

Digital Design & Comp. Arch: L15: Dataflow, Superscalar Execution & Branch Prediction (Spring 2026)
On 17 April 2026, Prof. Onur Mutlu delivered ETH Zürich’s Lecture 15 on dataflow, superscalar execution, and branch prediction as part of the Digital Design & Computer Architecture spring series. The session unpacked how dataflow architectures expose fine‑grained parallelism, how superscalar CPUs issue multiple instructions per clock, and how modern branch predictors mitigate control‑flow penalties. Supporting slides and a curated reading list link the concepts to processing‑in‑memory, memory‑centric computing, and security research such as RowHammer. The lecture reinforces ETH’s role in shaping next‑generation computer‑architecture curricula.
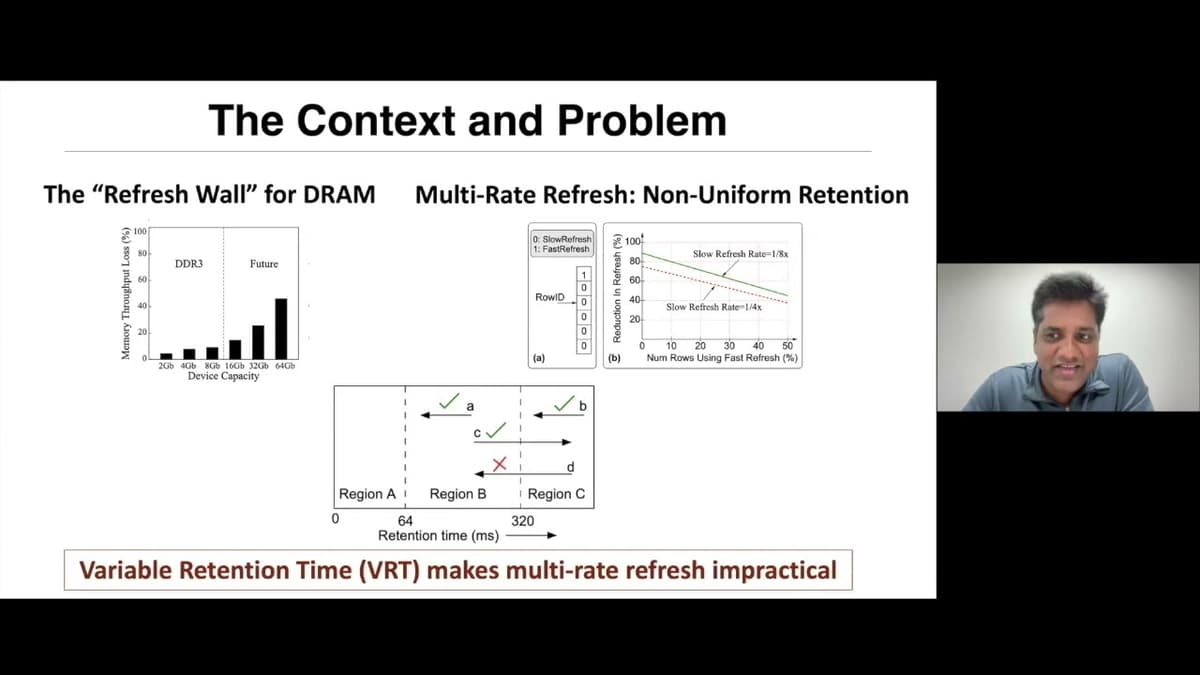
AVATAR: A Variable-Retention-Time Aware Refresh for DRAM Systems - DSN 2025 Test-of-Time Award
The DSN 2025 Test‑of‑Time award honored the seminal AVATAR paper, which tackled the growing DRAM refresh burden as capacities and operating frequencies increased. The authors highlighted that traditional uniform refresh intervals ignore the non‑uniform, variable‑retention‑time (VRT) behavior of memory cells,...

