
Sung Kim
Semiconductor technologist/investor commenting on ASML and EUV deployment; brings practitioner insight on Europe’s chip equipment leader and related equity narratives.

Open‑source TypeScript Billing Framework Syncs with Stripe
PayKit The billing framework for TypeScript. Define plans in code, sync with Stripe, gate features, track usage. Open source and runs inside your app. Web: https://paykit.sh/ Repo: https://github.com/getpaykit/paykit

AI Tools Now so Easy, Market Is Oversaturated
It used to be that posting a new AI tool on social media required a certain amount of effort — even building and shipping a simple tool for the AI community took real work. Now that Claude Code and Codex...

I Trust Codex, Not Claude Code, in YOLO Mode
The biggest difference between Claude Code and Codex, as I see it: - Do I trust Claude Code to run in YOLO mode? No. I am not stupid. - Do I trust Codex to run in YOLO mode? Yes.

OpenAI’s Compute Edge Yields More Reliable Service
We made fun of Sam Altman for committing trillions of dollars, which he clearly did not have, to AI compute, but OpenAI’s services are stable, while Anthropic’s services are far less reliable. 🤷♂️ https://www.bloomberg.com/news/articles/2026-04-09/openai-tells-investors-it-has-computing-advantage-over-anthropic

Dune Part Three: Tiny Book Section Sparks Film
It has been a long time since I read Dune, but isn’t Dune: Part Three based on just a few paragraphs in the book itself? Am I mistaken?

