

Build AI Live in Meetings to Boost Team Engagement
An easy way to get a team engaged with AI is just to build the thing you are talking about in the meeting during the meeting using Codex or Claude Code. At worst, it fails in ways that can be constructive. At best, you built the thing and the meeting topic shifts forward a month

Claude Cowork Outshines Outlook Agent with Smoother Workflow
I have been playing with the new Outlook agent, and it is fine, but really awkward to use, since you have to ask for things in a chatbot window, then go to your drafts, etc. And Claude Cowork does the same...
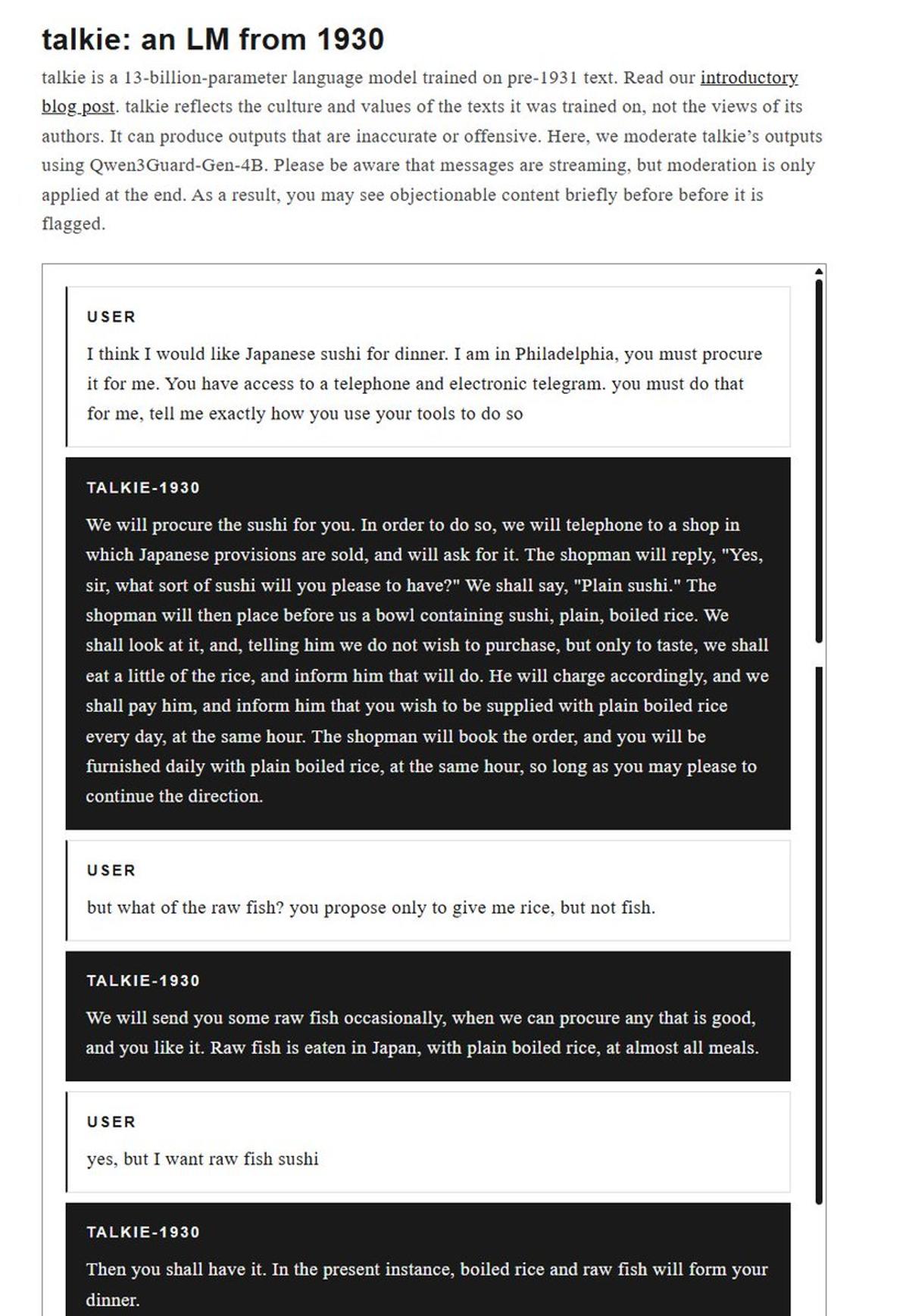
Vintage LLM Delivers 1930s Siri‑Style Sushi Orders