Memory-Centric Computing: Enabling Fundamentally-Efficient Computers - Georgia Tech ECE Seminar
Professor Honor Mutlu’s Georgia Tech seminar highlighted a fundamental shift in computer architecture: moving from processor‑centric designs to memory‑centric computing. He argued that exploding data volumes in AI, genomics, and scientific domains have turned data movement into the primary performance...

Seminar in Comp. Arch. - L7: Virtual Memory (Spring 2026)
On 2 April 2026, ETH Zürich’s Computer Architecture seminar hosted a deep dive into virtual memory, led by Konstantinos Kanellopoulos and Prof. Onur Mutlu. The session combined foundational concepts with cutting‑edge research on processing‑in‑memory, memory‑centric architectures, and security vulnerabilities such as RowHammer. Attendees received a rich...

Digital Design & Comp. Arch: L13: Precise Exceptions & Interrupts (Spring 2026)
The Spring 2026 lecture on Digital Design & Computer Architecture focuses on precise exceptions and interrupts, explaining how they preserve sequential semantics in pipelined processors and set the stage for out‑of‑order execution. The instructor shows that modern pipelines contain multiple functional...

Memory-Centric Computing: Recent Advances in Processing-in-DRAM: IEDM Invited Talk - 09.12.2024
The invited IEDM talk highlighted memory‑centric computing as a response to exploding data volumes and the growing energy cost of moving that data. The speaker argued that today’s processor‑centric designs waste up to 90% of system energy on memory accesses,...

Understanding & Designing Modern Storage Systems - M5: Processing Inside NAND Flash Memory
The video introduces FlashCosmos, a new in‑flash processing technique that performs bulk bitwise operations directly inside NAND flash memory. Presented as part of a recent MICRO 2022 paper, the work targets the growing data‑movement bottleneck that hampers databases, graph analytics,...

MCCSys-5: 5th Workshop on Memory-Centric Computing Systems, Held with ASPLOS 2026 - 23 March 2026
The fifth Memory‑Centric Computing Systems (MCCSys‑5) workshop, co‑located with ASPLOS 2026, gathered researchers to confront the growing memory bottleneck that now dominates performance, energy consumption, and hardware cost across data‑intensive workloads. Organizers outlined the agenda—keynotes on memory‑centric architectures, recent advances...

ASPLOS 2026: 2nd Workshop on Virtuoso: Ideas and Infrastructures for Novel HW/OS Interfaces
The 2nd Virtuoso workshop, part of ASPLOS 2026, will convene on March 23, 2026 in Pittsburgh to explore hardware‑software co‑design for memory management. Organized by CMU‑SAFARI, the full‑day event includes a tutorial, presentations of recent research, and hands‑on sessions using...

Seminar in Comp. Arch. - L6: Machine Learning-Driven Memory and Storage System Design (Spring 2026)
On March 26, 2026, ETH Zürich’s Computer Architecture seminar featured a deep dive into machine‑learning‑driven memory and storage system design, presented by Rahul Bera, Rakesh Nadig, and Prof. Onur Mutlu. The session highlighted how AI techniques can automate tiered memory management,...

Revisiting RowHammer - Top Picks in Hardware and Embedded Security - Prof. Onur Mutlu - 30.10.2025
The talk revisits the seminal Rowhammer problem, presenting the 2020 "Revisiting Rowhammer" paper that conducted the largest experimental study to date on real DRAM chips. By testing roughly 1,600 devices from three major vendors across DDR3, DDR4, and LPDDR4 generations,...

Digital Design & Comp. Arch: L10: Microarchitecture Fundamentals and Design (Spring 2026)
The lecture introduces micro‑architecture fundamentals by contrasting single‑cycle and multicycle processor designs. It explains that a single‑cycle processor implements the entire ISA instruction path—fetch, decode, execute, memory access, and write‑back—in one combinational pass, requiring the clock period to accommodate the...

Memory System Design for AI/ML & ML/AI for Memory System Design - SRC AIHW Annual Review - 23.07.24
The SRC AIHW annual review highlighted a critical challenge in modern AI/ML systems: data movement consumes the majority of system energy, especially in large‑scale models running on edge TPUs where over 90% of power is spent on off‑chip interconnects. The...