Use Codex Nonstop Now Before Limit Reset Tomorrow
OpenAI will be resetting your Codex usage limit tomorrow, so let Codex run in yolo mode 24x7, right now.
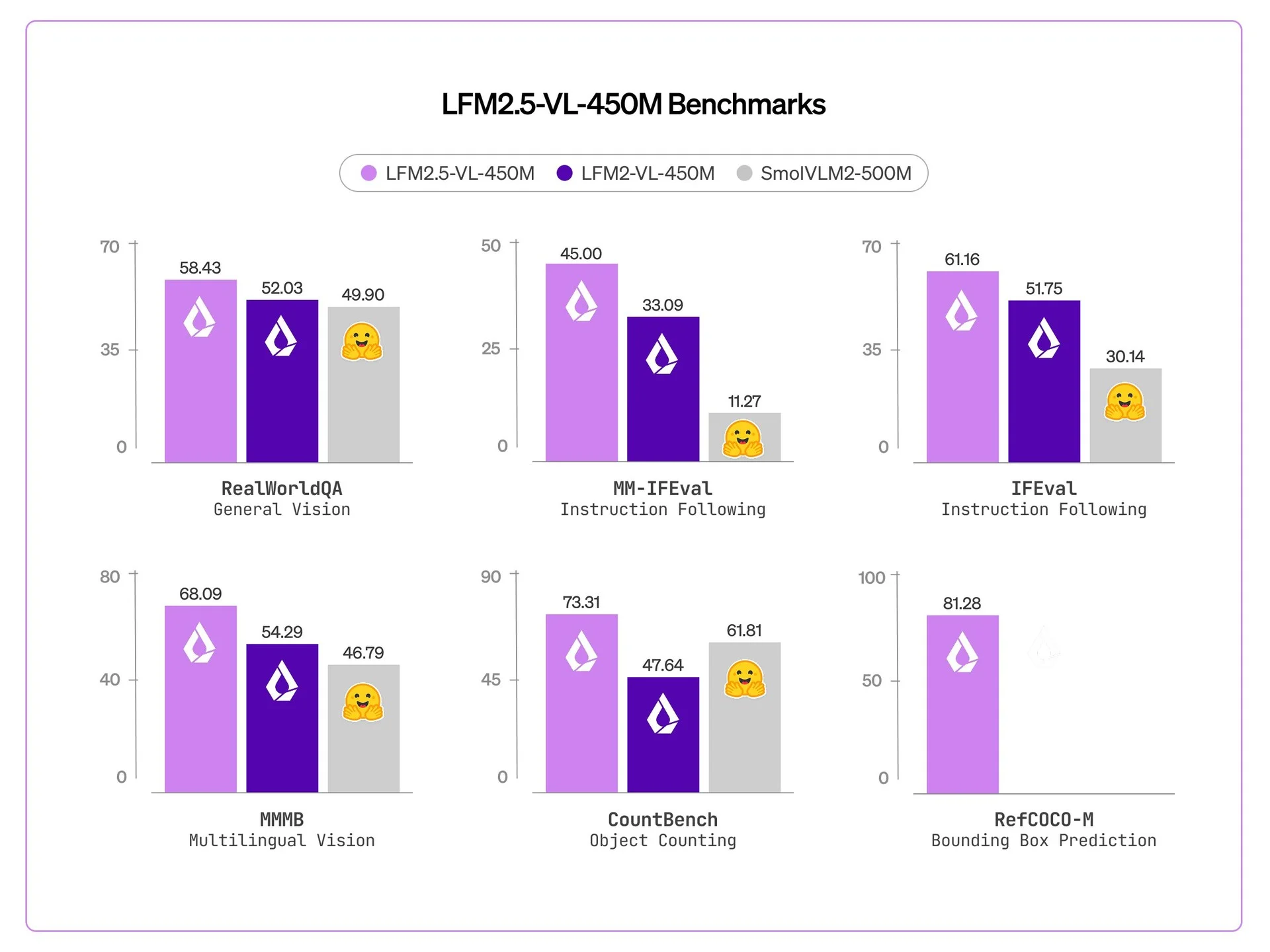
Real‑Time Vision‑Language AI Runs on Edge in 240ms
Liquid AI's LFM2.5-VL-450M, a vision-language model built for real-time reasoning on edge devices. It processes a 512×512 image and returns structured outputs in ~240ms on-device. - Blog: http://liquid.ai/blog/lfm2-5-vl-450m - Model: https://huggingface.co/LiquidAI/LFM2.5-VL-450M - Demo: https://playground.liquid.ai/login?callbackUrl=%2Fchat%3Fmodel%3Dlfm2.5-vl-450m
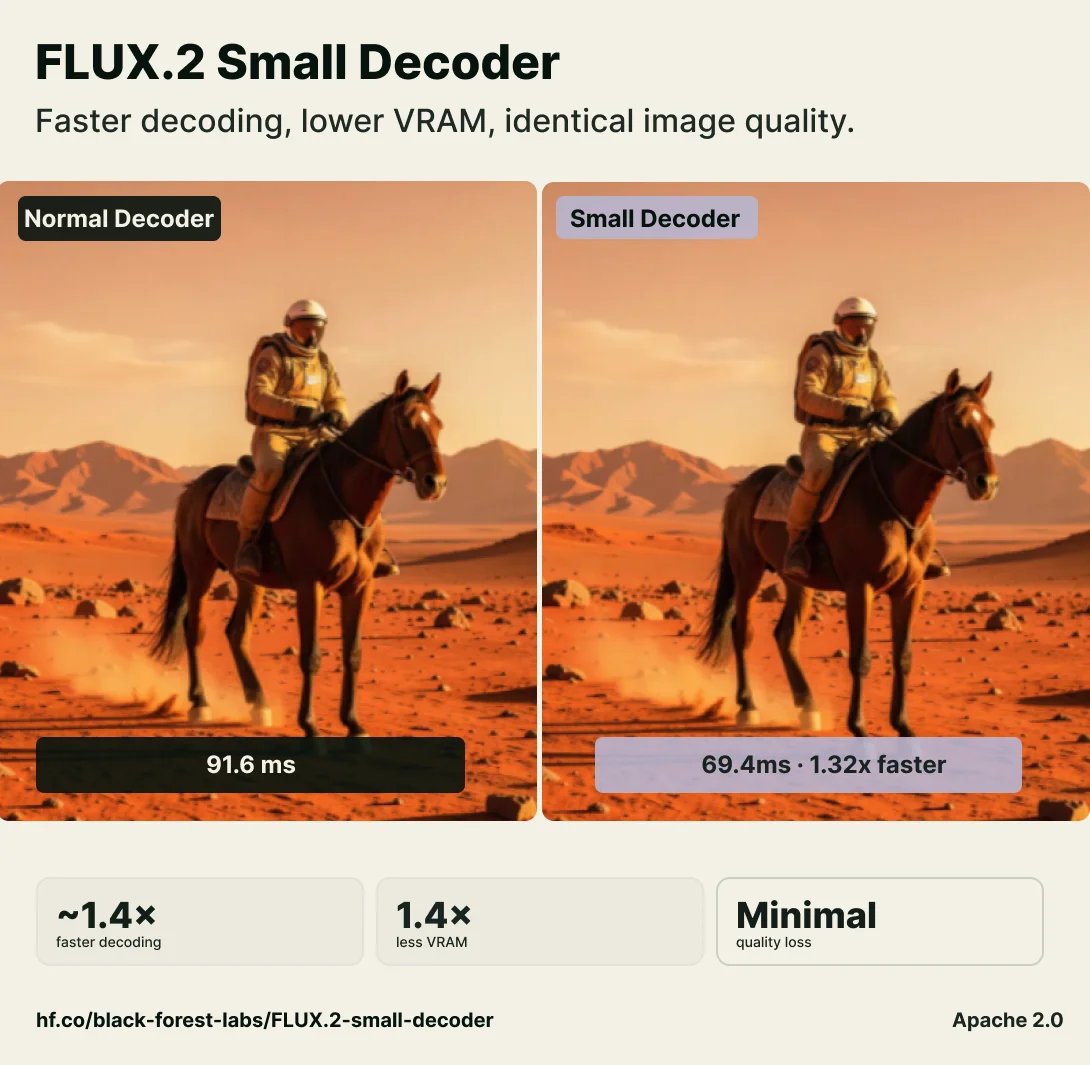
FLUX.2 Small Decoder: 1.4× Faster, Lower VRAM
Black Forest Labs' FLUX.2 Small Decoder: a faster, drop-in replacement for our standard decoder. → ~1.4x faster → Lower peak VRAM - decode larger images without running out of memory → Minimal quality loss → Works with FLUX.2 out of the box Model: https://huggingface.co/black-forest-labs/FLUX.2-small-decoder

