

Boost Detector Accuracy with Hard Mining, Not Bigger Models
🎯 Title: Stop Making Your Model Bigger — Do This Instead Your object detector confuses 2 classes? Don't scale up. Scale smart. In this reel, I break down the fine-grained recognition problem and show you the exact 2-step fix used by top AI teams — from hard example mining to triplet loss. Same data. Same compute. 100x better results. 🧠 #ComputerVision #ObjectDetection #MachineLearning #DeepLearning #AIEngineer #OpenCV #FineGrained #MLTips #PyTorch #ModelTraining #AIResearch #TechReels #DataScience #NeuralNetworks #CVEngineer

AI Failures Can Cost Lives: Proceed with Caution
The GM case is a reminder that AI failures have real-world consequences, emphasizing the need for caution. https://t.co/L3EubqCtLF

Image Processing Enhances Pictures; Computer Vision Extracts Meaning
👁️ Image Processing vs Computer Vision Back in 1999, I learned the subtle but powerful difference: ✨ Image Processing → Input: Image 📷 → Output: Image 🖼️ (e.g., noise reduction, edge detection, compression) 🤖 Computer Vision → Input: Image 📷 → Output:...

Chatting with AI Saves Hours of Data Crunching
A simple conversation with an AI can replace hours spent navigating dashboards and spreadsheets. https://t.co/qyinfRp62J

Verification Checks Claim, Recognition Finds Identity
🔍 Face Recognition vs Face Verification 🔑 Face Verification → Confirms if someone is who they claim to be (Yes ✅ / No ❌). 🧑🤝🧑 Face Recognition → Identifies who the person is by comparing against many faces 👥. #FaceRecognition #FaceVerification #AI...

Connected Component Analysis: Turning Pixels Into Meaningful Objects
Turning Pixels into Meaning: Connected Components Ever wondered how computers count shapes in an image? 🖼️✨ Connected Component Analysis labels each blob in a binary image so pixels with the same label belong to the same object. From background = 0...

AI Agents Let You Build Vision Apps without Coding
🚀 Building a Computer Vision app - without writing a single line of code. In this walkthrough, we used an AI coding agent to create a real-time face detection application that can blur or pixelate faces on a live...

Transformers Overtake CNNs in Speed and Accuracy
CNNs vs. Transformers: The Final Showdown 🏆 CNNs like YOLO ruled computer vision for years because of one thing: speed. But the era of Transformer dominance is finally here. From the first ViT in 2020 to 2024’s lightning-fast RT-DETR and DEfine,...

Unified Latents Merge Vision, Video, and Text
Unified Latents: Bringing Images, Video, and Language Into One Shared AI Space In this episode of Artificial Intelligence: Papers and Concepts, we explore Unified Latents, a new approach that aims to merge different types of data - images, video, and text...

AlphaGo Masters Go in a Day, Humans Need Years
Humans need years to master Go, but AlphaGo learned it from scratch in just one day. https://t.co/liP5JLyo6s

Hardware Acceleration Drives OpenCV Speed Differences
OpenCV Speed Secrets: Hardware Acceleration Explained Why does OpenCV fly on some devices but crawl on others? 🚀🐢 It’s not just your code-it’s hardware acceleration. Behind the scenes, OpenCV swaps generic C++ routines for optimized backends like Intel IPP, ARM NEON,...

Humans Must Design and Verify AI for Quality
AI can act, but humans must architect and validate to ensure correctness and quality." https://t.co/9u9k1ppkOI

AI Scans Passports, Then Verifies Their Authenticity
Beyond the Scan: How AI Verifies Your Passport Every time you scan your passport, AI is doing more than just reading your name. 🛂✨ It’s verifying authenticity-analyzing hidden security patterns, specialized fonts, UV inks, and even subtle photo tampering. What looks...