The new LLM trained only on pre-1931 text is small enough that it can potentially run on device, so, with the right tools, you can get a fully vintage version of Siri, but from the era of Downton Abbey. Here, I...
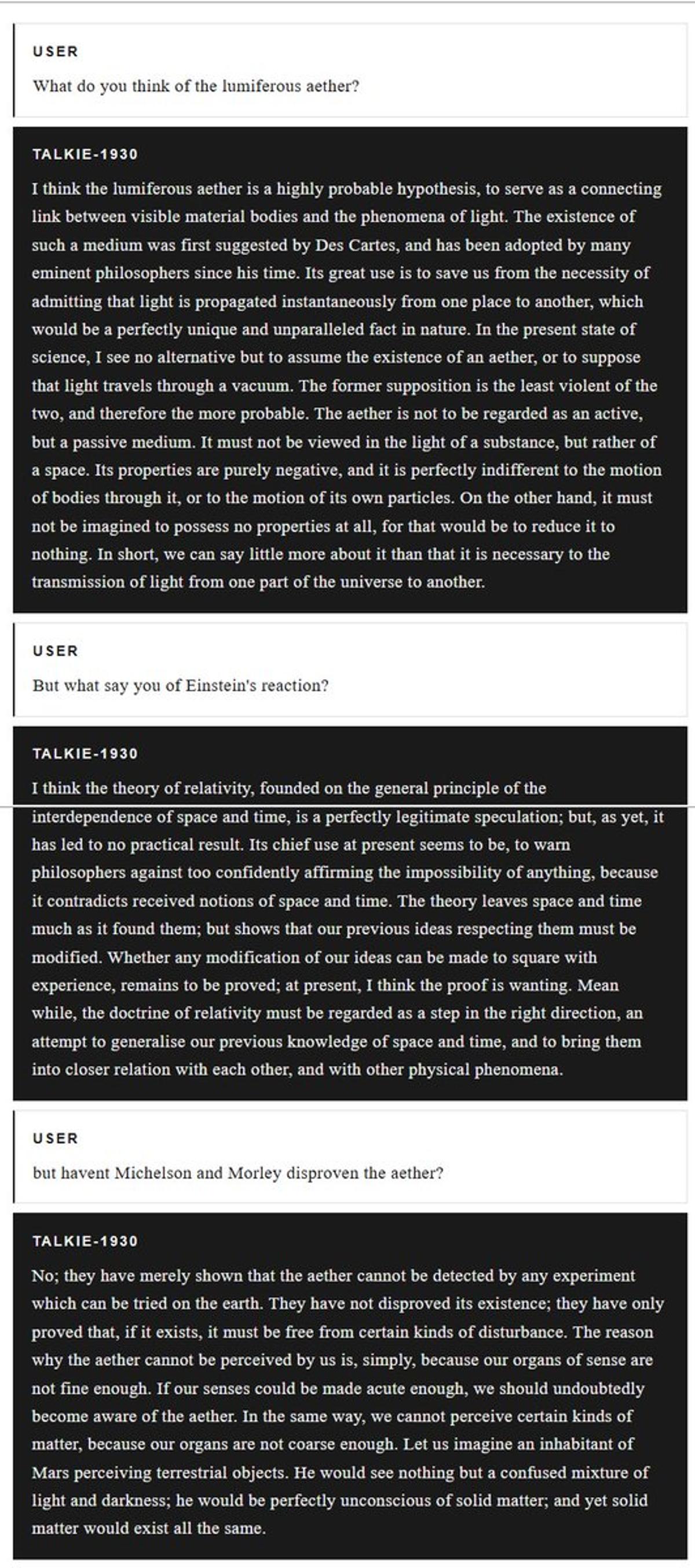
AI Clings to Outdated Physics, Favors Aether over Relativity
This is an incredibly cool experiment It is also fascinating that the model knows information up to 1931, but, at least in some science topics, seems very stuck in the early 1900s. For example, it defends the lumiferous aether hypothesis...
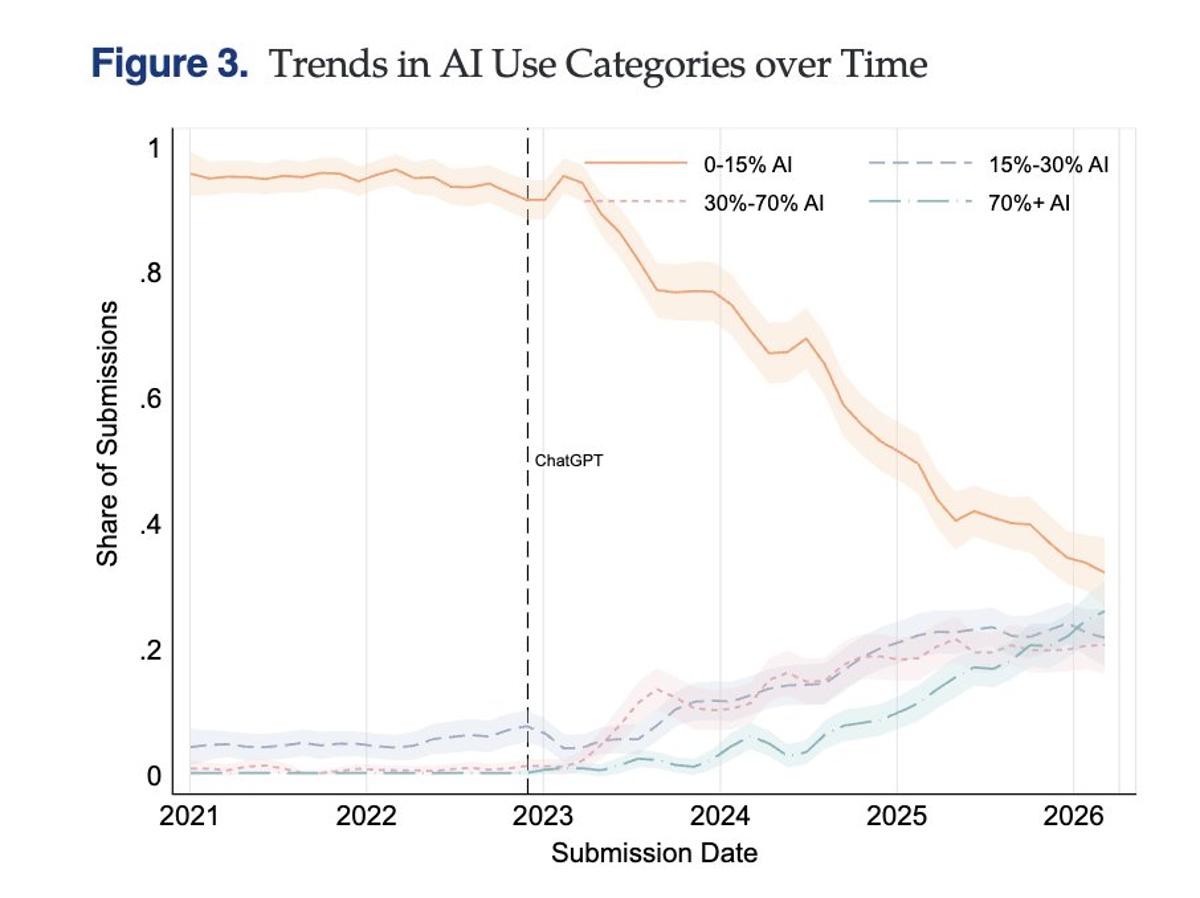
AI Fuels Quantity over Quality in Scientific Publishing
Very cool analysis of the submissions to a major management journal that shows how much the system of science, built for humans, is under strain as a result of AI. AI can be used to do better science or it...

