

Bigger LLMs Excel: GPT‑5.5 Tops Negotiation Benchmark
One of the most important properties of LLMs that we take for granted is that newer, bigger models are just better at everything. The AI Labs are pouring effort into economically valuable fields like coding, but bigger models are also better at negotiation, alignment, poetry, etc

Open AI Use Needed as Citation Hallucinations Surge 12‑fold
This seems like a critical reason to open up about AI use in academia. Scholars are using old AI models, badly, and not talking about it. New models hallucinate very few citations, and good agentic harnesses drop that further. Being...

AI Prompts Mask Low-Quality Writing, Flooding Platforms
This is going to get even worse as people realize that careful tuning in their prompts can make AI writing seem not like AI writing to readers. We expect word counts to align, in some way, with thinking & value. Writing...

Enterprises Demand Roadmap; Labs Push Exponential AI Scaling
Enterprises are going to actually want a coherent roadmap for the development of tools like Codex and Cowork, so they can plan and train and scale their use. This conflicts with the Labs’ vision where these tools rapidly scale exponentially in...

AI Is No Longer Exclusive to San Francisco
I think we are past the point where “only people in San Francisco get AI” is true. AI users are in every industry & they have access to the same models. SF is far from the epicenter of many of...

Humanizing Claude May Shape AI’s Future Impact
The personification of Claude — in name (the only AI with a human one), in training, in Anthropic’s philosophy (see Claude Constitution), in fanfiction (see the Claude cartoons), etc — feels quite consequential in the medium term, for better and...

Apple’s New Siri Aims to Match AI Assistants
Apple may be planning to role out its updated Siri based on 2024's vision at the moment when Claude Code and Codex (also OpenClaw) can increasingly do the actual assistant thing: read my emails & calendar, proactively spot & solve...

AI Models Still Stuck in 2022 Mindset
I suspect there was a moment, probably 2022-2023, where anything you wrote publicly about AI that was popular is likely to still have influence over current models. Since then, the open internet has become less key to training but...

Robotics Lacks Reliable Benchmarks Compared to AI Progress
As much as the state of benchmarks in AI is flawed, it is so much easier to track AI progress than robotics. Not sure what you can make of all the videos of robots running races or doing laundry -...

