
Sung Kim
Semiconductor technologist/investor commenting on ASML and EUV deployment; brings practitioner insight on Europe’s chip equipment leader and related equity narratives.

MLPerf v6.0 Adds MoE Benchmarks, Showcasing 671B DeepSeek
MLCommons Releases MLPerf Training v6.0 Results Two Mixture-of-Experts (MoE) benchmarks were added, reflecting where the AI training frontier actually is. 📍 DeepSeek V3 — 671B params (largest in MLPerf history) 📍 GPT-OSS 20B — 21B params https://mlcommons.org/2026/06/mlperf-training-v6-0-results/

Zhipu AI Launches GLM‑5.2 for All Coding Plan Users
Z AI or Zhipu AI released GLM-5.2 (Not open-weight yet?) It is available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans. http://docs.z.ai/devpack/latest-model

Meta's AI Team Likened to Soul‑crushing Gulag
Yeah, I was right... "Their assigned work? Generating puzzles and coding problems to train AI models. “It’s literally the gulag,” one employee told Wired. “Most people find the work soul-crushing,” said another." https://techcrunch.com/2026/06/12/metas-months-old-ai-unit-is-a-soul-crushing-gulag-say-the-engineers-stuck-inside-it

Kimi‑K2.7‑Code Boosts Performance, Cuts Reasoning Tokens
Moonshot AI's Kimi-K2.7-Code - Improved coding & agent performance over K2.6: +21.8% on Kimi Code Bench v2, +11.0% on Program Bench, and +31.5% on MLS Bench Lite. - Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6. - Long-horizon coding:...
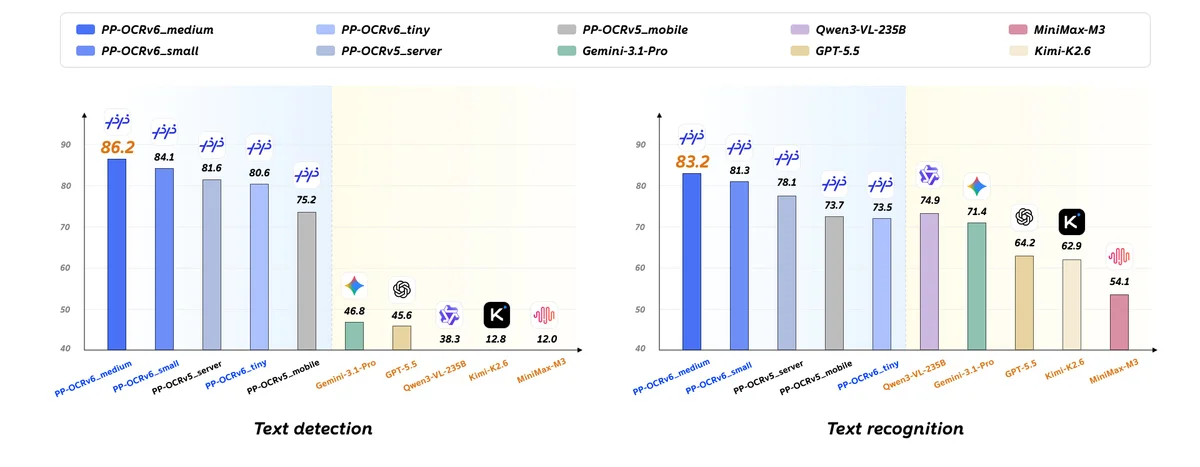
PaddleOCR's PP-OCRv6 Boosts Accuracy and Speed Across Devices
Baidu's PP-OCRv6 looks impressive. PaddleOCR’s new OCR model series scales from 1.5M to 34.5M parameters, bringing stronger accuracy, faster inference, and broader deployment options — from browsers and edge devices to servers. Web: https://paddleocr.com Repo: https://github.com/PaddlePaddle/PaddleOCR Models: https://huggingface.co/collections/PaddlePaddle/pp-ocrv6

Anthropic's Fable Flags Content, Hinders Security Testing
Anthropic: Use Fable/Mythos to harden your app against security threats. Me: Tries to use Fable/Mythos to harden my app against security threats. Also, Anthropic: Fable 5's safety measures flagged this message for cybersecurity or biology topics. They may flag safe, normal content...

