
Sung Kim
Semiconductor technologist/investor commenting on ASML and EUV deployment; brings practitioner insight on Europe’s chip equipment leader and related equity narratives.

Never Switch AI Models Mid‑Workflow—Lose Your Context
Advice for using Claude Code or Codex: don’t switch models mid-workflow. A model switch is like handing the task to a new engineer with the same laptop, files, terminal history, and notes; but none of the previous engineer’s mental flow. Anything not written down clearly is effectively gone.
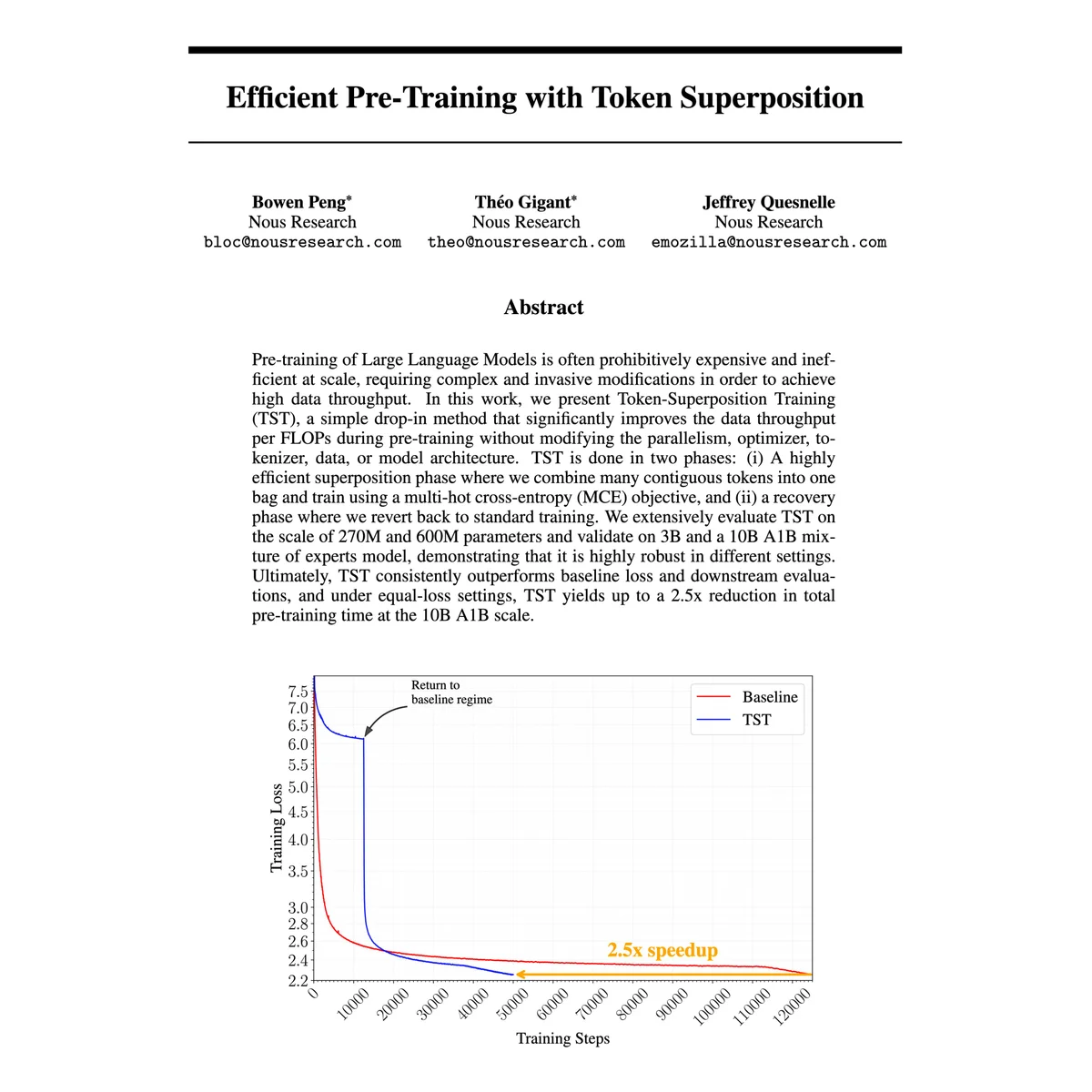
Token Superposition Cuts LLM Pre‑training Time 2‑3×
2x to 3x times faster LLM pre-training without changing the model architecture, optimizer, tokenizer, or training data. Nous Research's Token Superposition Training (TST) During the first third of training, the model reads and predicts contiguous bags of tokens, averaging their embeddings...