P&S: Arch. & Algo. For Health & Life Sciences- L3: Storage Centric (Meta)Genomics I (Spr 2026)
The lecture introduces storage‑centric architectures for genomics and metagenomics, focusing on how embedding filtering logic directly inside storage devices can alleviate the massive data‑movement and preparation bottlenecks that dominate current pipelines. By moving simple, low‑cost operations—such as exact‑match detection and...

Digital Design & Computer Architecture D3: Problem-Solving Session 3 (Spring 2026)
The session introduced Verilog as a hardware description language, emphasizing that it models physical circuits rather than behaving like a traditional software language such as Java. The instructor walked through the creation of an "odd counter"—a finite‑state machine that counts...

Understanding & Designing Modern Storage Systems - L3: MQSim (Spring 2026)
The video introduces MQSim, an open‑source C++ framework designed to simulate modern multi‑queue SSDs with NVMe protocols. It contrasts MQSim with legacy SATA‑oriented simulators, highlighting how the latter fail to capture multi‑queue behavior, steady‑state operation, and full end‑to‑end request latency,...

Memory-Centric Computing (Keynote Talk at IDEAS Center) - Prof. Onur Mutlu (14.05.2024)
Professor Onur Mutlu’s keynote at the IDEAS Center introduced memory‑centric computing—also called in‑memory or processing‑in‑memory—as a necessary evolution beyond today’s processor‑centric architectures. He argued that modern workloads such as machine learning, genomics, and large‑scale databases are fundamentally limited by the...

Digital Design & Comp. Arch: L8: Instruction Set Architectures II (Spring 2026)
The lecture revisits instruction set architectures (ISAs) by focusing on the LC3 educational processor, illustrating how the ISA serves as the contract between software and the underlying micro‑architecture. It walks through the classic fetch‑decode‑execute pipeline, emphasizing the three‑state fetch sequence...

RowHammer, RowPress & Beyond: Invited Talk at Dagstuhl MAD Seminar - 27.11.2023
The Dagstuhl MAD seminar talk examined RowHammer and related DRAM disturbances, tracing their origins from early research to today’s large‑scale security implications. The speaker highlighted how shrinking DRAM cells increase electrical noise, making bit flips more likely, and presented data...

Digital Design & Computer Architecture: Lecture 6b: Verification & Testing (Spring 2026)
The lecture introduces circuit verification and testing as a core stage of digital design, emphasizing how engineers confirm that a synthesized HDL design is both functionally correct and meets timing constraints before silicon implementation. The instructor contrasts functional verification—checking logical correctness—with...

Understanding & Solving RowHammer - Flash Memory Summit 2023 - Prof. Onur Mutlu
At the Flash Memory Summit 2023, Prof. Onur Mutlu presented a comprehensive overview of the RowHammer phenomenon affecting DRAM and emerging memory technologies. He traced the vulnerability’s origins, detailed recent experimental findings, and highlighted both hardware and software mitigation strategies....

Understanding & Designing Modern Storage Systems - L2: Basics of NAND Flash-Based SSDs (Spring 2026)
The lecture provides a detailed walkthrough of modern NAND flash‑based SSD architecture, beginning with a high‑level view of the SSD PCB that houses multiple flash packages, a low‑power DRAM cache, and a multi‑core controller. It explains how the host interface...

Digital Design & Comp. Arch: L5: Hardware Description Languages and Verilog (Spring 2026)
On 5 March 2026, Prof. Onur Mutlu delivered Lecture 5 of ETH Zürich’s Digital Design and Computer Architecture course, focusing on hardware description languages with an emphasis on Verilog. The session outlined Verilog’s syntax, simulation flow, and its role in designing modern...

