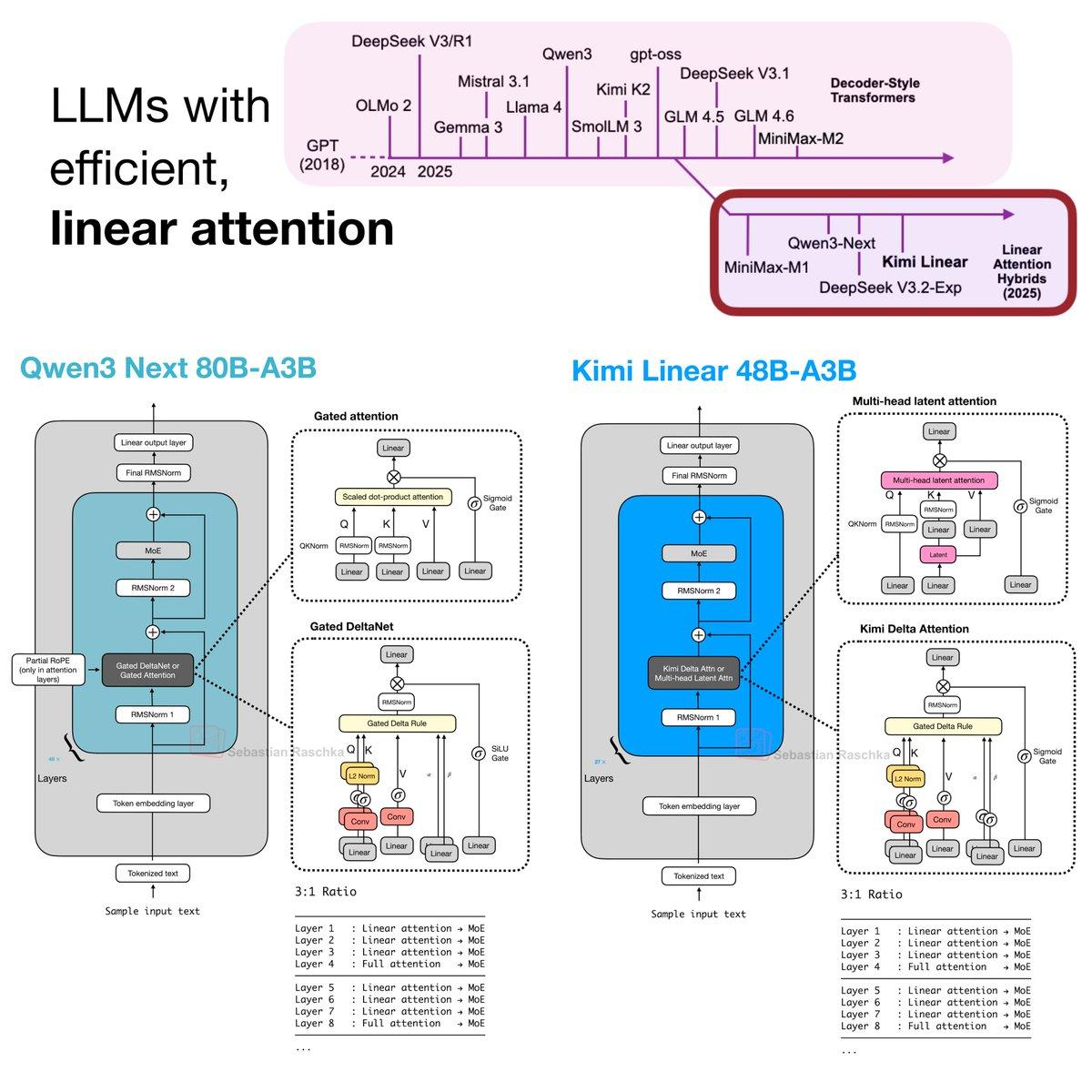
Linear Attention Makes a Comeback with Efficient LLMs
With the release of the Kimi Linear LLM last week, we can definitely see that efficient, linear attention variants have seen a resurgence in recent months. Here's a brief summary of what happened. First, linear attention variants have been around for...