4B RL‑fine‑tuned Model
Can a 4B model learn to recursively call itself to answer hard long-context questions? So, they RL fine-tuned a small model to behave as a native RLM. They claim their 4B RLM matches Sonnet 4.6 in quality while running significantly...
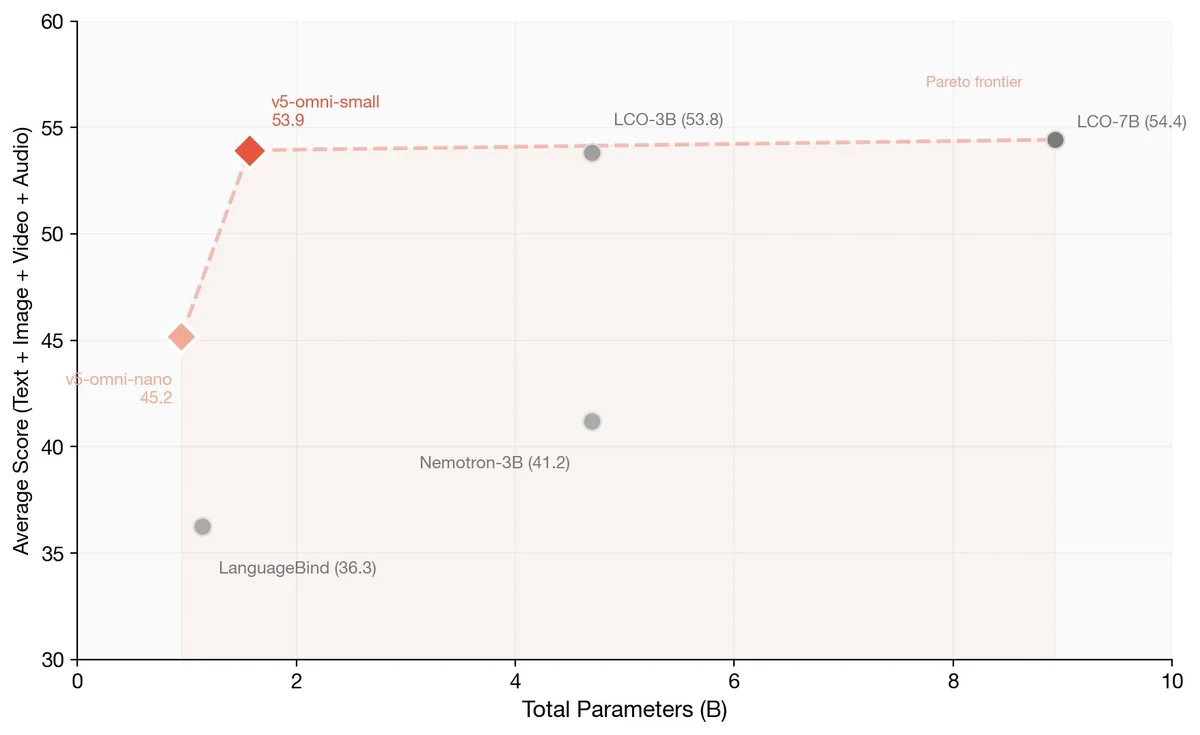
Jina AI Releases Open-Weight Multimodal Omni Embeddings
Jina AI releases open-weight of jina-embeddings-v5-omni Their universal embedding model for text, images, audio, and video. Available in two sizes: small (1.57B, 1024-dim, 32K context) and nano (0.95B, 768-dim, 8K context). Both support Matryoshka truncation down to 32 dimensions.

Programmable Renderers Streamline LLM Chat Template Processing
renderers Programmable chat templates for LLM training and inference. A renderer turns a model's chat template into a Python object that can render messages → token ids, parse completion ids → structured assistant messages, and extend a multi-turn rollout without re-rendering...

Cognition Doubles Devin Usage Biweekly, Hits $445M Run Rate
Just who is paying/using for Devin? "Cognition is also one of the fastest-growing businesses in the history of business, doubling usage of Devin every eight weeks and hitting $445 million of revenue run rate in its first 18 months of service....