Mid‑training Boosts Llama‑3 Reasoning 3.2×
Meta's Thinking Mid-training: RL of Interleaved Reasoning They address the gap between pretraining (no explicit reasoning) and post-training (reasoning-heavy) with an intermediate SFT+RL mid-training phase to teach models how to think. Result: 3.2x improvement on reasoning benchmarks compared to direct RL...

Pro Upgrade Turns Codex From Slow to Lightning‑fast
One thing I liked about Codex was that it took its time solving problems instead of instantly spitting out an answer like Claude Code. It gave me time to do other things while it quietly worked in the background. Well... I...
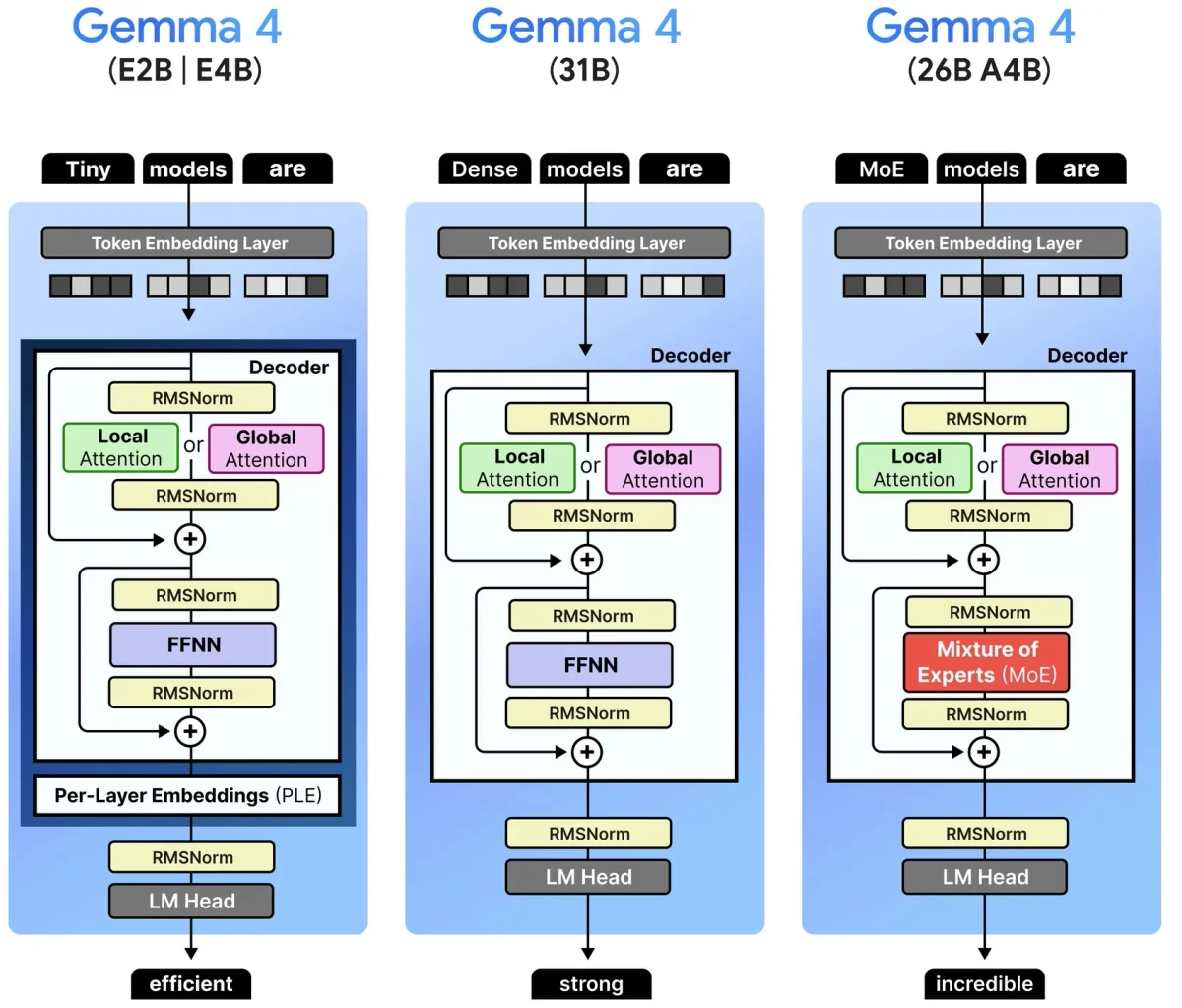
Inside Gemma 4: Visual Deep Dive of Architecture
A Visual Guide to Gemma 4 by Maarten Grootendorst An in-depth, architectural deep dive of the Gemma 4 family of models. From Per-Layer Embeddings to the vision and audio encoders. https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-gemma-4