Fp16 Viable with Proper Normalization; Bf16 Still Safer
I ran lots of experiments on fp16 vs bf16 years ago on ViTs and LLMs. fp16 can work well but depends on normalization (so you don’t run over the supported range with your activations). I can see why with QKNorm...
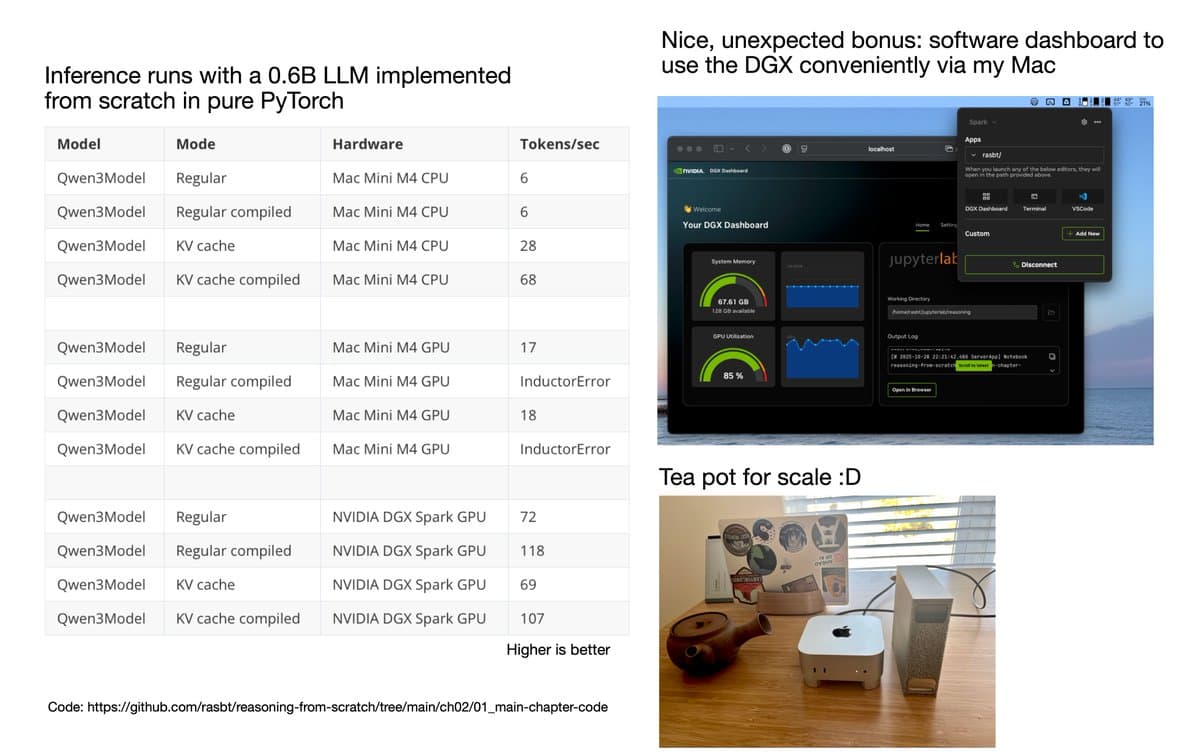
DGX Beats Mac Mini, Offers Seamless NVIDIA Sync Setup
A small follow-up to my DGX Spark post. Courtesy of NVIDIA, I got to try the DGX on my workflows (coding LLMs from scratch in pure PyTorch) and wanted to share my first impressions after using it for a week. Before...

Testing Inference-Scaling Techniques to Shape Upcoming Chapter
On that note, I am currently running a large-scale experiment on the upcoming inference-scaling chapter: A) Parallel Sampling - Self-Consistency (Majority Vote) - Rejection Sampling - Best-of-N (Verifier-Based) B) Sequential Refinement - Self-Refinement - Power Sampling - MCMC (Simple) - MCMC (Block as in "Reasoning with Sampling" paper) - Tree-of-Thought ......