DeepSeek‑V3 Shows Efficient Scaling Beats Brute‑Force
DeepSeek-V3: Scaling Open Reasoning Models With Efficiency and Precision In this episode of Artificial Intelligence: Papers and Concepts, we explore DeepSeek-V3, a next-generation large language model designed to push the boundaries of reasoning performance while maintaining strong efficiency. Rather than relying...
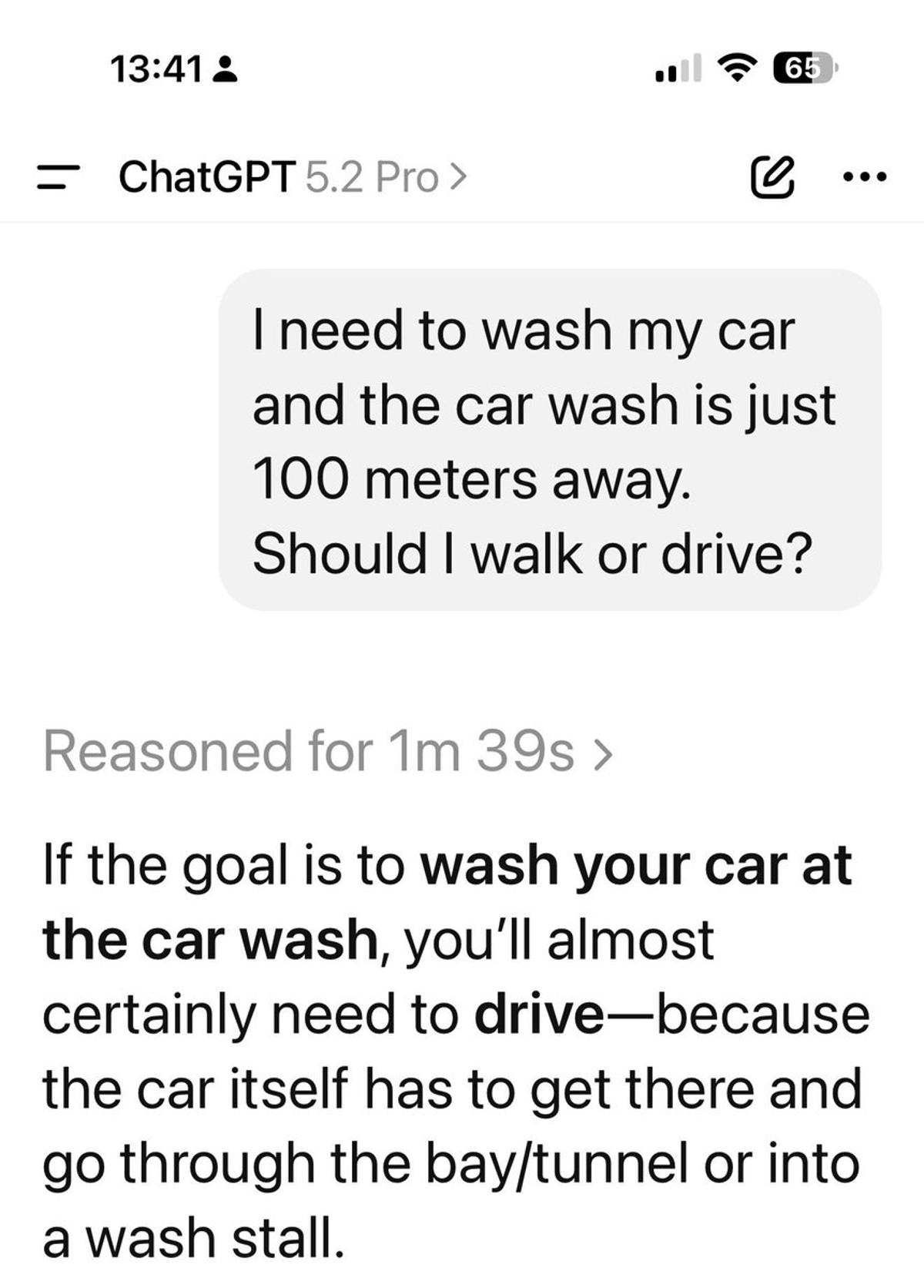
Pro AI Models Outperform Free Versions, Delivering Correct Answers
There is a vast difference between free models and pro models. Grok expert and ChatGPT 5.2 pro both gave the right results. I can confirm the regular ChatGPT 5.2 tells you to walk. https://t.co/8mTPUcwRpZ

AI Must Train on Real‑world Data, Not Idealized Datasets
To succeed, AI systems must be tested and trained on real-world conditions, not just idealized data. https://t.co/HFZ8yPwycm
AI Lets Anyone Craft Complex Images in an Hour
I created this image in about 1 hour using AI prompts after about a dozen tries. The worst part is that I had to carefully check the image after every attempt because the mistakes it was making were subtle....