Decentralized AI Agents Conduct End‑to‑End Scientific Research
AutoScientists: a decentralized team of AI agents that can generate hypotheses, design experiments, write code, test ideas, analyze failures, and revise strategy as evidence accumulates.
StepFun AI's Flash Delivers 400
StepFun AI's Step 3.7 Flash (open-weight) 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels, built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution.

Neural Weight Norm Mirrors Kolmogorov Complexity
He finds that neural networks may be biased toward the simplest fit that explains the data OR the neural network with the smallest possible weight norm (that fits the data) must encode the shortest program (that fits the data). "Neural Weight...

FlashLib Delivers up to 208× GPU Speedup for Classic ML
FlashLib - a GPU library for fast, predictable, agent-ready classical ML operators. "Up to 26× on KMeans, 19× on KNN, 40× on HDBSCAN, 208× on TruncatedSVD, 47× on PCA, 147× on exact t-SNE, and 49× on MultinomialNB over state-of-the-art (cuML)." Blog: https://flashml-org.github.io Code:...

Webwright Lets LLM Browse via Reusable Python Scripts
Microsoft's Webwright: Playwright for AI Agent CLI? Webwright gives LLM a terminal where it can launch multiple browser sessions to inspect the page and complete a web task. It captures and inspects page screenshots/states only when needed. It enforces each web...

GPU Optimizations Are Interlinked, Necessitating Auto‑Tuning
A survey paper on Optimization Techniques for GPU Programming This survey discusses various optimization techniques found in 450 articles published in the last 14 years. They analyze the optimizations from different perspectives which shows that the various optimizations are highly interrelated,...