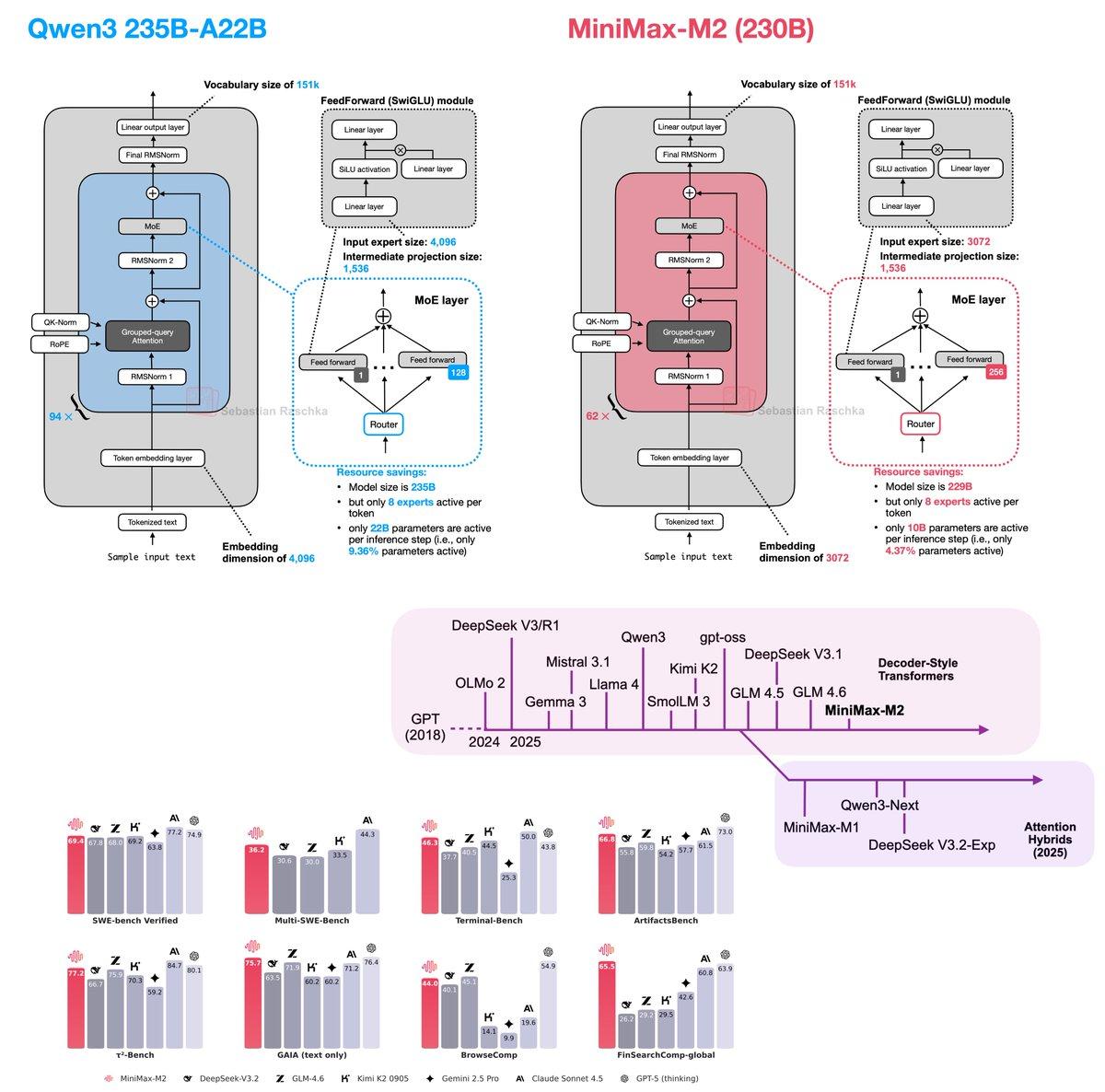
MiniMax-M2 Boosts Performance with Full Attention and Per‑Layer QK‑Norm
Just saw the MiniMax-M2 benchmarks, and the performance is too good to ignore :). So, I just amended my "The Big LLM Architecture Comparison" with entry number 13! 1️⃣ Full attention modules: As shown in the overview figure below, I grouped...