Speculative Decoding Doubles LLM Speed Without Quality Loss
This Trick Makes LLMs 2X Faster Autoregressive decoding has a hard ceiling-one token at a time. Speculative Decoding uses a "draft" model to jump ahead without losing quality. #Innovation #AI #FutureTech #Python https://t.co/OgsON1kbzw

Repeating Prompts Boosts LLM Performance Without Extra Compute
Repeat, Repeat: Why Simply Repeating a Prompt Can Make LLMs Smarter In this episode of Artificial Intelligence: Papers and Concepts, we explore the surprisingly simple idea behind “Prompt Repetition Improves Non-Reasoning LLMs,” a new study from Google Research that challenges how...

Unverified AI Decisions Risk Catastrophic Consequences
Relying on AI to make important decisions without verification can lead to catastrophic outcomes. https://t.co/PZYzLfjyYE

AI Agents Let You Build Vision Apps without Coding
🚀 Building a Computer Vision app - without writing a single line of code. In this walkthrough, we used an AI coding agent to create a real-time face detection application that can blur or pixelate faces on a live video feed....

Share One Base Model, Deploy Many LoRA Adapters Efficiently
Why Fine‑Tuned Models Break the Bank 💸 Every LoRA adapter shouldn’t need its own full base model copy. That’s how dozens become hundreds… and inference becomes impossible. 👉 Multi‑LoRA serving fixes this: one base model, many adapters, applied per request with custom...

Seedance 1.0 Elevates AI Video to Production‑Ready Storytelling
Seedance 1.0: The Next Leap in AI Video Generation In this episode of Artificial Intelligence: Papers and Concepts, we explore Seedance 1.0, a new foundation model from ByteDance that is pushing the boundaries of AI-generated video. Positioned at the top of...

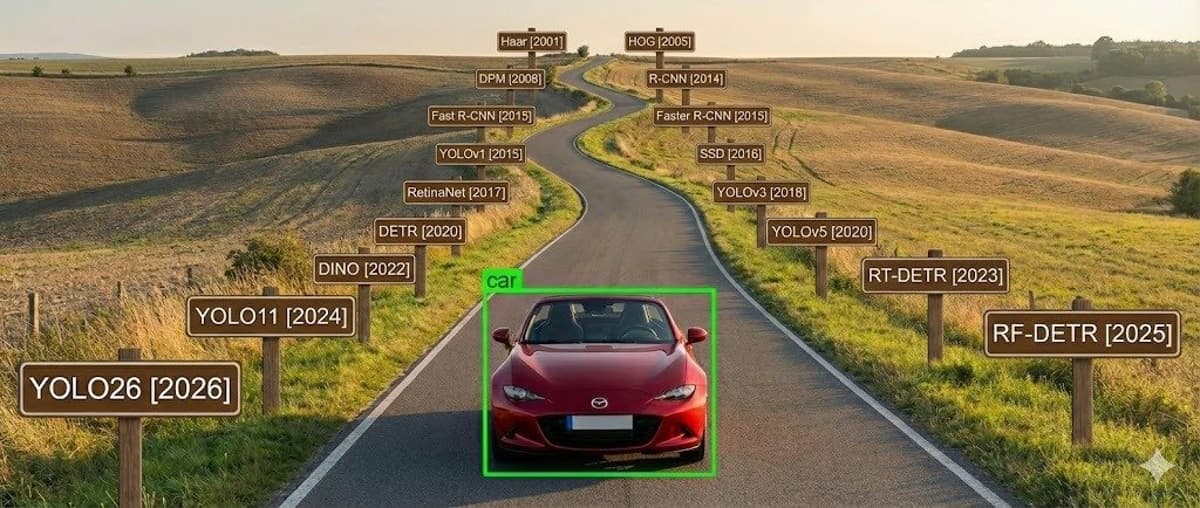
Transformers Overtake YOLO with Real‑Time Detection
Is YOLO officially dead? 💀 RFDETR (Roboflow Detection Transformers) just redefined real-time detection. ✅ Object Detection ✅ Instance Segmentation ❌ No Keypoints (yet) This is why Transformers are taking over. https://t.co/6LXlbsGWJt