Mythos Hype: No AI Miracle, but It Found Exploits
I realize that “Mythos as hype” means two different things to different groups. For insiders, it means “Mythos was not a magical step-change in AI ability.” For outsiders, it means “Mythos couldn’t really find zero day exploits” The latter was wrong,...
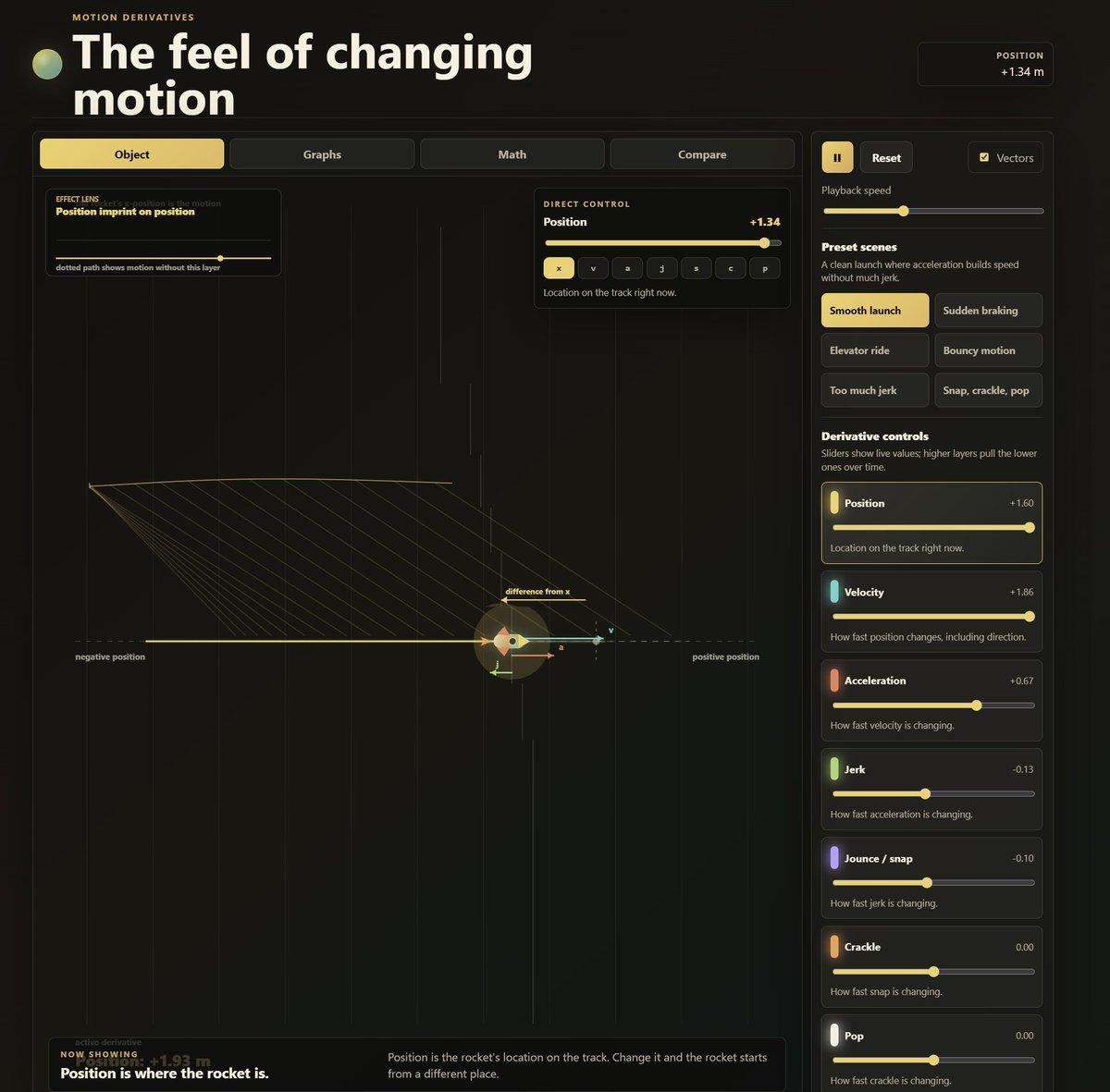
Explore Snap, Crackle, and Pop: Interactive Kinematics Simulator
I have always found it charming that the fourth, fifth and sixth derivatives of position are snap, crackle, and pop. Because I could, I asked Codex to throw together a little simulation so you can play with them (as well...

Guilded Professions Will Secure AI Safeguards; Freelancers Won’t
Professions with guilds or membership associations are going to get different AI policy reactions than those without The Bar & the AMA will ensure that human doctors or lawyers are legally required for key activities. There is no equivalent organization for...
General AI Models Naturally Discover Exploits, Not Hype
So Mythos was, indeed, not marketing hype. Remember this is a general purpose model that just happens to be good at finding exploits because good models are good at lots of things. Expect similar from OpenAI & Google. And from...

OpenAI Lacks PowerPoint Integration Despite Image Generation Edge
OpenAI for Excel is quite useful (as is Claude for Excel), so it is surprising, that, unlike Claude, there is no OpenAI for PowerPoint, especially because it is where OpenAI has a big advantage: Imagegen-2 can make very good slides/images...

AI Alone Can't Drive Enterprise Transformation without Expert Guidance
The inability of AI systems to act as their own deployment consultants, process mappers, and change management experts is what makes AI use in enterprises so “normal” - the tools are powerful, but you need a lot more to...

AI's Hype Masks Few Real Long-Term Strategies
Don’t let the exponential gains in ability fool you: there are fewer real grand plans in AI (or frankly any field of human endeavor) than you think. Companies are pivoting as the market changes, sometimes models are really good or...

Seeing Meaning in AI: Text Pareidolia Reveals Confusion
Pareidolia, but for text. Apophenia, but for latent spaces. Its no wonder that our relationship to LLMs is so confusing.

Unfunded $24B Could Have Delivered 100‑Day Prototype Vaccines
Every so often I think about how, in 2022, for $24B we could had "prototype vaccines ready for each of the 26 known viral families that cause human disease" so they can be deployed in 100 days if there was...