Redis Creator Launches DS4 Inference Engine for DeepSeek V4
DS4, a specialized inference engine for DeepSeek v4 Flash, by the creator of redis. github.com/antirez/ds4

Apple's Intel Partnership Validates Foundry, Spurs Industry Adoption
Apple using Intel is a big deal, not just because Apple would be using Intel’s 18A-P or 14A process, but because it would give Intel Foundry a major stamp of approval and make it easier for other customers to follow.

YouTube DJ Sets Blur Live and Curated Performance
I’ve been watching a lot of YouTube videos where DJs play quasi-live music sets. They feel like a traditional live performance, playing a curated playlists with visuals.
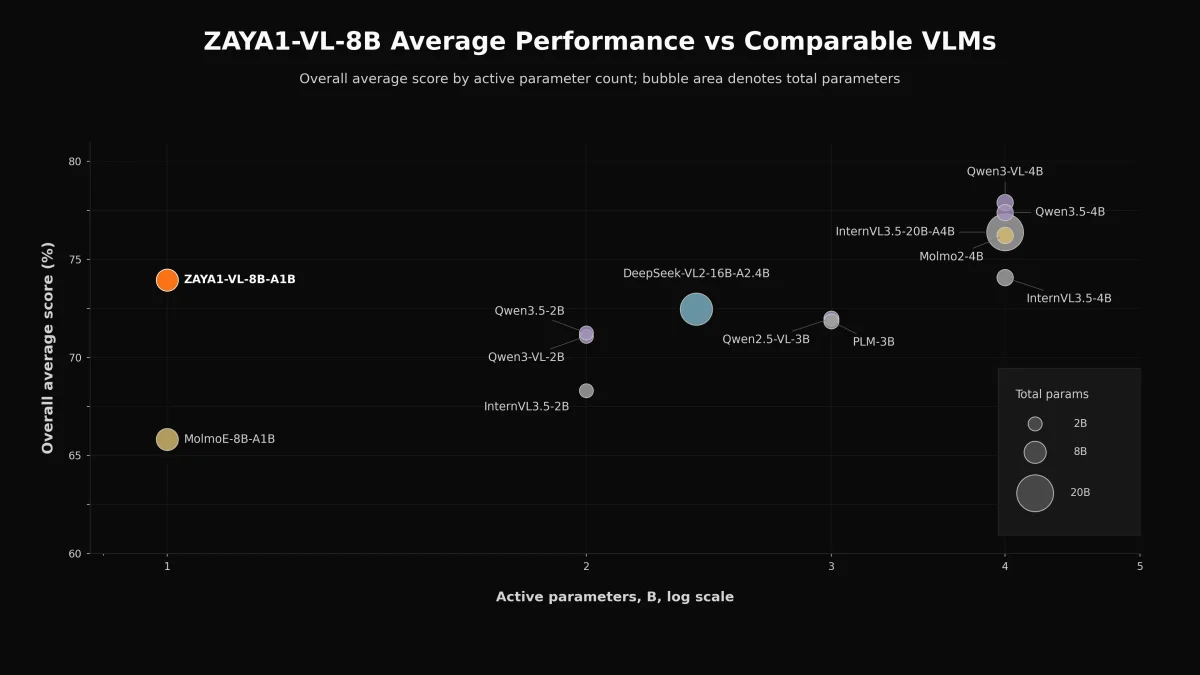
Zyphra Unveils ZAYA1-VL-8B Vision-Language Model
Zyphra (Open Superintelligence AI Lab in SF) released: - ZAYA1-VL-8B, vision-language model Blog: https://zyphra.com/post/zaya1-vl-8b Technical report: http://zyphra.com/zaya1-vl-8b-technical-report Weights: http://huggingface.co/Zyphra/ZAYA1-VL-8B