RL Environment Shapes What LLM Agents Can Learn
A Taxonomy of RL Environments for LLM Agents by Han Lee "The reinforcement learning (RL) environment — what the model actually practices on, how its work gets judged, what tools it can use — barely enters the conversation. That’s the part...
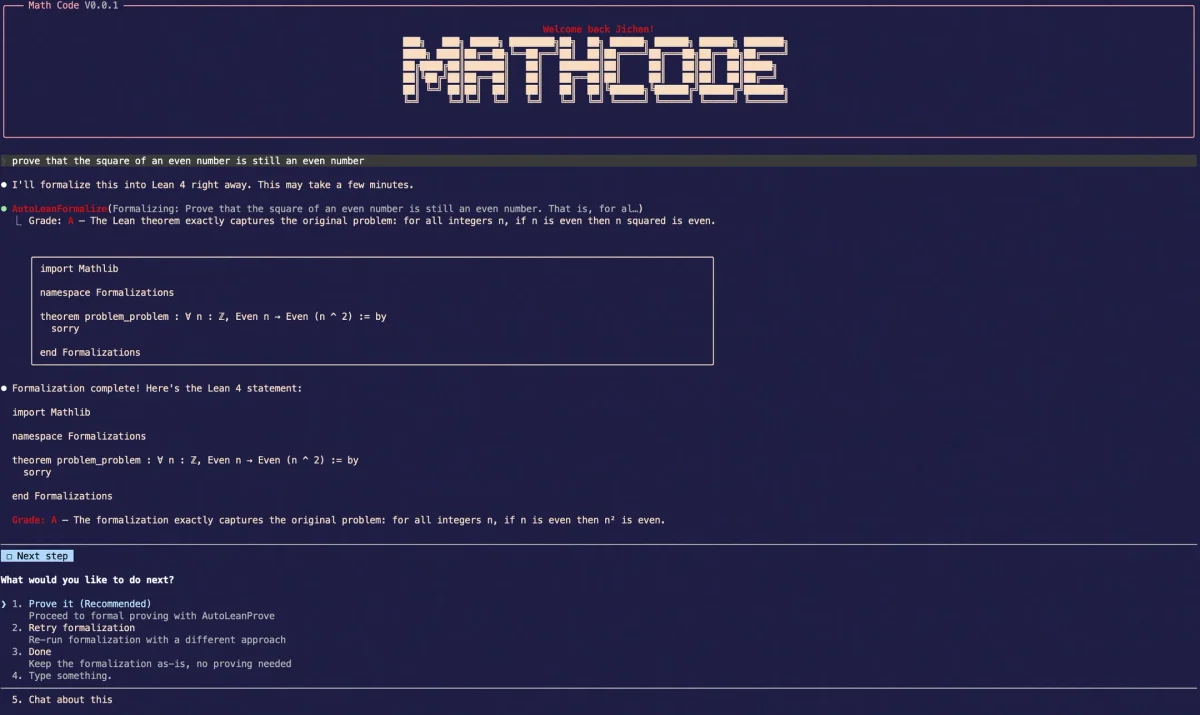
AI Turns Plain Math Into Lean 4 Proofs Instantly
MathCode MathCode is a terminal AI coding assistant with a built-in math formalization engine. Give it a math problem in plain language and it will automatically convert it into a Lean 4 theorem and attempt a formal proof. https://github.com/math-ai-org/mathcode

Korean Cuisine’s Surprising Sweetness Highlighted by “Sugar Boy”
Hot take: Korean food in Korea is really sweet. Exhibit: One of the more famous Korean chef is called “Sugar Boy.” https://www.dongascience.com/en/news/11450

AI Auto-Optimizes CUDA, Outperforms PyTorch and Torch.compile
People are using AI to break CUDA’s moat. Given any pytorch model, it profiles it, ranks bottlenecks by amdahl's law, writes triton or CUDA C++ replacements, and runs 300+ experiments overnight with no human in the loop. - 5.29x over pytorch eager...