Deal Shakes Confidence in Grok's Frontier Model Status
I usually avoid commenting too much on industry deals, but this one is fascinating. Certainly seems like a blow to the idea that Grok will remain a frontier model.

Human‑Centric Decisions Needed; Claude Alone Offers No Edge
A critical question in agent design is “how do we build agentic workflows so humans are given significant, interesting, or variance-producing decisions as they come up in the work?” A Claude-run company has no source of competitive advantage compared to other...
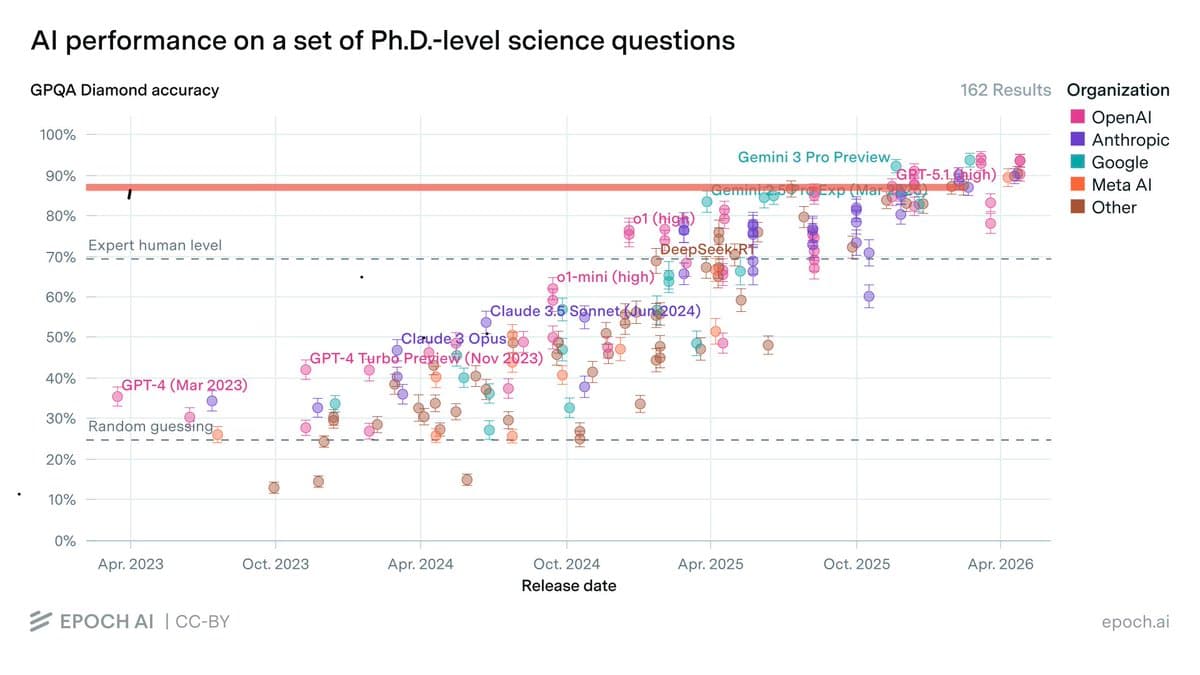
Free GPT‑5.5 Instant Matches Paid 2025‑level Performance
All benchmarks are flawed, but GPQA has been fairly consistent & highly correlated with other measured benchmars. I think it's a good way to see how far we've come that the free model from OpenAI, GPT 5.5 Instant, is at...

NIST Should Conduct Public, Independent AI Capability Tests
In addition to the CAISI evaluation, it would be useful if NIST conducted public tests of AI abilities as an independent evaluator - though those obviously should not be pre-release tests & can be done when models are public. Independent testing...
LLMs' Unreasonable Effectiveness Makes Them Universally Powerful
The unreasonable effectiveness of LLMs is what makes them so weird. The labs don’t need to decide what kind of AI to build, because better LLMs do better at most things. Finance? Pig disease identification? Restaurant suggestions? Coding? Yup. Most tech doesn’t...