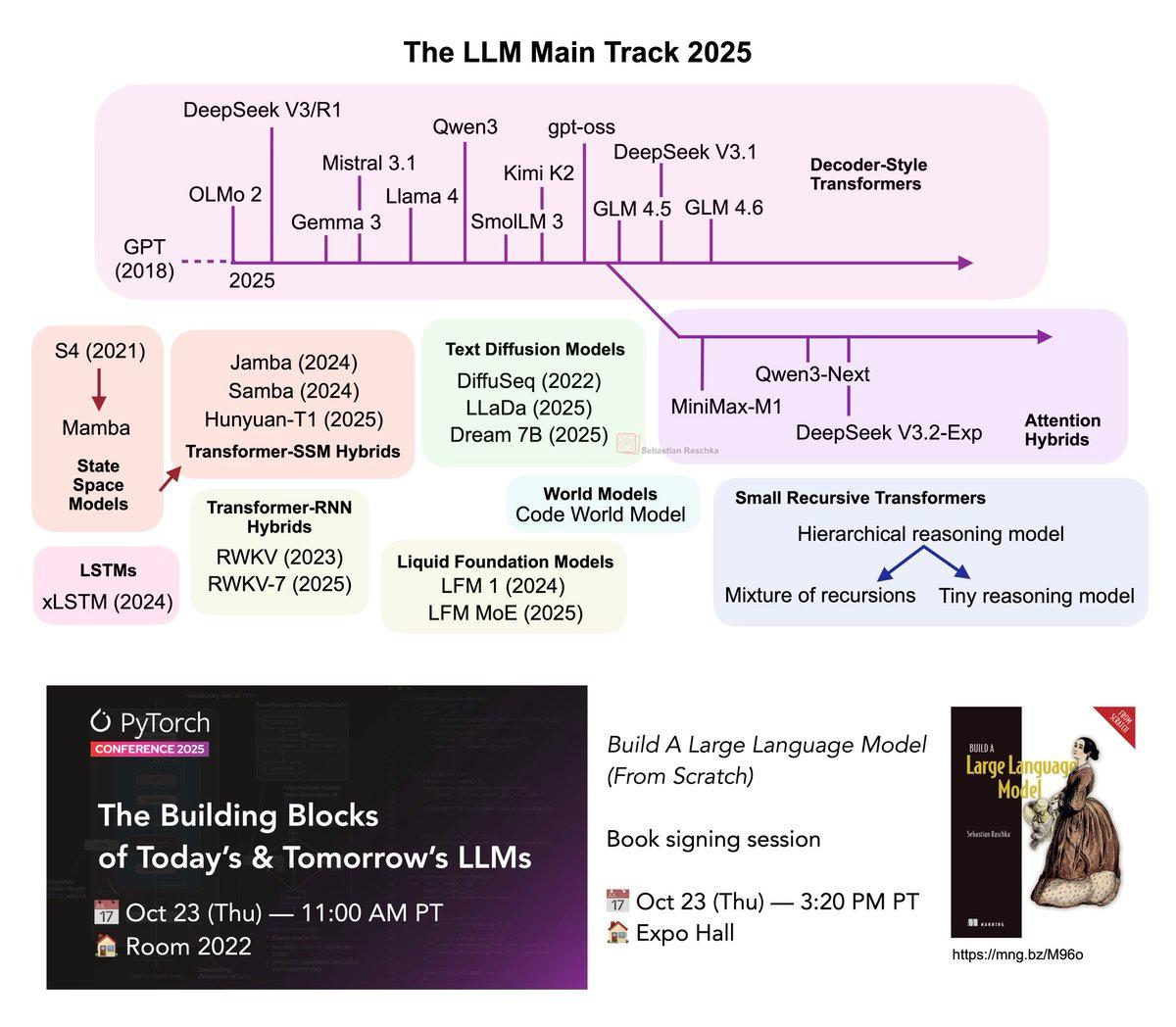
Presenting 2025 LLM Landscape at PyTorch Conference
Excited to be (finally) heading to the PyTorch Conference! I’ll be giving a talk tomorrow at 11:00 AM on “The LLM Landscape 2025”, where I’ll discuss the key components behind this year’s most prominent open-weight LLMs, and highlight a few architectural...