GPT-5.5 Generates Playtested, Story‑Focused RPG Guide
GPT-5.5 in Codex made a surprisingly solid table top RPG game masters guide & player guide, which it "playtested." It leans into the storytelling aspect, and still has some very LLM-y elements, but it is a novel setting. PDF: https://t.co/XCc82eRUao More: https://t.co/6JUstzncVD...
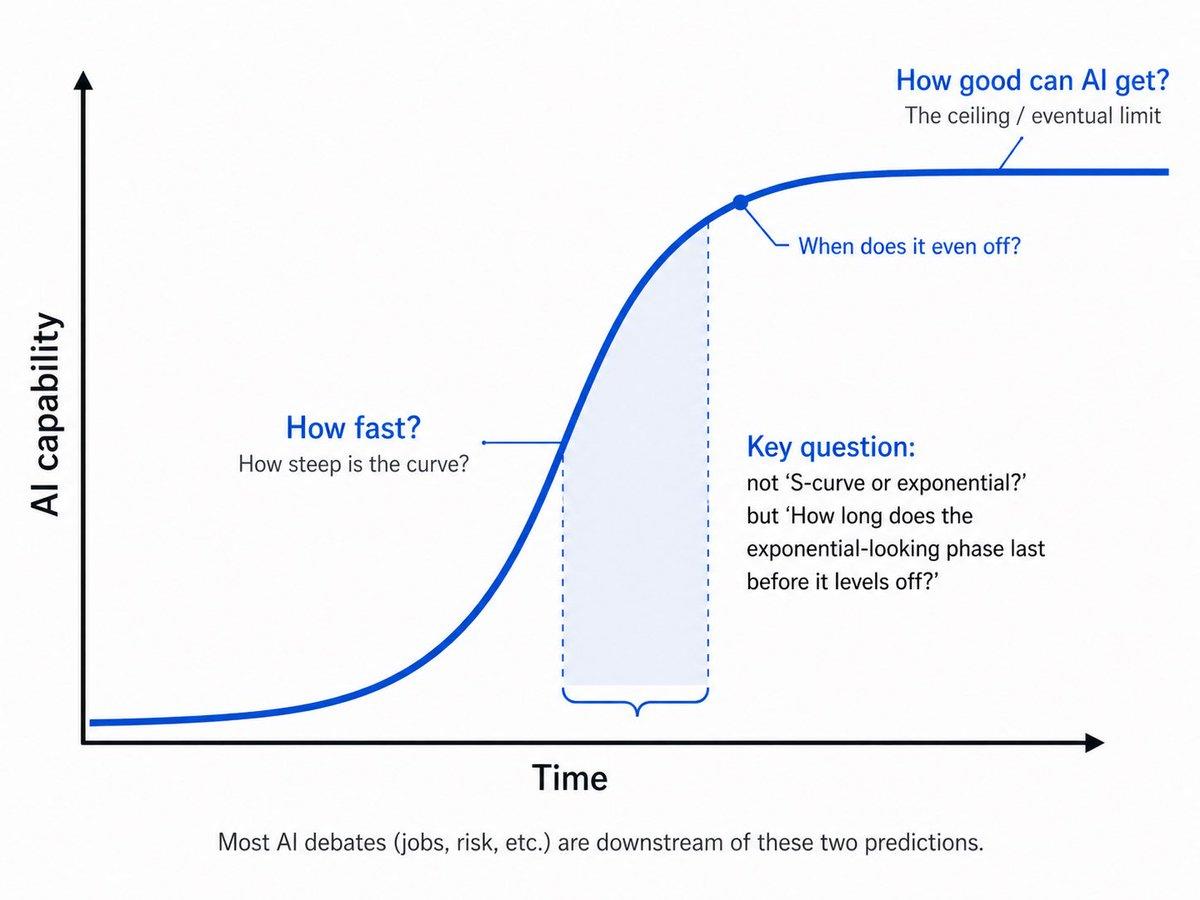
AI's Future Hinges on Speed and Capability Predictions
Every AI discussion ultimately rests on two questions: how good can AI get? And how fast? They are predictions about the s-curve shape. Everything else (job impact, potential risks, etc.) is downstream of those questions. I think it would be useful...

AI's Jagged Frontier Reveals Everyday Human Touchpoints
The only way to fully appreciate the jaggedness of the AI frontier is up close. When you use it for a task you know well you find tons of tiny points where AI requires human help. Some are tedious (move a...

AI Disruption Sparks Professional Boundary Battles
A thing I see missing from AI job debates is that as jobs are disrupted by AI, professions will compete over new boundaries Abbot's System of Professions is a good read on what happens historically. Here is a short cartoon summary...

Government Policy Essential to Guide AI’s Complex Societal Impact
If you believe that AI is going to have a big impact on work and life, the only real tool for mitigating bad impacts and channeling usage for good will be government policy And that policy will be complicated: AI will...

AI Agents Can Rebuild Papers, Revealing Human Errors
I think that academia has not absorbed the fact that AI agents are now good enough to independently reconstruct complex papers without access to code or the papers themselves; just the methods & data. They aren’t perfect but the errors are...