Claude’s Hidden Activations Decoded Into Readable Text
Anthropic's Natural Language Autoencoders: Turning Claude’s thoughts into text You interact with Claude using language, but Claude processes those words as long lists of numbers, before again producing words as its output. These numbers in the middle are called activations—and like...
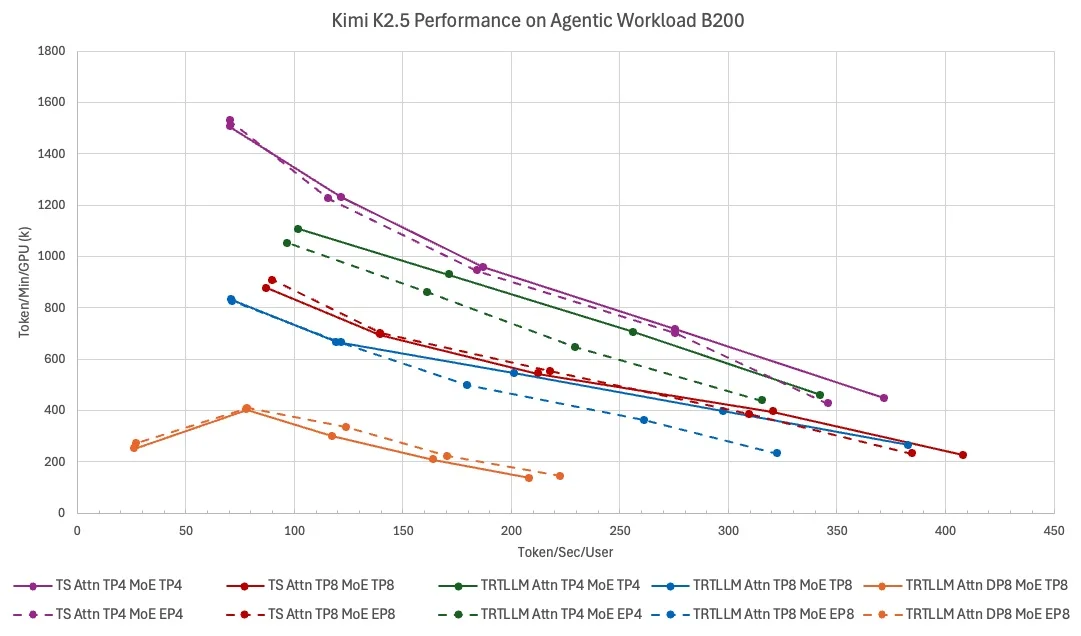
TokenSpeed Delivers Light‑Speed LLM Inference, Open‑Source
LightSeek's TokenSpeed, a speed-of-light LLM inference engine - TensorRT LLM level performance - vLLM level usability - Built by a lean and mission-driven team in two months - MIT license, open-source Blog: https://lightseek.org/blog/lightseek-tokenspeed.html Repo: https://github.com/lightseekorg/tokenspeed

Opus 4.7 Improves While GPT‑5.5 Declines
Is it just me Opus 4.7 (Claude Code) got better, while gpt-5.5 (Codex) got worse.

Deep Nets Learn Real Patterns Fast, Hide Noise Slowly
A Theory of Generalization in Deep Learning by Elon Litman, Gabe Guo Deep learning generalizes because the model learns “real patterns” quickly, while memorizing noise happens slowly and mostly gets hidden in parts of the model that do not matter for...

Building and Scaling RL Environments for the LLM Era
The ultimate guide to RL environments: building and scaling them in the LLM era by Hugging Face https://huggingface.co/spaces/AdithyaSK/rl-environments-guide

MATLAB Agentic Toolkit Integrates AI Coding Assistants
MATLAB Agentic Toolkit MathWorks have released the MATLAB Agentic Toolkit which will significantly improve the life of anyone who is using MATLAB and Simulink with agentic AI systems such as Claude Code or OpenAI Codex. Blog: https://blogs.mathworks.com/matlab/2026/04/13/introducing-the-matlab-agentic-toolkit/ Repo: https://github.com/matlab/matlab-agentic-toolkit

Leave Portable Batteries Behind for Korea‑U.S. Flights
Flying from Korea to the U.S.? You may want to discard your portable batteries before you travel, because airport security may discard them for you anyway.

Brands Profit Selling $30 Glasses Abroad, Not US
Flying from Korea to LA. Interestingly, a lot of brands have their own lines of eyeglasses and sunglasses, selling for about $30 each. It seems like this must be very profitable for them. Something to think about the next time you...

Short Social Media Breaks Boost Weight‑Training Gains
An easy exercise for everyone: weight training 1. Do a set of weight 2. Browse social media for 2 minutes 3. Do a second set of weight 4. Browse social media for 2 minutes 5. Repeat two more times 6. Go to another station 7. Repeat 1-6,...