Zero‑Trust BYO‑VPS Delivers Commercial Features
So, I built more or less complete platform to test whether I could match the core features of commercial vendors with a zero-trust, BYO-VPS platform. Zero-trust: The control plane stores no credentials, only metadata. A worker running next to your server...

Zero‑Trust BYO VPS Platform Matches Commercial Features
I've built: A zero-trust BYO VPS platform. It has feature parity with commercial alternatives, but it still needs a lot of polish. 😀

Codex Excels Backend, Struggles UI; Sandbox Testing Praised
I’ve been using Codex a lot lately, especially for backend work. It is still sucks at UI and UX, though. Why am I seeing both view mode and edit mode shown on screen at the same time? Huh? Anyway, I’ve also...

Anthropic Advises Reducing Claude Code Context to 200k
Anthropic: You know how we made Opus 4.6 with a 1M context window the default model in Claude Code? That was a mistake. It made you use far more tokens than before. Our bad. Add this to your config: CLAUDE_CODE_AUTO_COMPACT_WINDOW=200000

Decentralized Private LLMs Empower User Sovereignty
My self-sovereign / local / private / secure LLM setup, April 2026 by Vitalik Buterin https://vitalik.eth.limo/general/2026/04/02/secure_llms.html

CuLA: Hand‑crafted CUDA Linear Attention Beats FLA
Alibaba Ant's cuLA (CUDA Linear Attention) The hand-written kernels using CuTe DSL & CUTLASS C++ to extract maximum performance on NVIDIA GPUs. A drop-in replacement for FLA designed to push hardware to its absolute limits. https://github.com/InclusionAI/cuLA

VOID Erases Objects and Their Physical Interactions in Video
netflix/void-model (open-weight) VOID removes objects from videos along with all interactions they induce on the scene — not just secondary effects like shadows and reflections, but physical interactions like objects falling when a person is removed. https://void-model.github.io/

Apple Bans App, Developer Pivots to iMessage
Well done, Anything - making lemonade from lemons. Apple removed Anything from the App Store, so they shifted app building to iMessage.