Parallel Latent Trajectories Boost Test-Time Reasoning Breadth
They propose test time compute should scale not just by thinking deeper, but by thinking wider. They do this by sampling many latent reasoning trajectories, letting the model explore multiple hypotheses in parallel, so they don't follow one deterministic path...
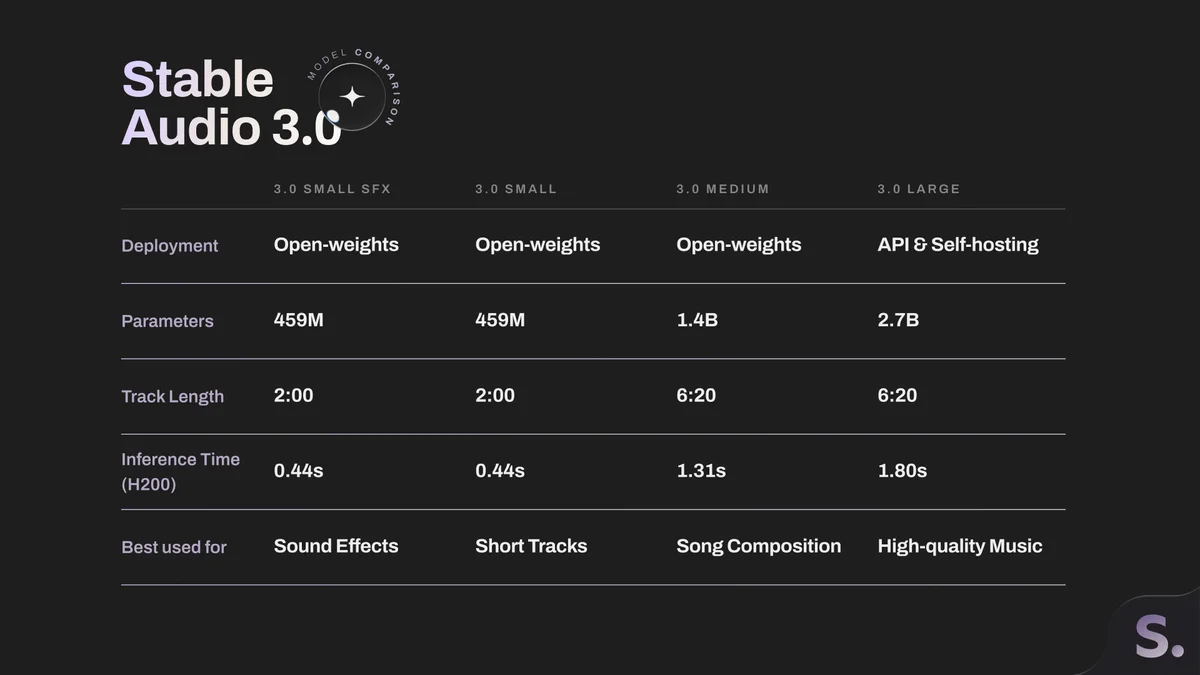
Stable Audio 3.0 Enables GPU-Free Six‑Minute Song Creation
Stability AI release Stable Audio 3.0, the open-weight model family built for artistic experimentation. "New and improved capabilities include variable-length generation up to six minutes, and full song composition on portable devices, no GPU required." Paper: https://arxiv.org/abs/2605.17991 Models: https://huggingface.co/collections/stabilityai/stable-audio-3 Web: https://stability.ai/stable-audio
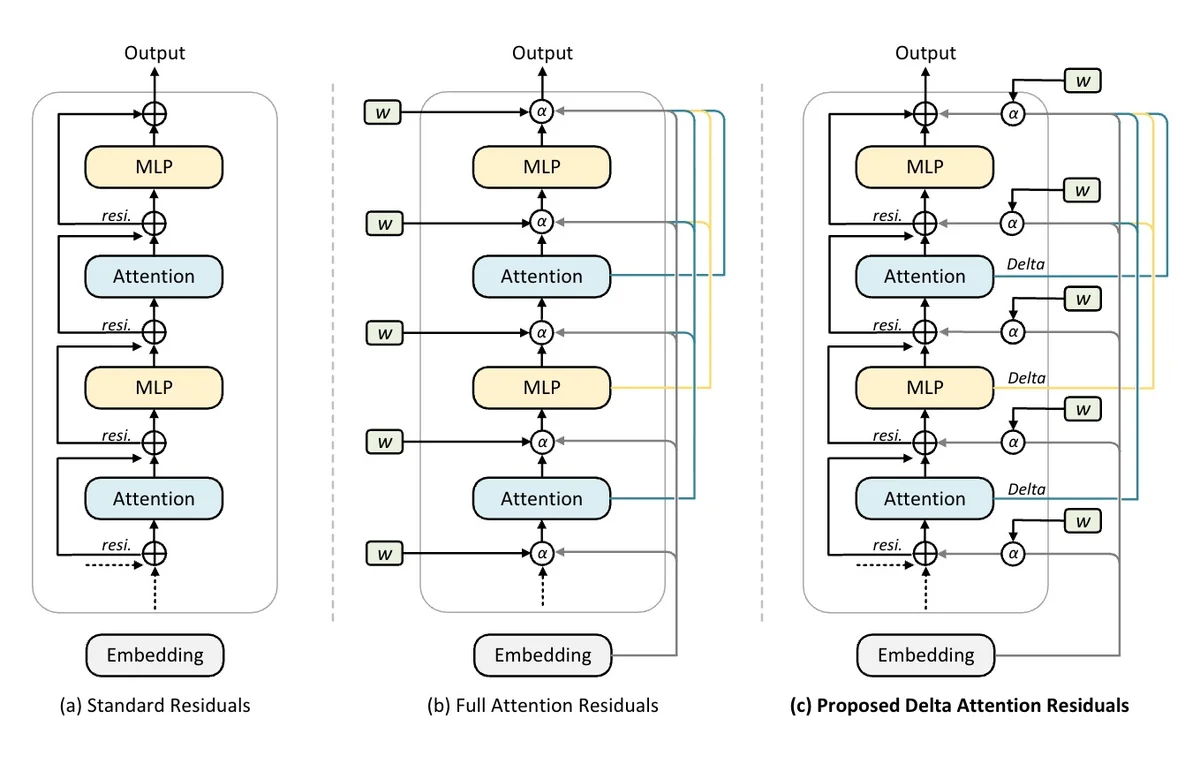
Delta Attention Residuals Learn Optimal Layer Routing
𝐃𝐞𝐥𝐭𝐚 𝐀𝐭𝐭𝐞𝐧𝐭𝐢𝐨𝐧 𝐑𝐞𝐬𝐢𝐝𝐮𝐚𝐥𝐬 A drop-in upgrade to residual connections that learns which past layers to route from, without the routing collapse that breaks prior cross-layer attention at scale.