
Stabilized Kubernetes Production by Optimizing Scaling and Monitoring
I was about the biggest problem at work related to my role which I have resolved? One of the biggest challenges I resolved involved recurring production instability in a Kubernetes environment supporting customer-facing applications. The platform experienced intermittent downtime due to resource exhaustion, inefficient scaling policies, and lack of proper monitoring visibility. I led the investigation by analyzing cluster metrics, application logs, and infrastructure utilization patterns.
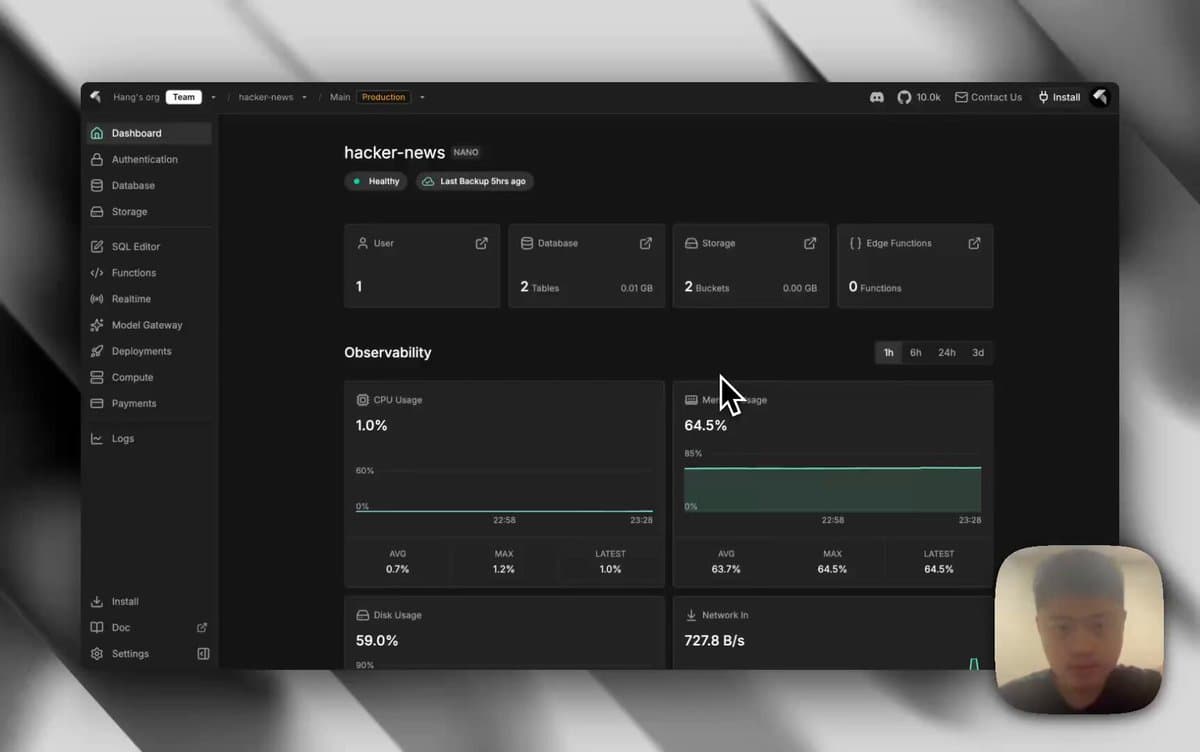
InsForge Lets Coding Agents Manage Full Backend Infrastructure
.@InsForge turns your coding agent into a principal backend engineer. Backend servers, database, LLM gateway, frontend deployment, and more. Every primitive built for how coding agents actually work, so they can run your entire infrastructure. Congrats on the launch, @hanghuang_ &...
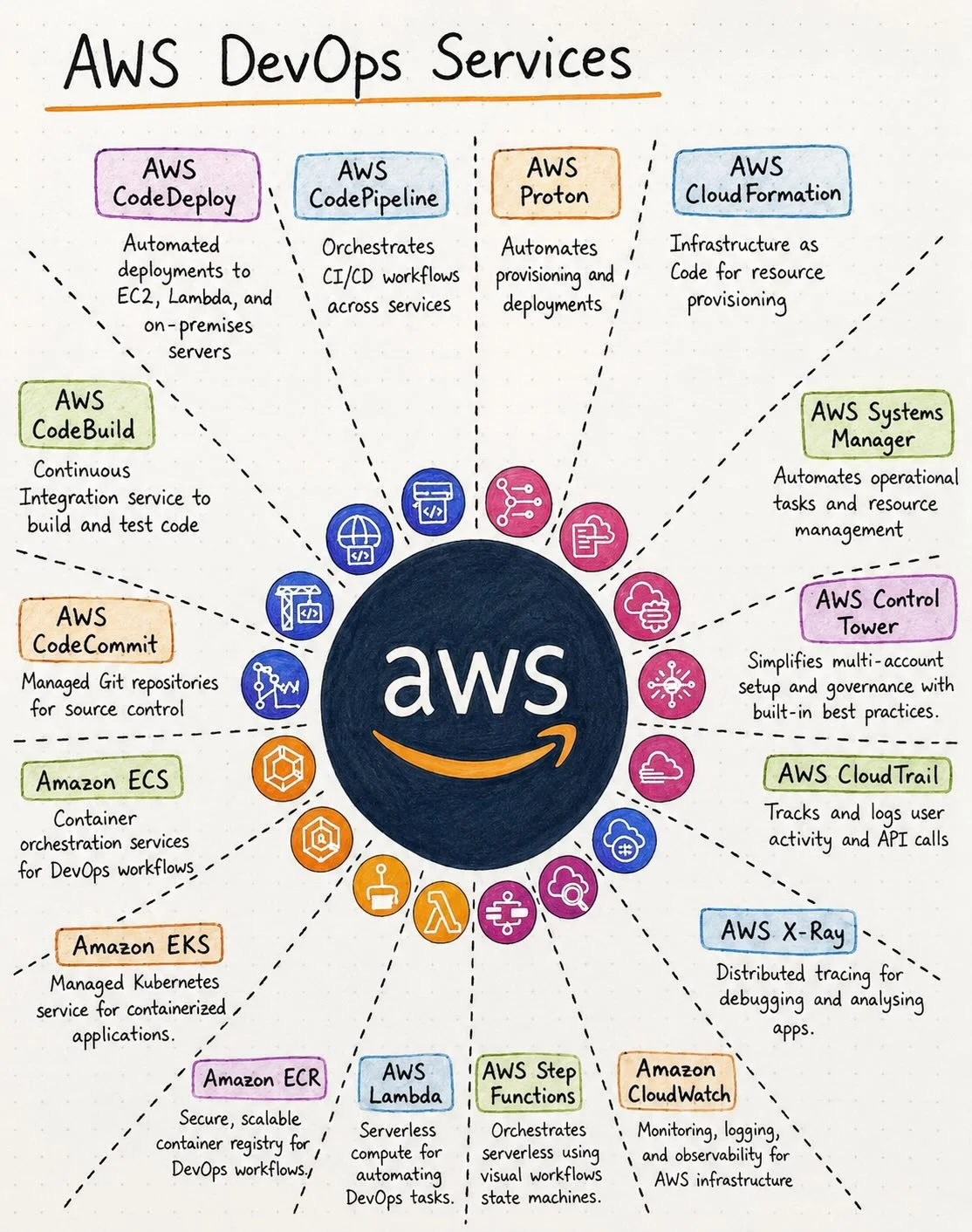
Essential AWS DevOps Tools Every Cloud Engineer Needs
AWS DevOps services every cloud engineer should know ☁️⚙️ CI/CD, containers, serverless, monitoring, IaC, and automation — all in one roadmap. 🚀