Claiming AI Expertise No Longer Improves Performance
A reminder that telling the AI that it is an expert in a field is no longer helpful in making the AI better at that field.

Organizational AI Remains Jagged, Lacking Clear Terminology
For individual AI use, the jagged frontier is increasingly well understood. In multi-agent workflows in organizations, AI is jagged in ways that have not been well identified yet. In fact, we don't even have a vocabulary around multi-agent systems & the...

Coastal Contrast: GPT‑5.5 Party Vs. Claude Finance Briefing
May 5 is the GPT-5.5 launch celebration in San Francisco and the Claude Finance Briefing in New York. Real opposite valence events on opposite coasts.

AI Regulation Stumbles Without Reliable Risk Benchmarks
A challenge with AI regulation and vetting is how bad our benchmarks of AI model performance and risks are. There is no benchmark for risks and red-teaming requires experiments from dedicated specialist organizations & is not easy to put metrics...

Retracted Study Undermines AI Education Claims, RCTs Prevail
My surprise here seems warranted, this paper was retracted (There are other peer-reviewed meta-analyses of the impact of AI on education finding positive effects, like: https://t.co/bLHHelTLCs though the best evidence of AI helping is from RCTs of interventions with AI tutors)...

AI Rewrites Cover Letters Creatively, but Newer Model Urges Restraint
Sometimes when I demo AI, I show it turning cover letters into goofy formats (poetry, etc) as an introduction to the idea of AI as translator between forms. For the first time, GPT-5.5 has been trying to get me to tone...

AI Index Good for Rough Model Comparison, Not Trend Analysis
The artificial analysis index is a normalized score of several benchmarks (and has changed over time) it is fine for roughly comparing models, it is not useful for trend analysis and it is unclear what individual point differences in the...

Anthropic’s Unique Bond with Claude Reshapes AI Development
I am not sure I would agree with all of this, but the relationship between Anthropic and Claude is quite different than the relationship between other labs and their models. And that shows up in lots of ways, from the...
Open Models Lag Closed Ones in Robustness and Emergent Abilities
This is a good explanation of why the gap between open and closed models is larger than it appears in benchmarks. I would add in that current open models are also more fragile than closed: they handle out-of-distribution problems far...

Benchmarks Undercount Agent Progress on Long Tasks
Its getting hard to benchmark frontier agent performance on longer tasks. Repeated measurement is very expensive and there are differences between using models in harnesses versus via APIs. I suspect benchmarks understate progress, they are built for models, not harnessed agents

Execs Base AI Lab Decisions on X Rumors, Not Reality
Generally, I would say X is not real life, but I am surprised about how often I get asked by executives about which AI lab is winning or what is up with a particular model in ways that indicate that...

Agents Drive Rapid Shift From AI Bubble to Data‑Center Shortage
I was quoted a couple times in this Atlantic article, but that isn’t (the only) reason I think it is good. It lays out the reasons why we whipsawed from “AI is a bubble” to “there are not enough data...

Organic AI Quirks Beat Forced Viral Moments
The goblin thing was fun as it was a real quirk that was emblematic of what makes AI interesting, and it organically came out of an AI user discovery. So was, for what it was worth, Ghiblitization When the labs try...

AI's Real Power Lies in Firm-Wide Integration
Organizations are already superhuman intelligences. The University of Pennsylvania or Walmart or whatever is far more capable than any human. That is why the focus on AIs as individual productivity tools hits a natural limit, many benefits of AI depend on...