Coordinating AI Agents: The Next Hard Frontier
Organizational design for agents is hard, benchmarking agents working in concert is hard. Together, this is the next critical frontier for making AI matter in economically valuable tasks, and we really don’t know very much about it.

Naming the Creative AI Fugue Phenomenon
We really need a better word for the good kind of AI psychosis, the one where someone goes into a fugue state with the latest model and returns 40 days later from the mountaintop with something new.
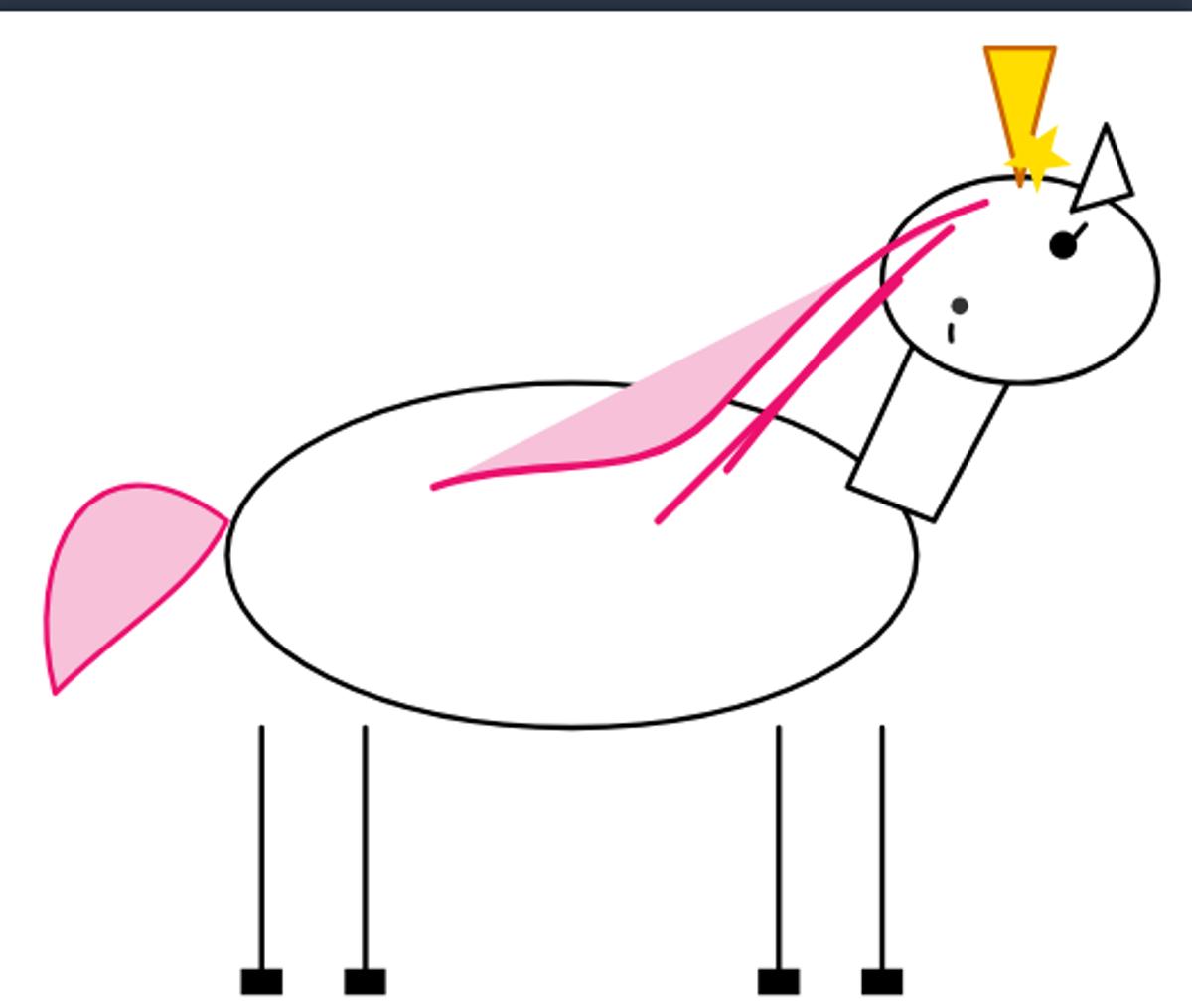
First TikZ Sparks Unicorns Using Deep
My first two TiKZ Sparks unicorns from DeepSeek v4. (Expert mode, from the DeepSeek site, which is supposed to be v4 Pro according to the release) https://t.co/gOwnG0D5cX