Chunked Prefill Prevents Token Starvation From Long Prompts
How Long Prompts Break AI Apps 🚫 A single 128K prompt can starve other users of tokens. Use Chunked Prefill to keep time-to-first-token low. #ProgrammingTips #GenerativeAI #DataScience #Tech https://t.co/BJGFm8dxAk

Fluency, Not AI Smarts, Undermines Human Judgment
Human judgment is under threat not because AI is smart, but because we confuse fluency with understanding https://t.co/sLuxpkk0uz

LoRA Enables Cheap, Efficient Fine‑Tuning of Giant Models
LoRA: Teaching Massive AI Models New Skills Without Retraining Everything In this episode of Artificial Intelligence: Papers and Concepts, we break down LoRA (Low-Rank Adaptation) - a breakthrough technique that makes fine-tuning large language models faster, cheaper, and far more efficient....

AI Generates Statistical Results, Not Guaranteed Software Outputs
AI differs from software; outputs are statistical, not guaranteed, requiring careful training and evaluation. https://t.co/4SGQMgdys0

AI Solves 1966 Wembley Goal Controversy with Computer Vision
Wembley Goal: How Computer Vision Settled Football’s Most Controversial Moment In this episode of Artificial Intelligence: Papers and Concepts, we revisit the legendary 1966 World Cup Final and the infamous “Wembley Goal” - a moment that sparked decades of debate between...

AI Boosts Human Art Beyond Average Capabilities
AI now helps humans create art that surpasses what average people could do alone. https://t.co/bPHG3R2sCX

Continuous Batching Eliminates Slow AI Chat Bottlenecks
Why Your AI Chat is Slow (Static Batching) ⏳ Static batching means one slow request blocks everyone else for seconds. Here is how Continuous Batching solves the "slowest user" problem #Coding #DevOps #AIModel #Latency https://t.co/CRe945HeYs

Industrial and Medical AI Drive Real Profits, Not Hype
Flashy AI tools make headlines, but industrial or medical AI often generates the real profits. https://t.co/phSUIEUOy5

Drop HOG: Modern DNN Detectors Outperform Legacy Methods
Still using HOG for object or pedestrian detection? You probably shouldn’t. HOG was great years ago, but today it’s slow, fragile to viewpoint changes, and struggles with small or occluded objects. Modern deep learning detectors in OpenCV — like U-Net (faces), YOLO,...

Panoptic Segmentation Unites Class Labels and Object Instances
Semantic vs Instance vs Panoptic Segmentation — explained 🟦 Semantic Segmentation: assigns a class label (person, road, tree, sky, etc.) to every pixel. ✅ You know what the pixel is — ❌ not which exact object (person 1 vs person 2). 🧍♂️ Instance...

Clean Canny Edges with Simple Input Tweaks
Messy Canny edges? It’s usually not the algorithm — it’s the input. This video shows 3 quick fixes to clean up noisy edge detection: • Blur before applying Canny • Tune lower & upper thresholds (keep a 2:1–3:1 ratio) • Avoid over-compressed images Small tweaks,...

DeepSeek Reveals Signal Distortion Causes Deep Net Instability
1/11 One of the most important papers of 2025 is DeepSeek's "mHC: Manifold-Constrained Hyper-Connections" To understand it, let's start with a fundamental question. Why do very deep neural networks suddenly blow up during training? Short answer: signals get distorted as they...