NIST CAISI Says DeepSeek V4 Pro Wid
NIST Center for AI Standards and Innovation (CAISI) Evaluation of DeepSeek V4 Pro Is gap widening or narrowing? NIST CASI thinks they are widening. https://www.nist.gov/news-events/news/2026/05/caisi-evaluation-deepseek-v4-pro

Agentic Data Creation Turns Inference Power Into Better Training
Meta's Autodata: an agentic data scientist to create high quality data They introduce a method for building agents that create high-quality training & evaluation data where they find that agentic data creation provides a way to convert increased inference compute into...

Separate Review Agent Ensures Safe Autonomous AI Actions
OpenAI's blog Auto-review of agent actions without synchronous human oversight When Codex wants to run a risky action outside its sandbox, a separate Codex agent approves or denies it. The key is separation of concerns: the main agent is optimized to get...

TSMC N2 May Be Delayed, No Adoption Yet
Has anyone asked TSMC whether N2 is delayed? Please note that TSMC excels at incremental improvements. But TSMC N2 is not incremental. It is a major leap from FinFET to GAA/nanosheet. We know that customers such as Bitmain and AMD were expected...

SK Hynix Vest Beats Luxury Brands as Korea’s Dating Dress
In Korea, the ultimate blind-date outfit is not Louis Vuitton, Prada, or any luxury brand. Please — that is so passé. It is an SK hynix employee vest. https://www.koreatimes.co.kr/southkorea/20260430/sk-hynix-vest-becomes-koreas-hottest-status-symbol

Stubborn Faith in Intel Pays Off Amid Doom
It seems being stubborn as a mule about your core conviction, that the U.S. needs its own semiconductor champion, Intel, for example, can be very profitable, even when 99% of people on social media have spent years insisting the company...

Curated Papers on Memory for LLM and Multimodal Agents
Awesome Agent Memory Papers A curated list of papers on memory for LLM / multimodal agents — methods, benchmarks, and surveys — covering episodic, semantic, procedural, and multimodal memory, with both parametric (internal) and retrieval-based (external) storage, learned via prompting, supervised...

Mistral Launches AI Workflows, Echoing Temporal’s Model
Mistral releases Workflows for AI (I don't know... it looks like Temporal without AI to me) https://mistral.ai/news/workflows

Abstract Token Reasoning Matches Verbal CoT, Cuts Cost
Does a LLM really need to think in English or Chinese? How about it thinks using a short sequence of reserved "abstract" tokens through reinforcement learning? They find out that it is as performant as verbalized CoT at a fraction of the...

Xiaomi Stops Copying Cars, Hires European Designers Directly
Good news: Xiaomi won’t blatantly copy European car design anymore. They’ve found a faster method: hiring the designers directly.

Enforce Strict Canonical Terms to Curb AI‑induced Debt
With AI coding agents, do you know you can accumulate years of technical debt in a matter of days. How do you prevent your codebase from becoming unmaintainable? Remember, these coding agents often rely heavily on text-search patterns to understand and...

Intel's 18A Beats TSMC N2 in Real‑World Availability
So, who is ahead in fab technology: Intel or TSMC? Have you seen any products you can buy today that were fabbed on TSMC N2? I haven’t. Have you? They say TSMC's N2 has a higher yield, but again where are...

RAG Lives On: Latency Irrelevant in Agentic AI
One more thing. Is RAG dead? No. In traditional AI chat, RAG was detrimental because of the added latency. But in agentic AI, latency does not matter nearly as much.

New Prosumer Test Affects Only 2% of Signups
It seems they're running a small test on ~2% of new prosumer signups. Existing Pro and Max subscribers aren't affected (YET, BUT WILL BE).
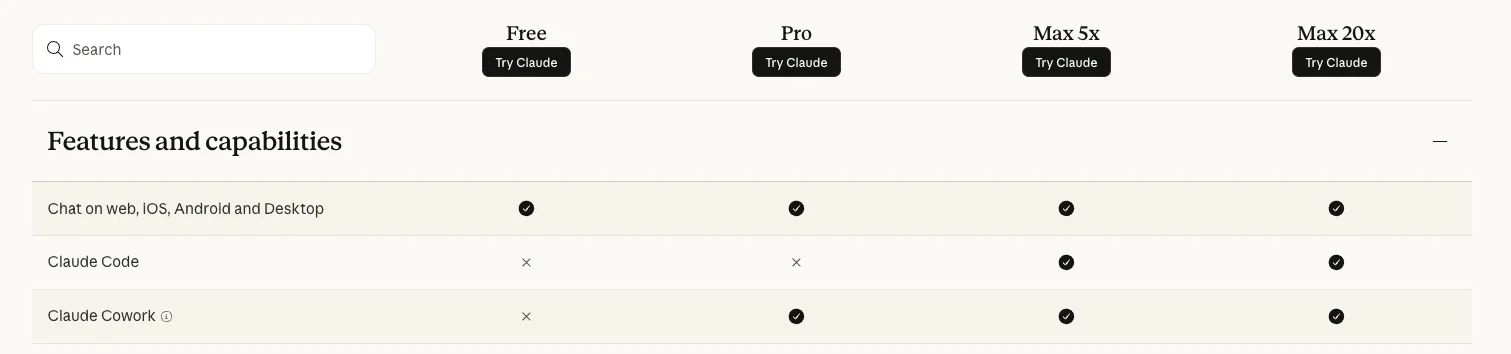
Claude Pro Loses Code Access as Token Costs Rise
Just wow. Tokens are getting more expensive. Claude Code is no longer included in Claude Pro plan. https://claude.com/pricing