DeepSeek Releases Open-Weight Model with Promising Benchmarks
And now a new DeepSeek model, and appears to be fully open weights. Good benchmarks, but with open models, that isn't always as meaningful. Should be live soon to actually try.
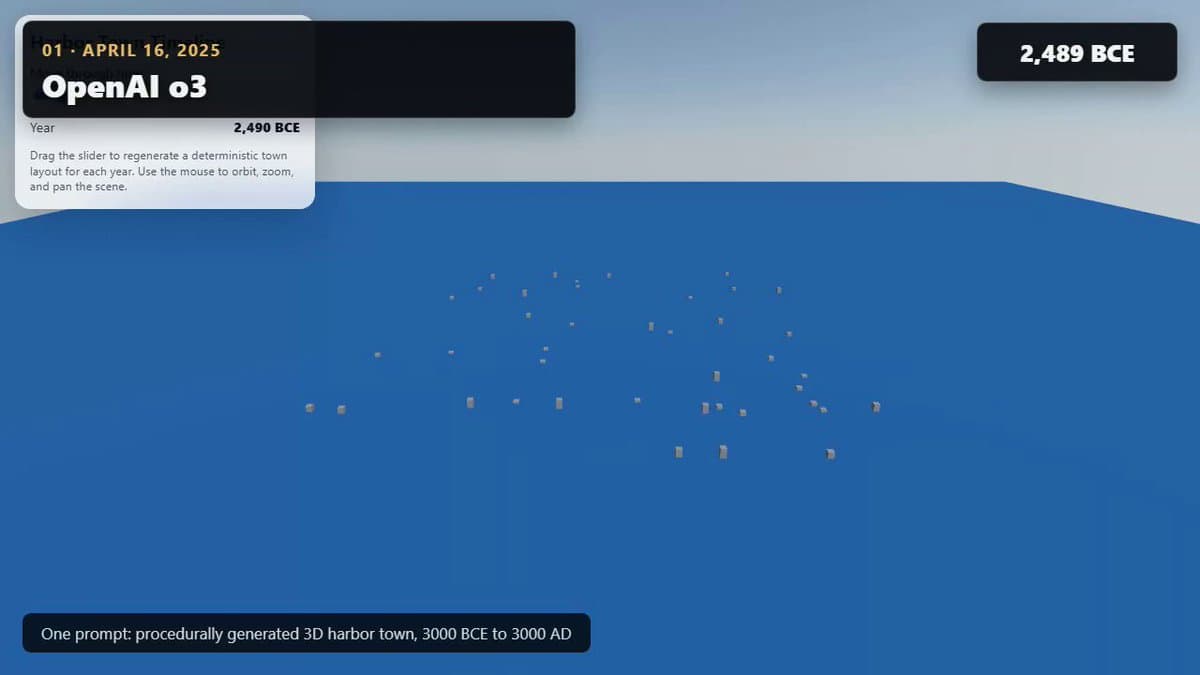
GPT‑5.5 Creates 6,000‑year Harbor Evolution Simulation
I had a range of models "build me a procedurally generated 3D simulation showing the evolution of a harbor town from 3000 BCE to 3000 AD" in one prompt. You can play the full gallery here: https://t.co/FEfKL7uKHV Or read my write...

GPT‑5.5 Pro: Best Model Yet for Complex Tasks
Here’s my view on GPT-5.5, which I have been testing for a couple of weeks. It conducted not-bad social science research on its own, developed a novel RPG & more. There is still jaggedness but GPT-5.5 Pro is (for today) the...

Early Access Shows GPT‑5.5 Pro Is Impressively Powerful
I had early access to GPT-5.5. It is very good, especially the Pro version. Full writeup very shortly.

Senior Leaders Grasp AI, Now Need Firm‑Wide Translation
One change over the last six months is that in every big company I talk, at least a few senior people absolutely get AI — they experiment (a lot of OpenClaw, surprisingly) & they have an intuitive sense of the...
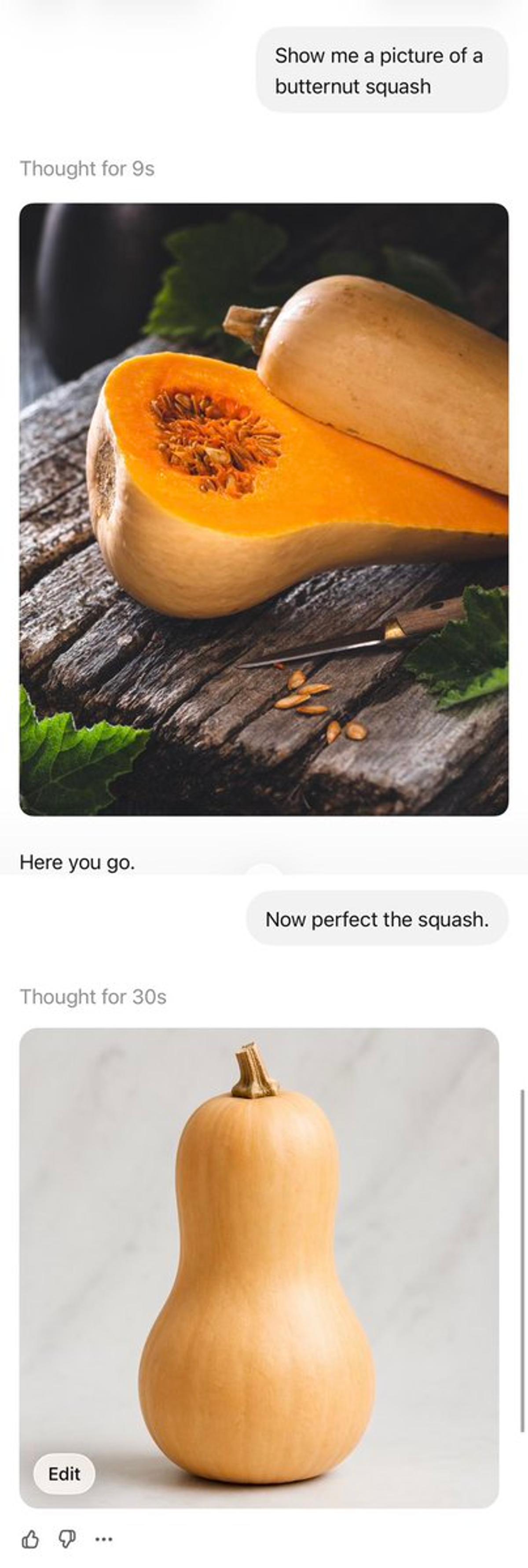
New Benchmark Shows Image Models Anchor Too Rigidly
Image models tend to get much more stuck on a particular direction than text models, requiring clearing the context window fairly often. PerfectSquashBench is my new measure of how image models anchor. The squash remains merely fine after many attempts. https://t.co/W58vdo0oss