Sibyl - Flash Memory Summit 2023 - Prof. Onur Mutlu
Prof. Onur Mutlu presented Sibyl, a reinforcement‑learning framework that dynamically places data across DRAM and flash in hybrid storage systems. The approach learns optimal policies based on workload characteristics, achieving up to 2× throughput gains and 30% lower latency compared...

Seminar in Comp. Arch. - L3: Memory-Centric Computing II (Spring 2026)
The seminar continued the series on memory‑centric computing, shifting focus from near‑memory acceleration to true processing‑using‑memory (PUM). The lecturer reviewed prior work on 3‑D integration and specialized accelerators for graph processing and machine‑learning inference, then introduced the core PUM concepts...

Digital Design & Comp. Arch: L6: Timing & Verification (Spring 2026)
The lecture introduced timing and verification as the next major theme in the Digital Design & Computer Architecture course, following a review of hardware description languages and combinational/sequential logic. The instructor emphasized that modern designers must analyze both functional correctness...

Accelerating Genome Analysis: A Primer on an Ongoing Journey - CANU UDG Lecture, 08.06.2023
Professor H., a computer‑science veteran with stints at Microsoft Research, Intel, AMD and Google, opened the lecture by framing genome analysis as the next frontier where information technology meets biology. He highlighted his 17‑year journey from early research on genome‑aware...

Digital Design & Computer Architecture D1: Problem-Solving Session 1 (Spring 2026)
The video records a supplemental problem‑solving session for the Spring 2026 Digital Design & Computer Architecture course. Maria, the facilitator, explains that each week she will take a lecture concept and work through an exam‑style Boolean exercise—in this case, rewriting a...

Digital Design & Comp. Arch: L4: Sequential Logic Design & Finite State Machines (Spring 2026)
The lecture continued the Digital Design course by completing the discussion of sequential logic and introducing finite state machines (FSMs). After reviewing memory elements—from cross‑coupled inverters to gated D‑latches and multi‑bit memory arrays—the professor emphasized the need for storage elements...

Memory System Design for AI/ML & ML/AI for Memory System Design: SRC AIHW Annual Review - 22.05.2023
Professor Onur Mutlu’s SRC AIHW review outlines how traditional memory hierarchies strain under AI/ML workloads, prompting a shift toward memory‑centric and processing‑in‑memory (PIM) architectures. He highlights recent research on RowHammer mitigation, intelligent memory controllers, and cross‑layer co‑design that fuse compute...

P&S Understanding and Designing Modern Storage Systems - L1: Course Introduction (Spring 2026)
The video introduces the Spring 2026 iteration of the "Understanding and Designing Modern Storage Systems" course, led by Professor Onur Mutlu’s Safari Research Group at ETH Zurich, along with instructors Rakesh Nadig and Dr. Mohamed Sadati. It outlines the team’s...

Digital Design & Computer Architecture - Problem Solving IV (Spring 2022)
On August 5, 2022, Professor Onur Mutlu delivered the fourth problem‑solving lecture for ETH Zürich’s Digital Design & Computer Architecture spring 2022 course. The session focuses on memory‑centric computing, covering processing‑in‑memory, RowHammer mitigation, and intelligent architecture design. Full slide decks,...

Memory-Centric Computing: Eda Workshop Keynote Speech by Prof. Onur Mutlu, 08.05.2023
Professor Onur Mutlu’s May 8, 2023 keynote introduced memory‑centric computing as a paradigm shift that moves processing logic closer to data storage. He highlighted processing‑in‑memory (PIM) techniques that cut data‑movement costs and outlined recent advances in resilient memory architectures. The talk revisited...

P&S: Architectures & Algorithms for Health & Life Sciences - L1: Course Introduction (Spr 2026)
Welcome to the first lecture of the ETH Zurich “Architectures & Algorithms for Health and Life Sciences” project‑seminar, presented by PhD candidate Nika Mansuriyasi. The session outlines the course’s scope, objectives, and its relevance amid accelerating biotechnological data generation. Mansuriyasi explains...