Mozilla Fixes 271 Firefox Bugs Using Anthropic Mythos
Mozilla scanned the Firefox codebase with Anthropic Mythos has fixed 271 vulnerabilities identified during this initial evaluation. https://blog.mozilla.org/en/privacy-security/ai-security-zero-day-vulnerabilities/

AI Coding Hype Fades, Now Just Faster App Building
Back in December, when AI coding agents started getting good, it felt like magic. Now, the magic is gone, replaced by the same old process of building an app one step at a time, except you’re coding much less, or not...

Hybrid Model Cuts KV Cache, Slashes Token Costs
Moonshot AI prefill/decode disaggregation beyond a single cluster: cross-datacenter + heterogeneous hardware, unlocking the potential for significantly lower cost per token. This was previously blocked by KV cache transfer overhead. The key enabler is our hybrid model (Kimi Linear), which reduces...

Rust Tailscale Library Expands with C, Elixir, Python Bindings
tailscale-rs It is a work-in-progress Tailscale library written in Rust, with language bindings to C, Elixir, and Python. https://github.com/tailscale/tailscale-rs

Rust-Powered LLM Framework Delivers 3× Speed, Cross‑platform
He trained a 12M parameter LLM on my own ML framework using a Rust backend and CUDA kernels for flash attention, AdamW, and more. The framework features: - Custom CUDA kernels (Flash Attention, fused LayerNorm, fused GELU) for 3x increased throughput - Automatic...
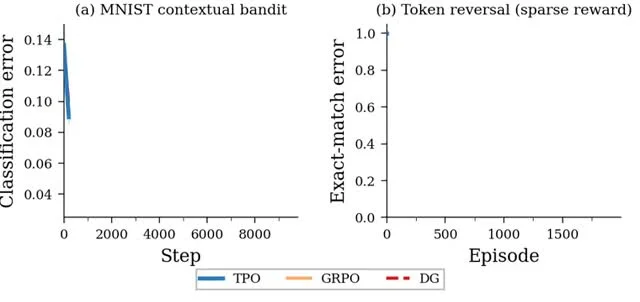
TPO Converts RL to Supervised Learning for Sparse Rewards
Target Policy Optimization (TPO) TPO turns GRPO into supervised learning: build a target distribution over sampled completions, then fit with cross-entropy. TPO brings the old “reweight, then fit” idea from the RL-as-EM line of work (e.g. REPS, MPO) into group RL....
Pair Codex Backend with Claude Code Frontend for Polished UI
My general rule for AI coding agents is simple: use Codex for the backend and Claude Code for the frontend. Why? Codex is written in Rust, and Claude Code is written in TypeScript. In practice, that means you let Codex build the...

Longing for Interpretable Models Over Opaque Modern AI
I really miss the good old days of linear and logistic regression, decision trees, random forests (kind of), SVMs, XGBoost (kind of), ARIMA, survival models, and similar methods; back when so-called AI was still something you could actually explain.

Korea Alone Prevents Luxury Sales Collapse Worldwide
Koreans are single-handedly keeping luxury brands’ sales from cratering. 🤦♂️🤦🤦♂️ Literally, no word. None. Zilch. Nada. https://www.asiae.co.kr/en/article/2026040809431791412

Looped Transformers Enable Implicit Reasoning and Broad Generalization
You have to admire the speed - generating a paper and a repo on Looped Transformer (LT) in about a week is impressive, even with AI assistance. LT is powerful because it can perform implicit reasoning over their parametric knowledge, unlocking...