Ever Given's Suez Blockade Halted Global Trade for a Week
A video showing the 2021 incident where Ever Given blocked the Suez Canal, one of the biggest shipping disruptions in recent years. The vessel ran aground and blocked the canal for nearly a week, holding up hundreds of ships and...
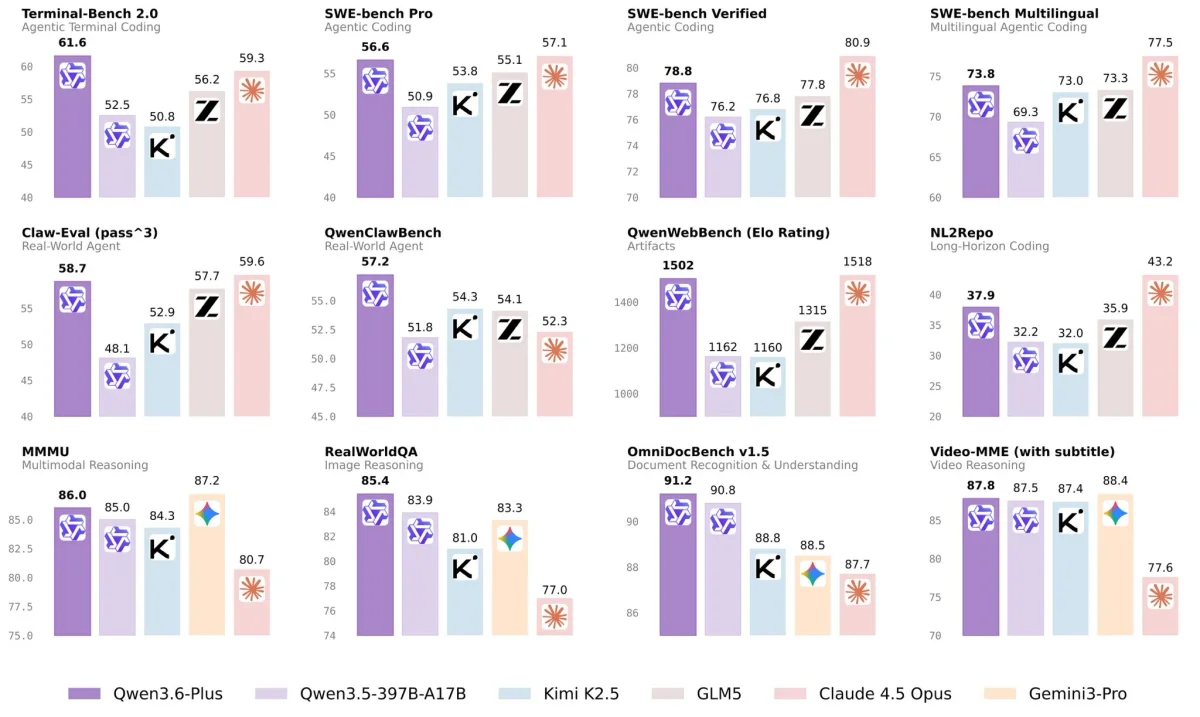
Qwen3.6-Plus Boosts Agents with 1M Context
Alibaba's Qwen3.6-Plus: Towards Real World Agents (closed-weight) Qwen3.6-Plus is the hosted model available via Alibaba Cloud Model Studio, featuring: - a 1M context window by default - significantly improved agentic coding capability - better multimodal perception and reasoning ability https://qwen.ai/blog?id=qwen3.6
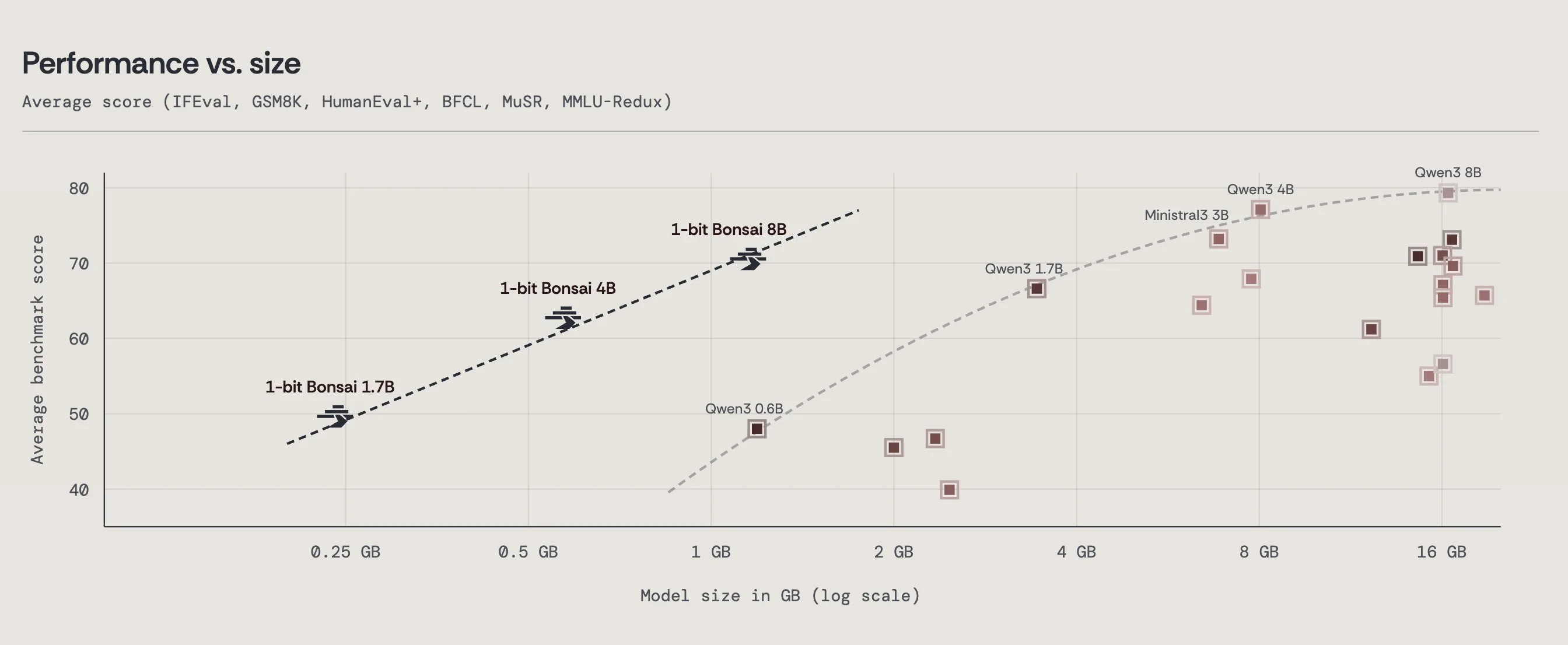
PrismML Unveils 1‑Bit 8B LLM Under 1.2 GB VRAM
PrismML releases 1-bit LLM (open-weight), or a 8B LLM that fits in 1.15GM of VRAM Website: https://prismml.com Blog: https://prismml.com/news/bonsai-8b HuggingFace: https://huggingface.co/collections/prism-ml/bonsai
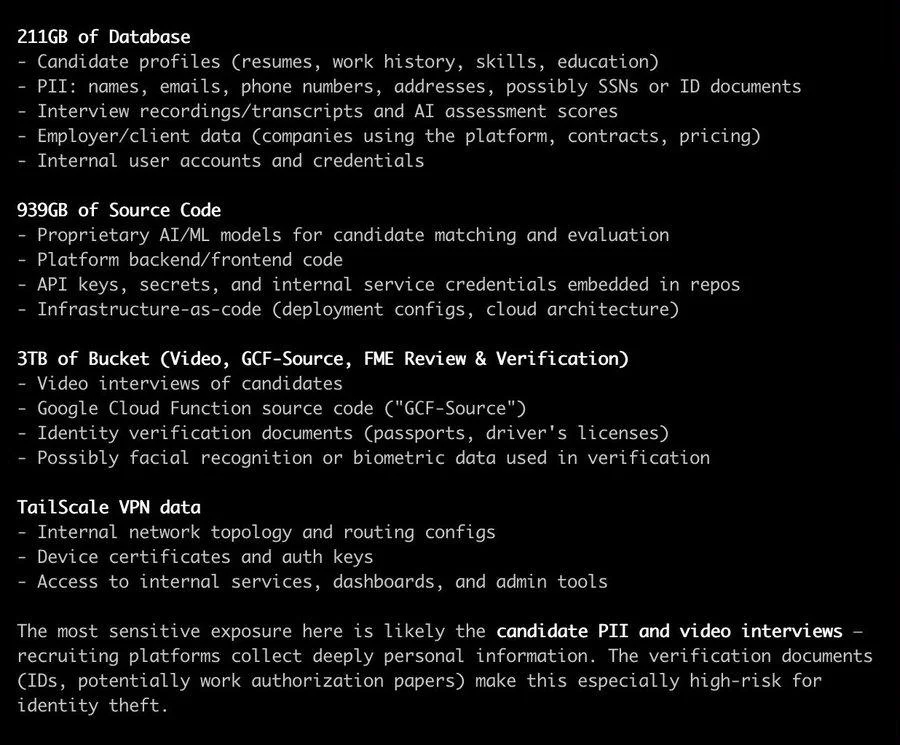
Mercor AI Hacked Amid Tailscale VPN Security Concerns
Is this because Tailscale VPN got hacked? or something else? Anyway, Mercor AI got hacked.