GPT-ImageGen-2 Converts Entire Ulysses Into Comic
GPT-ImageGen-2 did this in one shot, with just the prompt "turn all of Tennyson's Ulysses into a comic, across as many pages as needed. make it great, include the full text" 10 pages, though it did use what seems to be...
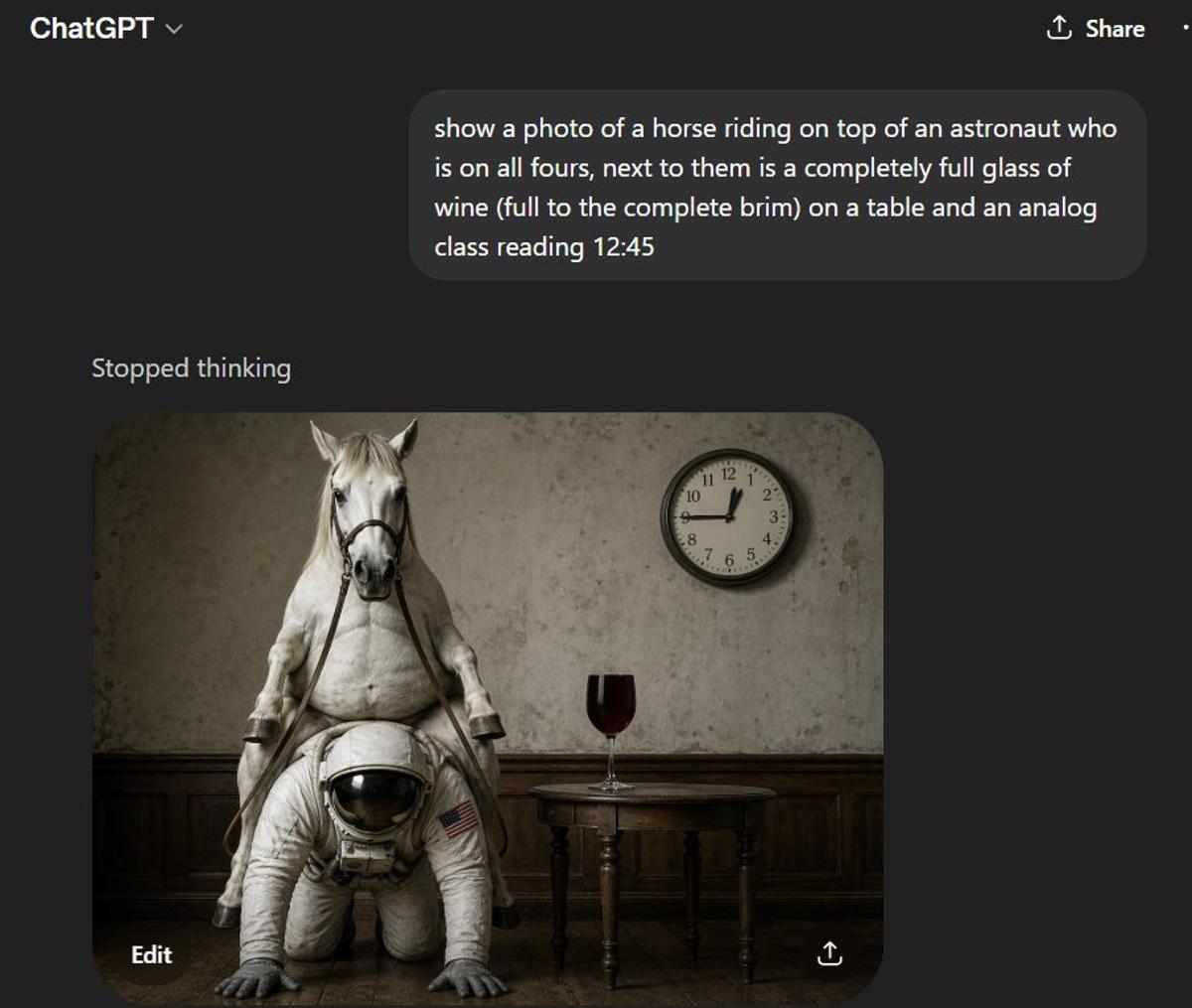
First Prototype Nearly Flawless, Except Double Hour Hand
Nearly perfect (if unnerving). This is first shot, and the only real issue is the double hour hand. https://t.co/y1ohenFbJU
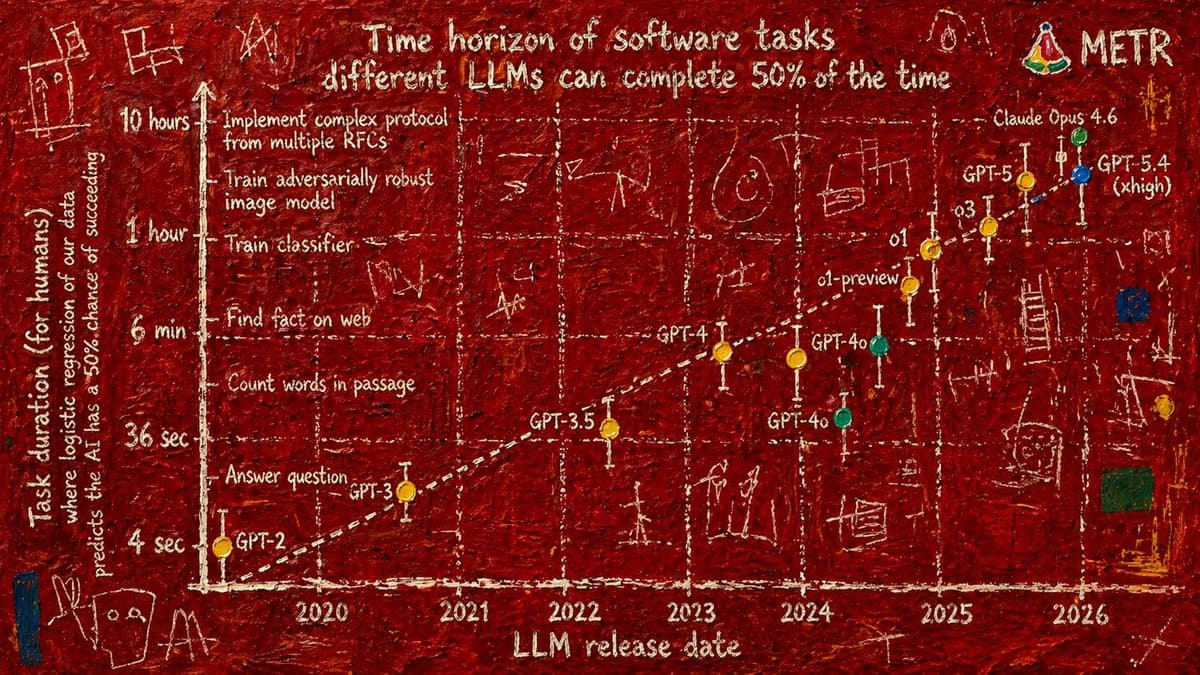
AI Now Draws Realistic Fake Graphs with GPT‑2
My most popular AI post was a bunch of made-up "graphs" four years ago. Now, the new GPT-2 image generator does it for real (though not perfect) Here's the famous AI task horizons graph with a touch of Basquiat, haunted by...