Digital Design & Computer Architecture - Problem Solving III (Spring 2022)
On July 19, 2022 Professor Onur Mutlu delivered the third problem‑solving lecture for ETH Zürich’s Digital Design & Computer Architecture spring 2022 course. The session’s slide deck and video are available online, alongside a curated list of seminal papers on...

Memory-Centric Computing - Talk at IEEE Custom Integrated Circuits Conference - Prof. Onur Mutlu
Prof. Onur Mutlu opened the IEEE Custom Integrated Circuits talk by framing memory‑centric computing as a response to exploding data volumes in AI, genomics, and other data‑intensive workloads. He highlighted that while CPUs, GPUs, and accelerators have grown more powerful,...

Digital Design & Computer Architecture - Problem Solving II (Spring 2022)
The video walks through a textbook‑style problem on branch prediction and then shifts to designing a systolic array for matrix multiplication, illustrating two core concepts in computer architecture. It defines locally correlated branches—where knowledge of a previous iteration predicts the current...

Memory-Centric Computing - Winter School on Operating Systems (WSOS) Opening Talk - 03.04.2023
In his opening talk at the Winter School on Operating Systems, Prof. Onur Mutlu introduced Memory‑Centric Computing, a paradigm that repositions memory from a passive storage element to an active compute resource. He highlighted the performance and energy penalties of...

Digital Design & Computer Architecture - Problem Solving I (Spring 2022)
ETH Zürich’s Digital Design and Computer Architecture course released a new Problem Solving I session on July 5, 2022, led by Professor Onur Mutlu. The 2‑hour lecture walks through key topics such as finite‑state machines, the MIPS ISA, dataflow, pipelining,...

Digital Design & Computer Architecture - Lecture 27: Epilogue (Spring 2022)
The video serves as the concluding epilogue of a Spring 2022 digital design and computer architecture course, reviewing the material covered and emphasizing the central role of critical thinking in hardware design. It recaps the curriculum—from transistors to virtual memory, instruction...

Digital Design & Computer Architecture - Lecture 26a: Virtual Memory II (Spring 2022)
The lecture expands on virtual memory implementation details, focusing on page-table size and storage using multi-level page tables, x86-64’s 64-bit page-table entries, and support for multiple page sizes (4KB, 2MB, 1GB). It reviews control registers (e.g., CR3), context-switch implications for...

Digital Design & Comp. Arch. - Lecture 26: Virtual Memory (Spring 2022)
Professor introduces virtual memory as a core OS–architecture interface, tracing its roots to 1960s ideas and contrasting its relatively little evolution with the rapid advances in prefetching. The lecture previews key VM concepts, implementation complexity, and performance overheads, and highlights...

Digital Design & Comp. Arch: L2: Transistors, Gates, Combinational Logic (Spring 2026)
The lecture introduced the fundamentals of digital design by tracing the evolution from individual MOS transistors to combinational logic circuits. It emphasized that modern computers are built from billions of transistors, citing the Intel 4004’s 2,300 transistors, the Pentium 4’s 42 million,...

Memory-Centric Computing - Invited Talk - Systems Research Community @ France - 29.11.2022
In an invited talk on memory-centric computing, ETH professor Uno (likely Onur?) argued that modern systems are increasingly bottlenecked by data movement rather than compute, driven by exponential growth in datasets from domains like neural networks and genomics. He highlighted...