Anthropic's New Claude Code Metrics Drain Limits Faster
OK… Anthropic changed how Claude Code’s model usage is calculated. I’m running into my usage limit much faster than before.

Looped Code Review: Keep Fixing Until One Issue Remains
When doing a code review with Codex, instead of just asking it to review the code, say this instead: “Review the code and keep fixing the findings in a loop until only one finding remains.” Otherwise, you will just iterate, iterate, and...

AI Agents Streamline Projects, Exposing Software Feature Bloat
I’m having a lot of fun building personal side projects with AI coding agents like Claude Code and Codex. When I want to improve my workflow, I usually find an open-source project that solves the problem, but it is often too...

Claude Code Shows Rate Limit Error Despite Usage Within Limits
I'm getting "API Error: Rate limit reached" in Claude Code when I'm within my usage limits for both current session and weekly limits. @boris_cherny

OS Updates Silently Drain Batteries, Prompting Upgrades
It took me years to understand this, maybe I’m slow, but I always wondered why Apple and Google keep providing free software updates to older smartphones for so many years. It’s a way to degrade the battery life of an otherwise...

New PostgreSQL Client Built, Requires Rigorous Testing
Ok. I’ve developed a PostgreSQL database client similar to Neon’s. I need to test it thoroughly before using it in production.

AI Agents Simplify Features, but Stripe Auth Remains Tedious
Using AI coding agents to implement new features is exciting. You know what’s not? Integrating with Stripe or setting up auth using Better Auth - it’s just a continuous slog of trial and error. 😭

AI Code Generators Turn Papers Into TurboQuant Implementations
Why are there so many implementations of TurboQuant in such a short time? Because people are simply feeding this document into Claude Code or Codex, which then generate the implementation code for them. These tools have effectively become a new “paper-to-code”...