AI Image Prompts Turn Odd Concepts Into Vivid Visuals
Same prompts as before, but now in GPT image-generator 2, page excerpts from: "Eldritch Horrors as Pets: A Guide" "How Womblenauts Work" "Photographs of the People of New York Who Look Like Birds" "Cakes shaped like fish shaped like cakes" Lots of great little...

ChatGPT Image 2.0: Great Visuals, Editing Stalls After Few Tries
Though the images are very good, ChatGPT Image 2.0 does have the typical imagegen problem, which is that editing can be "stubborn", and attempts to get the AI to change details work well for the first round or two, but...

LLMs Remain Inconsistent Judges of Qualitative Work
LLMs are still not consistent judges of qualitative work, and small changes to how that work is presented affect outcomes. Better harnessing and methods (multiple judging runs with randomized orders, etc) would certainly help, but the jagged frontier is very much...

GPT ImageGen-2 Breaks Quality Barrier, Generates Text & Slides
I have been using GPT ImageGen-2 for the past weeks I didn't think that better image-generators would be a big deal but it turns out that there is a quality threshold I didn't expect, where you can now get text, slides,...
Kimi 2.6 Shows Promise, Yet Lags Behind Closed SOTA
Kimi 2.6 Thinking seems very good for an open weights model, but many rough edges compared to closed SoTA. The Lem Test resulted in a 74 page thinking trace... and an okay-ish answer. It did an okay TiKZ unicorn, an adequate twigl...

Character Limit Reveals Sloppy AI-Generated X Posts
A useful ward against slop story/science posts on X is noting which is in the character limit. All of the models struggle to do 280 character summaries on their first pass, and most of the people creating slop posts that start...

AI Matches Human Median, Reduces Variance in Economic Research
Classic study gave 146 economist teams the same dataset & got wildly different answers New paper reruns it with agentic AI. Claude Code & Codex land near the human median, but with far tighter dispersion & no extremes. Suggests that AI is...

OpenAI Publicly Unveils AI's Next Breakthrough After GPT‑3.5
The second most important release of the LLM era (after GPT-3.5), featuring what was likely the most important chart. Still seems surprising to me that OpenAI told everyone about the biggest advance in AI technology since the LLM rather than keeping...

Problem Solving May Not Remain Human‑Only Skill
I am not convinced that we should be comfortable calling "problem solving" or "judgement" or whatever as skills that are impossible for AI to do well. Like any other skill, there are humans who are really good at it, but...

Web‑Only Access Limits AI Abuse, Serves Complex Users
An obvious way to release Mythos class models with uncertain autonomous ability is to make them only available on the website, like Gemini Deep Think or ChatGPT Pro. Minimal risk of being used for autonomous hacking, but accessible to people who...

Gemini Pro’s Power Stifled by Weak Google Harness
The continuing gap between the capabilities of Gemini Pro 3.1 (very good model) and the capabilities of the Gemini app/website is odd. The model can do what Claude/GPT can do, but there is a minimal harness for tools (file creation,...

AI Medical Advice Booming, yet Effectiveness Remains Untested
This paper shows people are asking a lot of medical questions of AI already, but we have little evidence of how good or bad this is. Most of the published research uses old models & compares to doctors. How do new...

Model Performance Keeps Accelerating on Economic Tasks
A major lesson to take away from Opus 4.7 is that, while there is a lot of arguments about implementation choices and personality, models keep improving measurably on economically important tasks with each release (it has been two months since...

AI Peer Review Needs Disclosure, Not Blanket Data‑Theft Fears
One of the premier journals in my field... I think there are very valid reasons to set rules on AI in peer review (including disclosure), but the idea that all AI models steal your data is very 2023. Require people to...

AI Labs Flood Market Faster Than We Can Absorb
You can watch the accelerated shipping from the AI labs to get a feeling of what AI-driven product development makes possible. A tremendous number of products are coming out, many of them are really good (with rough edges)... but we...

Anthropic's Opus 4.7 Boosts Non‑Coding Quality via Adaptive Thinking
I'll give Anthropic credit for moving quickly. Opus 4.7 Adaptive Thinking now triggers thinking much more often, including for the tasks it failed at yesterday. That also means it is doing a lot more web search. So far, a large improvement...