AI‑written Code Meets On‑call Chaos—Rootly Saves Production
🤖 Half your codebase was written by AI. 👤 The other half by someone who left two years ago. Guess who's on-call when it breaks. New video on Rootly AI SRE - the partner that's got your back when prod goes down. 👇 Link...

Streamlining to ~20 Essential SaaS Providers
Wavespeed for GPU (Photo AI + Interior AI) Cloudflare for R2 storage and domain renewal xAI for LLM AI API for all my sites Backblaze for backups Hetzner for VPS Scrapingbee for scraping (mostly for Hotelist) Google Cloud (also for Hotelist) NameCheap (for like 4 domains left...

AI Makes Exhaustive Testing Affordable, Not Just Faster
It's not that AI lets you write code faster. Plenty of people have noticed that. It's that AI lets you verify at a level that was previously too expensive to sustain. The 90% testing threshold is magical, but it used...

Mythos Finds Just One Real Curl Vulnerability Amid False Positives
The developer of curl tried using Anthropic’s Mythos to find security vulnerabilities. While it flagged 5 issues, 3 were false positives and 1 just a regular bug. So it only found 1 real security issue. That said curl already uses multiple...

SessionStart Hook Cuts Token Usage by Half
The nav-start skill used to make 6 Read calls at session start. Replaced them with a Claude Code SessionStart hook that injects state via additionalContext — before the first user turn. Same data, zero reads, ~35k tokens saved per session 🔥 Measured: 73.3k →...

Plan Load Balancers for Future Spikes, Not Current Traffic
Load balancers are one of those things you don't think about until traffic spikes. Then you're very grateful someone thought about it in advance. Design for the traffic you want, not the traffic you have.

Enterprise DevOps Needs SaaS‑Style Feedback and Product Thinking
RT Enterprise DevOps can't just ship faster. Learn from SaaS: continuous feedback loops, tight customer alignment, and product thinking around platforms. #DevOps #SaaS @Star_CIO https://t.co/e4TERhpY2r

Ship Code in Minutes with Gemini CLI Abstraction
Ship code within minutes with the Gemini CLI DevOps Extension https://t.co/gB69hhqVPX < CI/CD has to change, right? Until we figure out what that really looks like, I'll take abstractions that translate intent to infrastructure.

Amazon Quick Auto-Selects Optimal Models, Freeing IT Teams
The complexity of model selection is growing. Amazon Quick’s ability to self-optimize and select the best-fit model for a task allows IT teams to focus on outcomes rather than backend orchestration. https://t.co/DnLd1tKYSx #CIO #WhatsNextWithAWS #AI #Cloud #ITOps

SRE Wasn't Google Search’s Silver Bullet
We like to say there is "no silver bullet" in software engineering: a technology or management technique that by itself promises an order of magnitude improvement in productivity, in reliability, in simplicity." So tell, me what was SRE for Google Search...

Scalable Infrastructure Starts with Early Assumption Documentation
The difference between infrastructure that scales and infrastructure that doesn't: The decisions made before it needed to scale. Think ahead. Document your assumptions. Revisit them.

Shared Observability Unites SOCs and DevOps
RT SOCs and DevOps will need shared observability for agents: data access, tool calls, MCP interactions, and risk levels in one view. #Security #DevOps @Star_CIO https://t.co/tRGwCPc4Mb