Why Blue-Green Deployments Fail at Scale in Kubernetes — and What Works Instead
Companies Mentioned
Why It Matters
Understanding the limits of blue‑green at scale helps organizations avoid costly resource waste and rollback failures, guiding them toward more efficient progressive delivery practices.
Key Takeaways
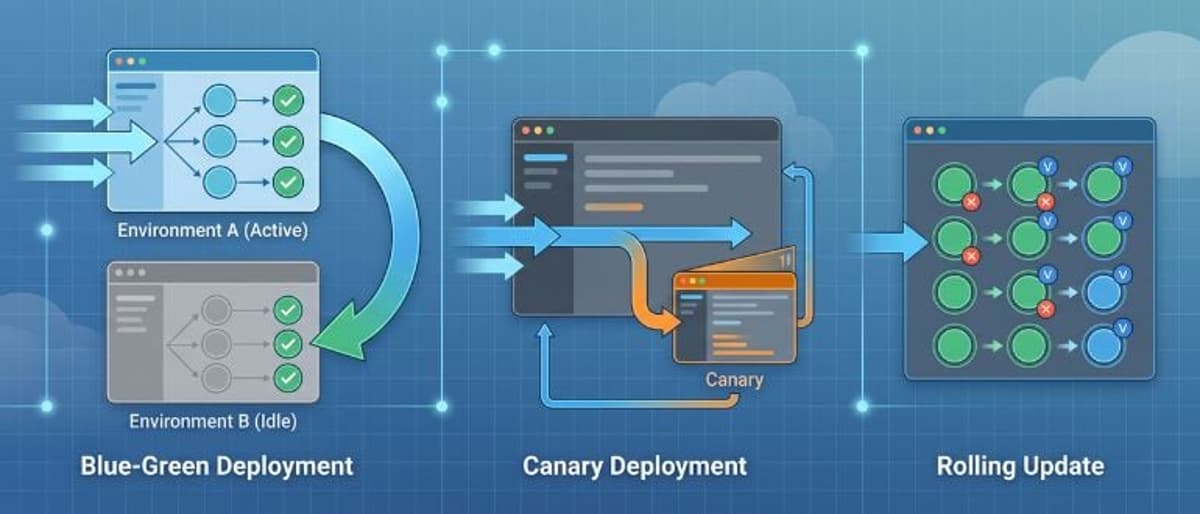
- •Blue‑green doubles resource usage, making it costly for large clusters
- •Shared databases require backward‑compatible migrations to avoid rollback failures
- •Long‑lived connections like WebSockets break when traffic is switched
- •Canary releases provide real‑traffic validation with minimal blast radius
- •Feature flags separate code deployment from user exposure, simplifying rollbacks
Pulse Analysis
Deploying at Kubernetes scale forces teams to confront the hidden costs of blue‑green strategies. Maintaining two full production environments not only doubles compute and memory spend, but also creates a testing gap when the idle tier runs at reduced capacity. Moreover, shared stateful components—databases, caches, message queues—cannot be switched with traffic, demanding backward‑compatible schema changes and complex data reconciliation. Long‑lived protocols such as WebSockets or gRPC streams are abruptly terminated, eroding user experience unless applications adopt stateless session handling or external session stores.
Progressive delivery tools offer a more nuanced approach. Rolling updates, the native Kubernetes mechanism, replace pods incrementally without incurring duplicate resource costs, making them suitable for backward‑compatible changes where a few minutes of rollback time is acceptable. Canary deployments add a safety net by routing a small traffic slice to the new version, allowing real‑world validation against concrete metrics before a full rollout. Feature‑flag platforms further decouple code rollout from feature exposure, enabling instant rollbacks at the flag level and reducing reliance on heavyweight deployment tactics. Together, these methods form a decision framework that aligns risk tolerance, release cadence, and team maturity.
The tooling landscape now supports this hybrid model. Argo Rollouts and Flagger provide native Kubernetes canary and scoped blue‑green capabilities, while service meshes like Istio or Linkerd handle fine‑grained traffic splitting. GitOps solutions such as Flux and Argo CD automate the delivery pipeline, and flag management services like LaunchDarkly or Unleash give product teams granular control over feature exposure. By combining rolling updates, canaries, and feature flags, organizations can achieve rapid, reliable releases without the prohibitive overhead that pure blue‑green deployments impose at scale.
Why Blue-Green Deployments Fail at Scale in Kubernetes — and What Works Instead
Comments
Want to join the conversation?
Loading comments...