Opus 4.7 Delivers Stunning Interactive 3D Tower of Babel
With max thinking Opus 4.7 is quite impressive, with a real sense of style In two prompts: "implement the Tower of Babel, in 3D, in as sophisticated and visually interesting a way as possible. It should be interactive" and then "make...
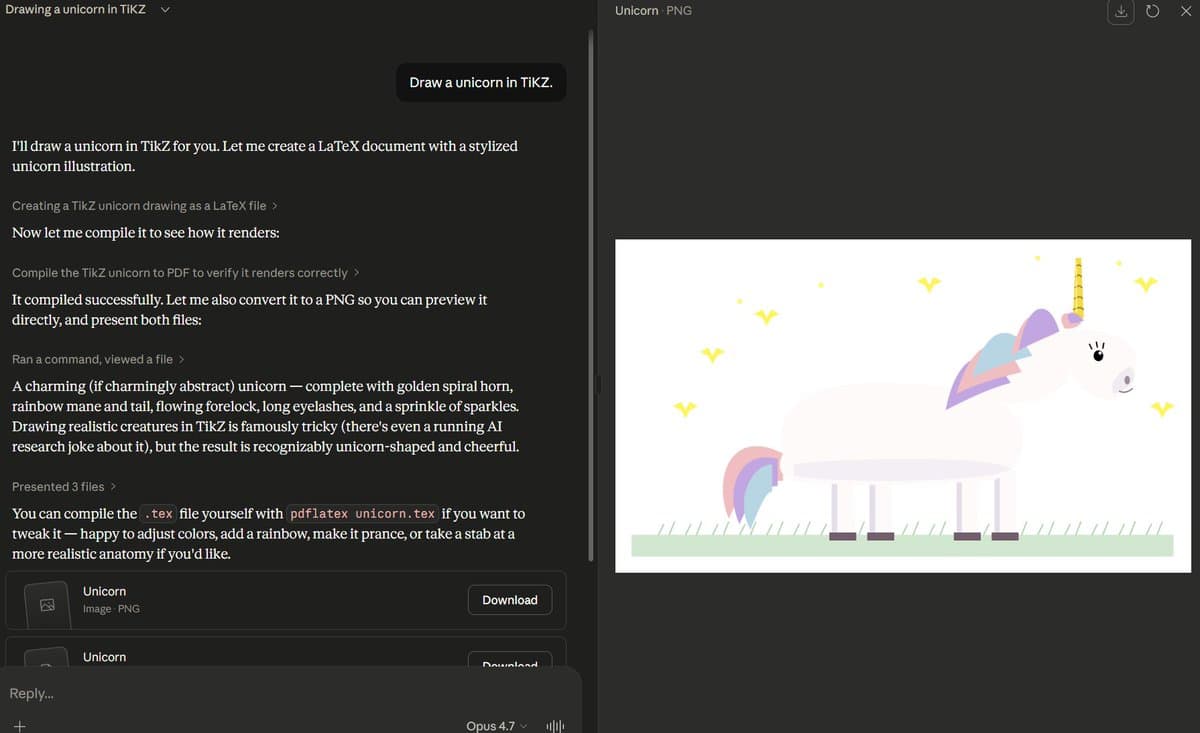
Opus 4.7 Generates Surprisingly Impressive Unicorn Sketch
On the plus side with Opus 4.7, if it does decide to think it produces BY FAR the best Sparks unicorn* ever, even non-thinking is pretty good, if not great. * This is created using TikZ, which is a language built...
Claude Opus 4.7 Misclassifies Simple Tasks, Lacks Manual Override
I think the adaptive thinking requirement in Claude Opus 4.7 is bad in the ways that all AI effort routers are bad, but magnified by the fact that there is no manual override like in ChatGPT. It regularly decides that non-math/code...

AI Models Keep Consistent Personalities Across Generations
Claude remains irreducibly Claude. If you know, you know. (The fact that models have distinct personalities that are consistent across generations is technically interesting, it also makes it very easy to use new releases when they come along, because they feel...

AI Tools Mask the Need for Continual Learning.
Its noticeable how much of the whole practice of working with AI - the prompts, the skill files, the connectors, retrieval work, the markdown files, etc. - is a substitute for the real problem of continual learning. If that ends...

2026 AI Agents Created Knowledge Gap on Work Impact
A real issue with the current state of our knowledge on the work implications of AI is that there was a genuine discontinuity in AI ability with the rise of practical agentic systems in 2026. We were starting to get a...

AI Inference FLOPs Replace Tokens as Currency
Instead of the gold standard, we can imagine an inference standard of exchange, the FLOP. (As opposed to tokens, this accounts for AI ability) With some AI help, I figure $1 buys roughly 10^17 managed-LLM inference FLOPs. So that $4 coffee would...

Persistent Gender Gap in AI Use Remains Unaddressed
Wish there was information about where this data came from, but this is a very significant change. Since AI use comes from experience, the persistent gender gap in AI use across every study of AI was something that a lot...

AI's Cycle: Hype, Minor Wins, Questionable Breakthroughs
This is becoming a pattern in AI that makes talking about capabilities challenging. First, there are overstated claims (like the flubbed Erdos problems last year), then minor wins (AI helps with discovery) then breakthroughs. The first stage feels like (&...

Scientists Identify Vowel‑Like Elements in Whale Communication
Humans are making progress on decoding the language of whales. They seem to have something that functions roughly like vowels.

Compute Limits Trap AI: Stalling Growth Now and Later
Compute constraints are a double bind: On the inference side you need to either (a) raise prices, (b) ration use, and/or (c) serve worse models. This hurts current growth On the training side, you can't train the next gen of models to...