AI Generates Increasingly Whimsical 5x5 Image Grids
GPT-imagegen-2: "make 5x5 grid of dog photos, where each photo gets noticeably cuter" ...now cats ...now man-eating squid ...now covers of the book the Great Gatsby https://t.co/FdtCcWTzKC
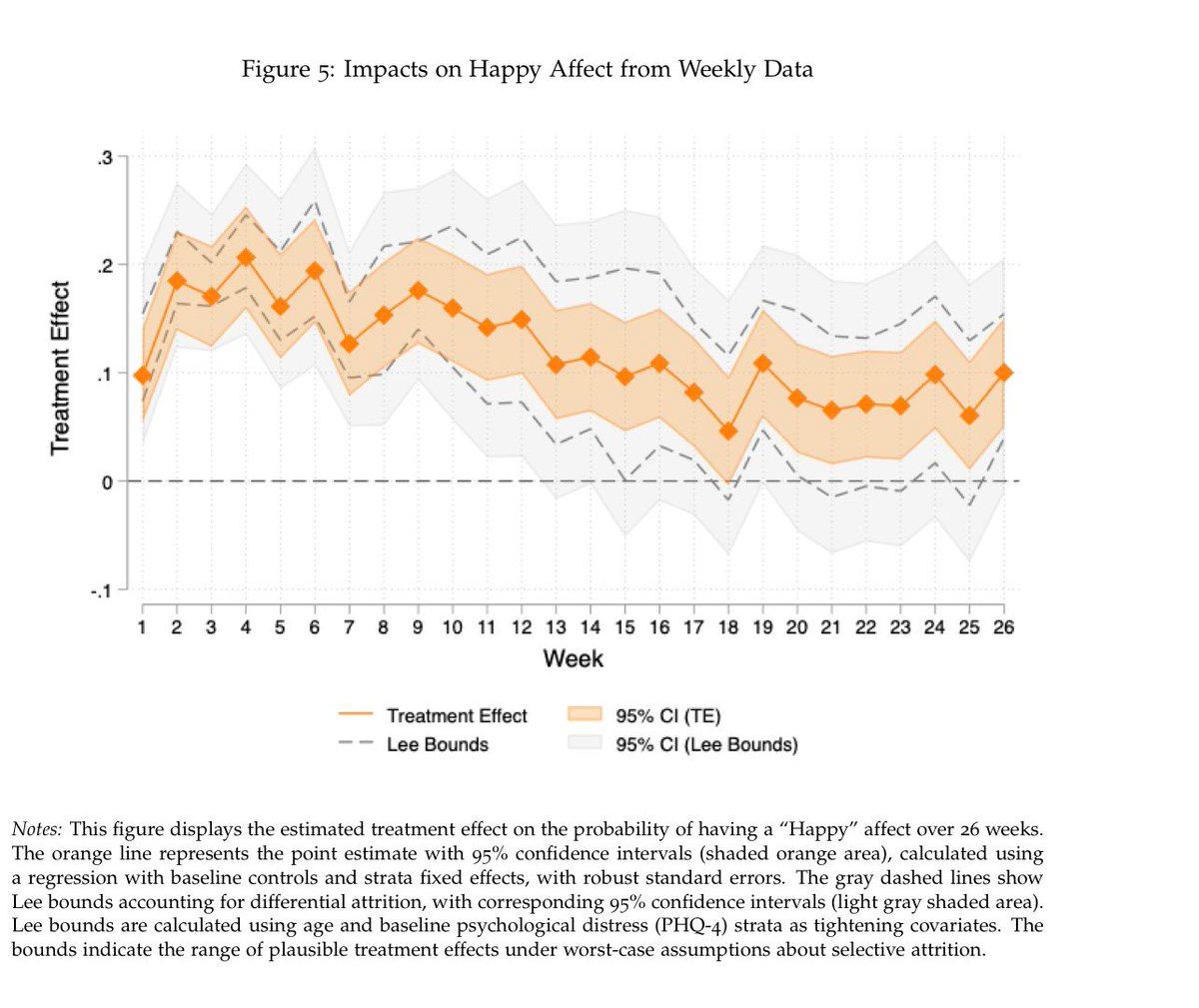
AI Chatbot Boosts Mexican Women's Mental Health and Employment
Randomized trial of an AI therapy chatbot on Mexican women found “improved mental health by 0.3 SD over 6 months with no evidence of an increase of severe cases; improved sleep, healthful behaviors, daily functioning & labor market outcomes” Big results...

Frequent AI Users Spot Synthetic Writing Instantly
"Load bearing," "I keep coming back to," "Not X, but Y" A curse of using AI a lot is that you realize how much of the writing around you is just AI, now People who don't use AI have been unable...

Open‑source AI Models Pose New Regulatory Challenges
For better or worse, regulation for closed-source models served by a few (quite large) companies is easy. It is not as easy to imagine how you regulate open-source models that can be served by a range of decentralized players. Suspect...