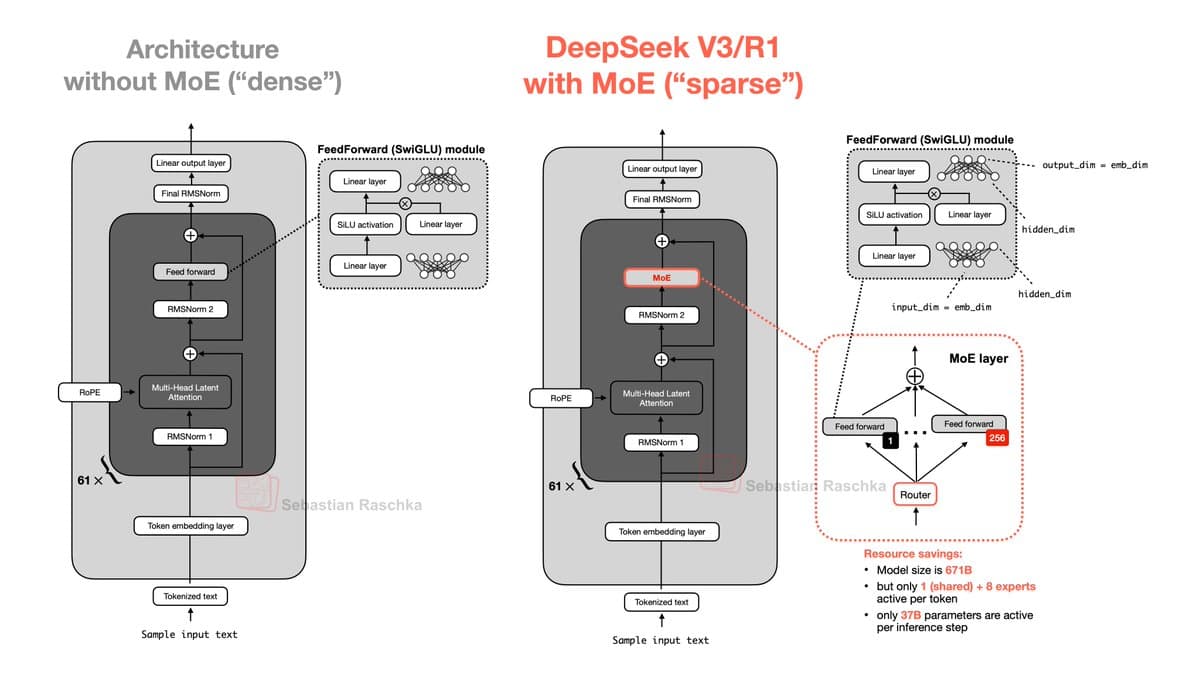
Explore the Power of Mixture of Experts (MoE)
🔗 Mixture of Experts (MoE): https://t.co/3CGjgO4H9p https://t.co/QA12nBeW0i

New Chapter Releases Symbolic Verifier for LLM Evaluation
Chapter 3 on building a symbolic verifier for LLMs from scratch is now live: https://mng.bz/lZ5B . And with this, the first 176 pages of Build A Reasoning Model (From Scratch) are now available. This verifier is a useful method for...
