

HM - SGM _ System GPU Management - Workstream - (2026-01-16)
The meeting focused on the System GPU Management workstream, reviewing agenda changes, attendance constraints, and the need to push forward a GPU‑related presentation despite several participants being unavailable. The team revisited open GitHub issues, agreeing to retag those still relevant to the newer 1.1 and 1.7 releases while archiving legacy 1.0 items, streamlining the backlog for upcoming releases. Key technical discussion centered on how to model GPU‑related events within the existing DNTF message registry framework. Participants examined whether to reuse the network‑device registry, extend it, or create a dedicated GPU device or GPU‑fabric registry. They highlighted that many proposed GPU messages map cleanly onto network‑device definitions, but a subset lacks appropriate mapping, prompting a short‑term proposal to add specific port‑related messages and rename ambiguous terms like “degraded.” The dialogue also explored subscription mechanics, emphasizing that consumers need precise filters to receive only GPU‑specific events without enumerating numerous origin conditions. Examples from sensor registries illustrated the challenges of dynamic URIs and the risk of stale subscriptions. Consensus emerged around a hybrid approach: employ the network‑device registry for generic link events, introduce a GPU‑device registry for point‑to‑point connections, and consider a separate GPU‑fabric registry when topology resembles switch‑level fabrics. Implications include a clearer, more maintainable message taxonomy, reduced duplication across registries, and faster integration of GPU monitoring capabilities into existing tooling. By aligning terminology and registry design now, the group aims to support future accelerator workloads—such as AI inference—while minimizing long‑term engineering overhead.

HM - FMFM _ Fleetscale Memory Fault Management - Workstream - (2026-01-13)
The FMFM workstream convened to review progress on Fleetscale Memory Fault Management, focusing on logging requirements, standards adoption, and recent research presented by Roy. Participants debated whether to prioritize DDR5 or LPDDR logging, noting DDR5’s easier integration with existing specifications...

How SONiC Powers the World's Largest AI Infrastructure
The presentation introduced Microsoft’s Fairwater AI data center, the world’s largest AI infrastructure built on Broadcom’s Tomahawk 5 ASICs and the open‑source SONiC network operating system. It explained why AI traffic differs fundamentally from traditional workloads: tens of thousands of GPUs...

FTS Sustainability Lightning Talks
The Future Technology Symposium’s Lightning Talks on Sustainability showcased cutting‑edge solutions for data‑center power, cooling and backup. Speakers from BE, Tokamak Energy, Creatine, InLight Energy and Excelsior presented technologies ranging from superconducting power distribution to advanced two‑phase cooling and novel...

FTS AI/HPC Lightning Talks
The OCP AI/HPC Lightning Talks showcased emerging solutions aimed at breaking the power wall in modern data centers. Phil from Lumi introduced optical compute, explaining how encoding vectors as light and matrix weights as transmissive pixels enables matrix‑multiply‑accumulate operations with...

Data Quality Scoring System for Datacenter IT Embodied Carbon Accounting
Meta and Google unveiled a data‑quality scoring system aimed at standardizing embodied‑carbon accounting for datacenter IT components. The presentation outlined a two‑tiered approach— a simple “core” model for bulk scoring and an “advanced” model for high‑impact items—intended to be industry‑wide. The...

Scaling Design for Sustainability Across Meta's Hardware Organization
Meta’s hardware teams presented a systematic, AI‑driven Design for Sustainability framework that scales carbon‑footprint estimation across the entire rack portfolio. Leveraging the OCP PCR taxonomy, AI tools automatically map early‑stage specifications to component carbon data, select the highest‑quality scores, and...

Low-Temperature Waste Heat to Cooling: High-Power-Density Adsorption Chillers for De-Electrified Coo
The presentation introduced Thermal Transformer’s low‑temperature adsorption chiller, a system that captures waste heat from GPU clusters and converts it into usable cooling for data‑center environments. By leveraging a rapid thermal‑swing absorption cycle, the prototype can provide 100 kW of cooling...

Reducing Material Intensity and Lifecycle Emissions Using Superconducting Power Distribution in AI D
The presentation highlighted superconducting power delivery as a solution to the soaring energy demands of AI‑driven data centers. By replacing traditional copper busbars with high‑temperature superconducting (HTS) cables, providers can transmit up to 20 MW per 800 VDC cable and 240 MW at...