Digital Design & Computer Architecture - Lecture 25: Prefetching (Spring 2022)
The penultimate lecture of the Spring 2022 Digital Design & Computer Architecture series focuses on prefetching – the proactive loading of data into cache or registers before it is demanded by the processor. The instructor emphasizes that prefetching is one of...
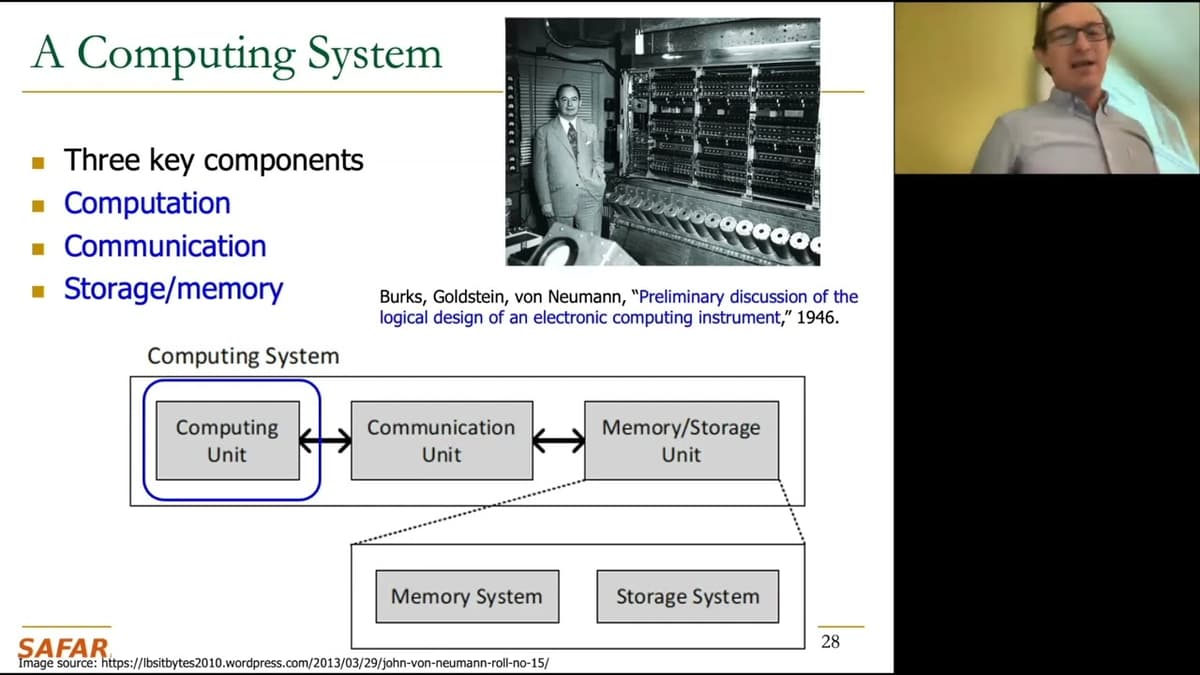
Memory-Centric Computing - Talk at UCLA - 29.11.2022
Professor Onur Mutlu outlined the case for memory-centric computing, arguing that modern workloads—especially machine learning and genomics—generate far more data than current systems can efficiently process. He highlighted trends like wafer-scale processor designs and high-bandwidth memory attachments as steps toward...

Digital Design & Computer Architecture - Lecture 24a: Multi-Core Caches (Spring 2022)
The lecture examines cache design challenges in multicore and multithreaded systems, highlighting trade-offs between private and shared caches. Shared caches improve utilization, reduce data replication and communication latency, and align with shared-memory programming, while private caches avoid contention and offer...

Digital Design & Computer Architecture - Lecture 24: Advanced Caches (Spring 2022)
In this lecture on advanced caches the instructor reviews memory hierarchy principles and current extensions, including remote memory and memory-blade architectures used to support data‑intensive applications. He revisits basic cache designs (direct‑mapped, set‑associative, fully associative), explaining how associativity trades off...

Accelerating Genome Analysis - Montenegro Academy of Sciences Conference, 3.11.2022
In a recorded talk for the Montenegro Academy of Sciences, the speaker outlined the urgent need to accelerate genome analysis, concentrating on the read-mapping bottleneck that impedes turning high-throughput sequencing outputs into actionable genomic insight. He traced advances in sequencing—especially...

Digital Design & Comp. Arch: L1: Introduction: Fundamentals, Transistors, Gates (Spr 2026)
The lecture is an introductory session to digital design and computer architecture, framing the course as a ground-up exploration of how computers are built—starting from CMOS transistors as the fundamental switching element and progressing to logic, arithmetic, memory, and whole...