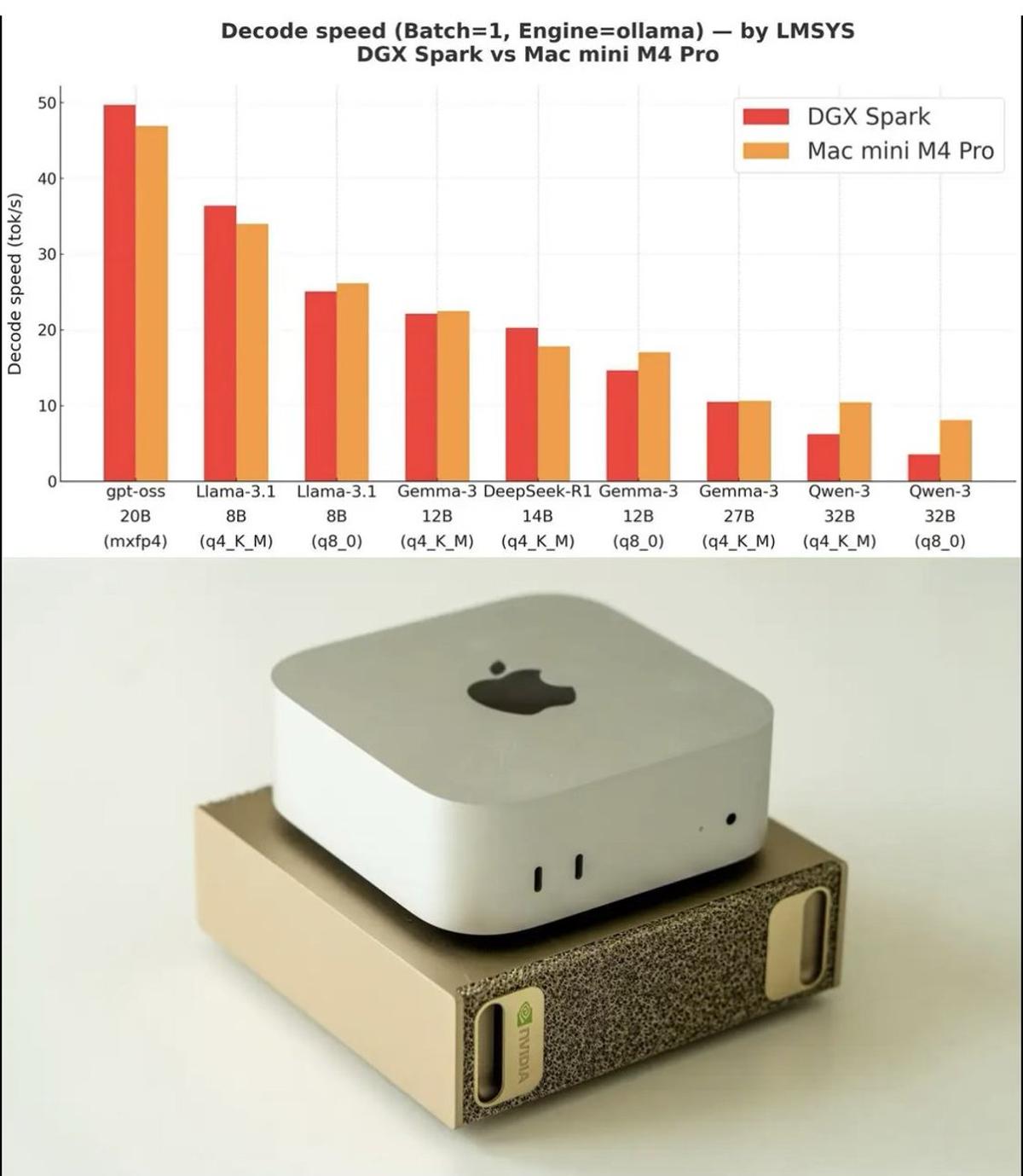
Mac Mini Excels at Inference; DGX Spark Needed for Fine‑tuning
Saw that DGX Spark vs Mac Mini M4 Pro benchmark plot making the rounds (looks like it came from @lmsysorg). Thought I’d share a few notes as someone who actually uses a Mac Mini M4 Pro and has been tempted...

Launch of Readsail: Curated AI Learning Platform
If your company wants to help employees stay up to date with AI, I've teamed up with @natolambert and others to launch @readsail. It's essentially a platform that makes it easy to manage ongoing AI learning and brings you a...