Scaling AI Infrastructure with Open Systems and Arm-Based Silicon
ARM unveiled a purpose-built data-center CPU optimized for agentic AI, leveraging 136 Neoverse V3 cores and a balanced I/O and memory design to prioritize low-latency inference and power efficiency. The company is delivering OCP-compliant reference servers including a oneU design...

Data Center Compute Evolution
Meta's software engineer Paul Saab highlighted power as the primary constraint on AI data‑center growth. The company is tackling the issue by deploying power‑efficient CPUs and integrating LPDDR memory into its servers. Saab also emphasized the role of open‑hardware collaborations,...

Server - HPC _ High Performance Computing - Sub-Project - (2026-04-14)
The OCP HPC sub‑project held an informal meeting to reassess its roadmap after a recent funding application fell through. Participants discussed the need to reboot the effort, benchmark against Nvidia’s latest Vera Rubens chiplet advances, and explore new partnership opportunities. A...

Server - HPC _ High Performance Computing - Sub-Project - (2026-03-31)
The meeting focused on Nvidia’s latest high‑performance computing platform – the Vera Rubin Ultra built on the Kyber rack blade architecture. Presenter Andrew walked the team through the hardware specs revealed at GTC, highlighting the shift from the Grace Blackwell...
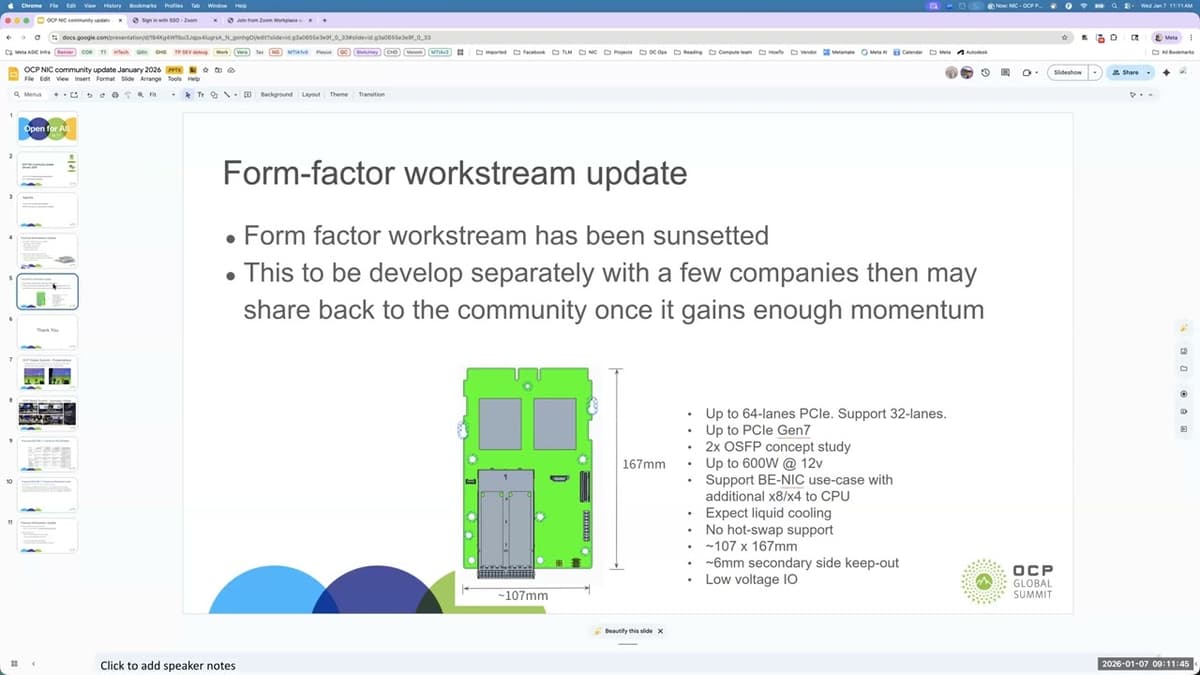
Server - Mezz NIC - Sub-Project - (2026-01-07)
The meeting was a monthly status call for the Server Mezz NIC sub‑project, kicking off after the holiday break. Participants provided brief personal updates before diving into technical workstreams. The thermal workstream reported that the TSF specification, including hot and cold...

Networking - SAI _ Switch Abstraction Interface - Sub-Project - (2025-12-11)
The meeting presented a proposal for a Switch Abstraction Interface (SAI) layer tailored to Optical Circuit Switch (OCS) hardware. The team outlined how the abstraction will expose cross‑connect and port‑level functions, enabling vendors and operators to manage OCS resources through...