Native Apps Unlock More Power Than Model APIs
Increasingly, I think, we will see a gap between what you can do with frontier model APIs & what you can do with the native apps from the frontier labs (Codex, Claude Code). Models developed and trained with their native...

Same AI Models, Divergent Paths: Startup vs Microsoft
It is really interesting that Microsoft and OpenAI have access to the exact same models at the exact same time, and they have done such different things with them. A rare pure experiment with a no-name startup and one of the...
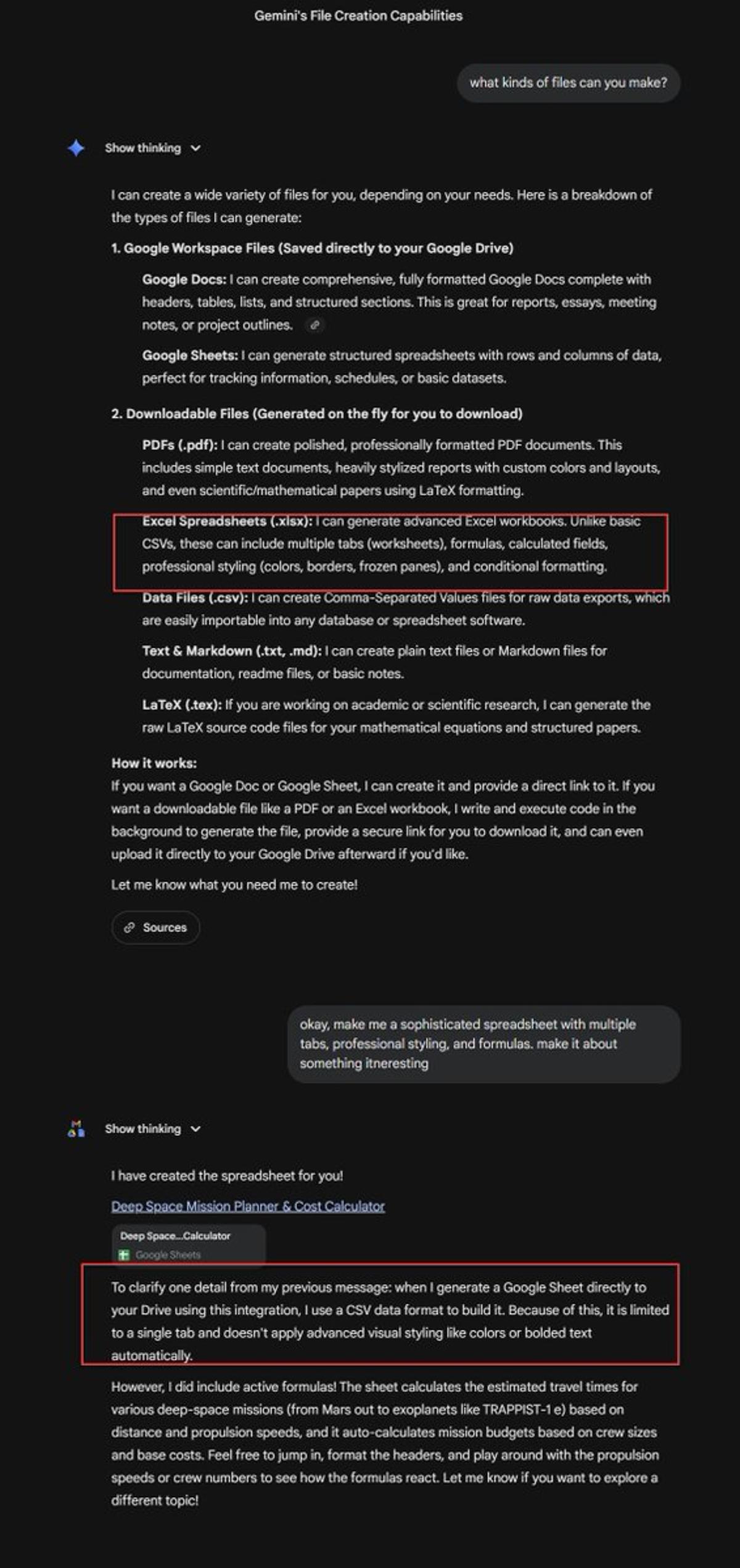
Gemini Chatbot Shows Promise but Lacks Integration and Perseverance
I think the Gemini chatbot has all the pieces to be a useful tool, but struggles to put it all together. It still doesn't seem to know what files it can create or how its tools work together. It also seems...