Distilling Experience Into Memory Primitives Amid Data Explosion
Harness, Memory, Context Fragments, & the Bitter Lesson by Viv ...or how do we efficiently distill experiences into higher level memory primitives that capture the important parts? when there are hyper-exponential in the amount of data produced by those agents.

Host Your App at Home with Free Cloudflare Tunnel
Oh, I forgot to mention that you can even host your app at home if you have a spare PC lying around. PostGrip uses Cloudflare Tunnel, which is free, to securely expose your app to the internet.😀
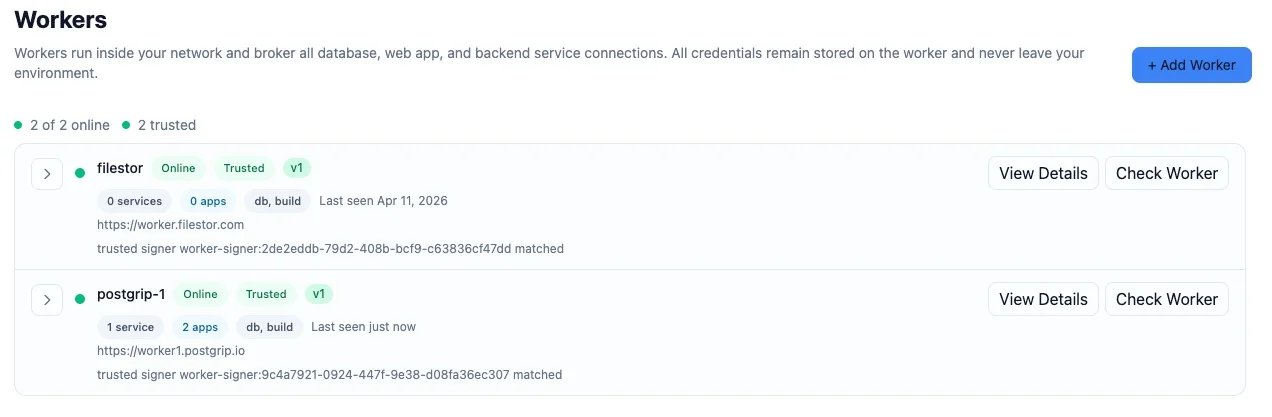
Deploy PostGrip: VPS, Docker Worker, Simple Setup
So, how does PostGrip work? It’s very simple. You go to a VPS provider like Hetzner and provision a VPS for your app(S). You download the worker Docker image from Docker Hub, run it on your VPS, and then follow the...
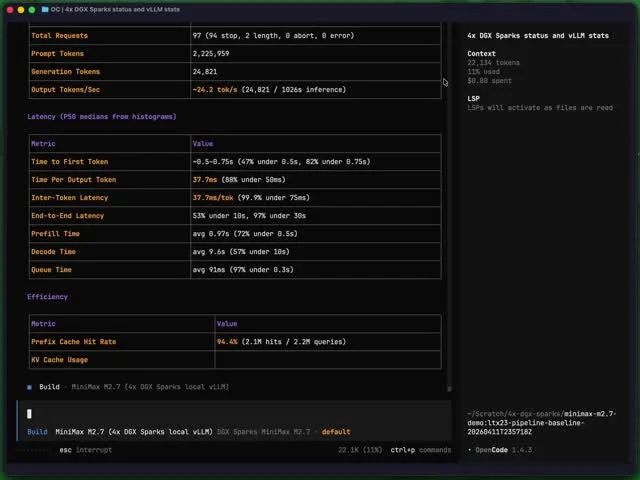
Expensive $20K Setup Delivers MiniMax M2.7
$20,000 setup, but it is nice. MiniMax M2.7 200K running on 4x DGX Sparks and OpenCode frontend by @TheAhmadOsman

Codex Currently Outperforms Claude Code
Just my personal observation. Right now, Codex is better than Claude Code. For reference, I have both subscriptions: Claude Code Max and ChatGPT Pro.

Burning Tokens, Still Manual Testing: Are You Shipping?
Question for builders burning trillions of tokens across multiple Max and Pro accounts: are you actually shipping anything? At the end of the day, it still takes your own time to manually test new features.