Image Segmentation: Masks, Labels, and Pseudocolor Visualization
Image segmentation = dividing an image into pixel groups (regions). A segmentation model takes an image and outputs segments, usually as masks (more common than contours). In masks, each segment gets a different grayscale label, and we often use pseudocoloring to visualize...

One-Hot Encoding: Simple Vector Labels for Classification
🔢 One-Hot Encoding Classes are represented as vectors. Only one value is 1, the rest are 0 — indicating the correct label. That’s why it’s called one-hot. Simple, but essential for classification models. #MachineLearning #DeepLearning #AI #DataScience #ComputerVision #NeuralNetworks #MLBasics #AIEducation

Image Processing Returns Images; Vision Extracts Information
🖼️ Image Processing vs Computer Vision Image processing = image in, image out Filtering, enhancement, JPEG compression — the output is still an image. 👁️ Computer vision = image in, information out Face recognition, car counting, object detection — the output is knowledge. Even when...

MAML Enables AI to Learn New Tasks Instantly
🚀 What if your AI could learn a brand-new task after just 1 or 2 examples? That’s the promise of few-shot learning — and MAML (Model-Agnostic Meta-Learning) makes it real. Instead of thousands of samples, MAML teaches models to adapt instantly with...

Computer Vision: Machines Interpreting Visual Data Beyond AI
Computer Vision isn’t “just AI.” It’s how machines interpret visual data—from cameras to X‑rays to telescopes—solving tasks like detection, recognition, OCR, and 3D reconstruction. #ComputerVision #AI #MachineLearning #DeepLearning #ImageProcessing https://t.co/KhVODmTBBU

Nvidia's Nemotron‑3 Name Decodes Model Specs
Nvidia just dropped Nemotron‑3 — and yes, the names look complicated… but they actually tell a story. Take Nemotron‑3 Nano‑30B‑A3B‑FP8: • Nemotron‑3 → 3rd gen family, smarter + more efficient • Nano → smallest tier, optimized for deployment • 30B →...

Why Naive Transformers Stall Production LLM Serving
📢 The Existential Problems in LLM Serving Naive Transformers might be fine for lab experiments - but they don’t hold up in production. The real challenge lies in Autoregressive Inference, where performance bottlenecks can cripple even the most powerful GPUs. If you’ve...

From Rules to Data: How Machines Truly Learn
What is Machine Learning? From rule-based AI to data-driven learning — this video explains how machines learn from data, why traditional rules failed, and how Machine Learning fits into the bigger AI picture. #MachineLearning #ArtificialIntelligence #AIExplained #DeepLearning #ComputerVision

AI Development Mirrors Toddler Learning Stages
Ai learns like toddlers https://t.co/LmasDvAlfu

Cut Image Copies, Boost Computer Vision FPS
⚡ Speed up your Computer Vision code ⚡ Is your pipeline running slower than it should? You might be cloning/copying images too often — and paying the cost in memory allocations and data movement. 💡 Quick fixes: ✅ Prefer assignment (Mat B =...

SAM-3 Runs on Gaming GPUs, Fuels Lightweight Models
Can SAM-3 run on a normal consumer GPU, or do you need massive compute and a billion-dollar data center? In this video, we break down the real answer. Spoiler: yes… and no. You’ll learn: ☑️Whether SAM-3 can run...

AI Transforming Everyday Workplaces Across Industries
Ai in real world jobs https://t.co/ijr1aU871K

SAM 3D Delivers High‑Fidelity Single‑Image 3D Reconstruction
📢SAM 3D: Single-Image 3D Reconstruction with Foundation-Model Reliability In this week’s deep dive, we break down SAM 3D, Meta’s groundbreaking framework that redefines what’s possible in single-image 3D reconstruction. Unlike earlier pipelines that struggle with occlusions, clutter, and ambiguous textures, SAM...

Quality Data Drives Accuracy When Fine‑Tuning YOLO
A big issue with getting these computer vision models to keep high accuracy is to provide actual good data. I don’t make these CV models from scratch, I just fine tune YOLO models, and those are already built off of...