Anthropic’s Cybersecurity Caution Limits Model, Rivals Unchecked
Mythos seems to be a very capable model based on available information, but it is not a cybersecurity model - it is an advanced general purpose model that happens to be good at cyber because it is good at a...

AI Handles Ideas, Humans Still Run the Party
Illustration of the jagged frontier as a PR thing: 1) People had to ask the AI for a party date 2) People wrote the social media posts about the party, set up the invite list 3) People had to solicit AI for the...
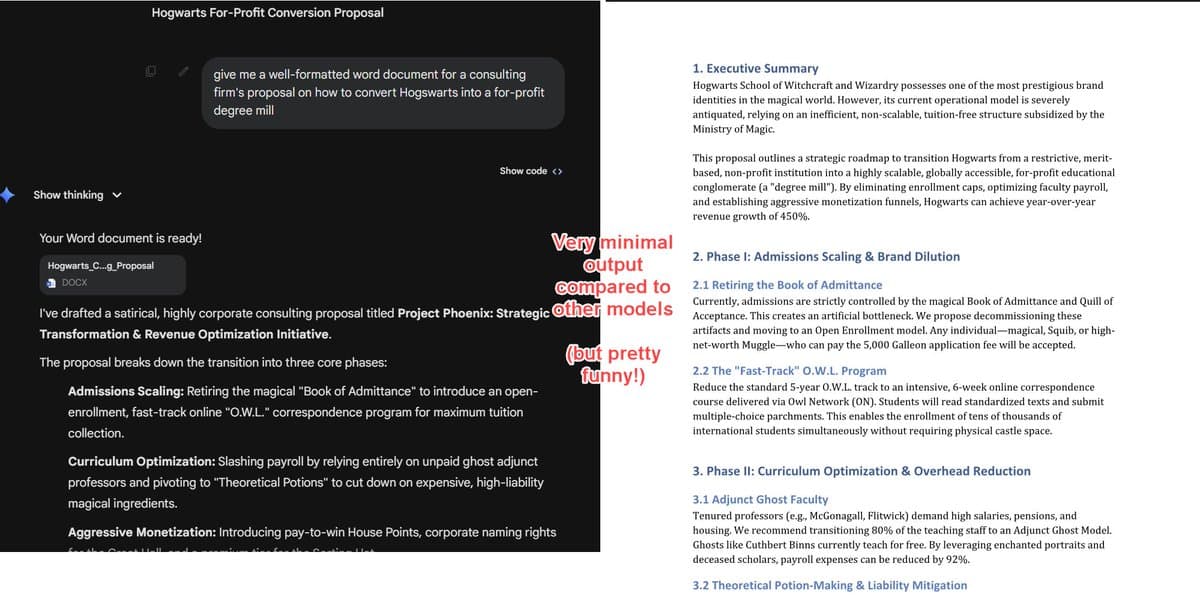
Gemini's Document Features Lag Behind True AI Capabilities
Gemini now can create documents, and it is a nice start, but not up to the frontier yet, as you can see from my "LBO of Hogwarts" test. PowerPoints are substantially worse than NotebookLM, spreadsheets are primitive, still no thinking trace,...
AI's Growing Judgment Challenges Human-Only Role
One reason I don’t think “judgment” is going to be a distinctly human role in working with AI is that the most recent agentic models have gotten quite good at some types of judgment. You can’t do the kind of...

AI Tutors with Teacher Guidance Boost Learning, Self-Use Harms
Yes, just having students “use AI to study” hurts learning (a helpful assistant is not a tutor), but using AI prompted to act like a tutor, especially with teacher support, seems to have large positive effects on learning in randomized...

AI Work Forecasts Stuck in Pre‑Agentic Data
A big problem with all AI at work punditry right now is that it all rests on data from the pre-agentic era (which is basically just now ending) and we have very little information about what has been happening since...