Rust Brings Native Threading to GPU Programming
Rust threads on the GPU GPU code can now use Rust's threads. They share the implementation approach and what this unlocks for GPU programming. https://www.vectorware.com/blog/threads-on-gpu/
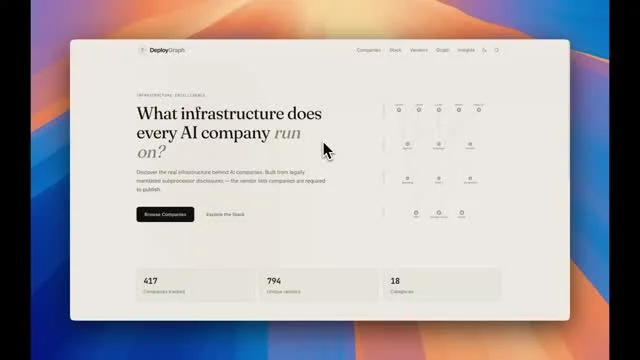
SOC 2: Theater, Yet Reveals AI Companies’ Third‑Party Stack
SOC 2 is largely useless theater, much like SOX compliance, but it’s quite useful for identifying the third-party providers a website relies on. DeployGraph: What infrastructure does every AI company run on? https://www.deploygraph.com/

Continued Pretraining and Simple RL Boost Coding Performance
How Cursor's Composer 2 was trained. - They show how continued pretraining results in consistent improvements in downstream coding performance. - They find that simple RL approaches often work best, and improve performance broadly. - They describe their internal benchmark CursorBench which represents...
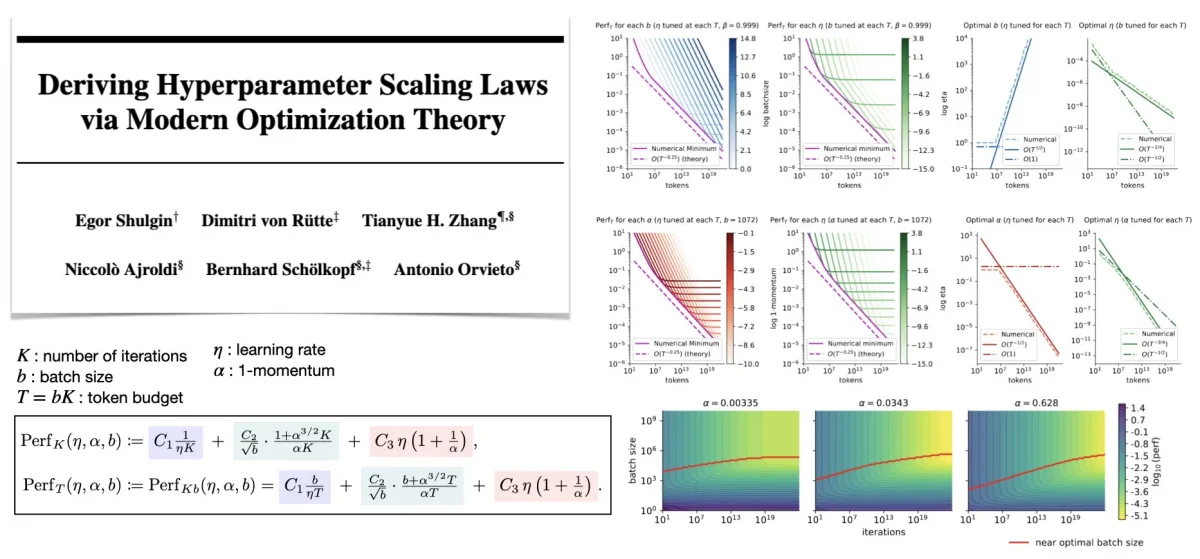
Optimization Theory Predicts LLM Hyperparameter Scaling Laws
The paper claims that optimization theory for adaptive methods actually predicts most of what we know about hyperparameter scaling in LLM pretraining. Paper: Deriving Hyperparameter Scaling Laws via Modern Optimization Theory ( https://arxiv.org/abs/2603.15958 )
Add Temporal Developer Skill to Claude Code
For those of you, developing with Temporal Temporal Developer Skill - install in Claude Code using https://github.com/temporalio/skill-temporal-developer

Boost macOS AI Coding with Cmux
Yeah. If you’re coding with either Claude Code or Codex in a macOS environment, use cmux. https://cmux.com/

Sigmoid‑Weighted Delight Improves Policy Gradient Scaling
Delightful Policy Gradient by Ian Osband DG gates each policy-gradient term by a sigmoid of delight, improving gradient direction with gains that grow as problems get harder.

Distractions Like Social Media Can Boost Productivity
I didn’t realize I had something in common with Terence Tao. You actually need a distraction in your life, like posting on social media, to stay productive, which I do a LOT... 🤣🤣🤣
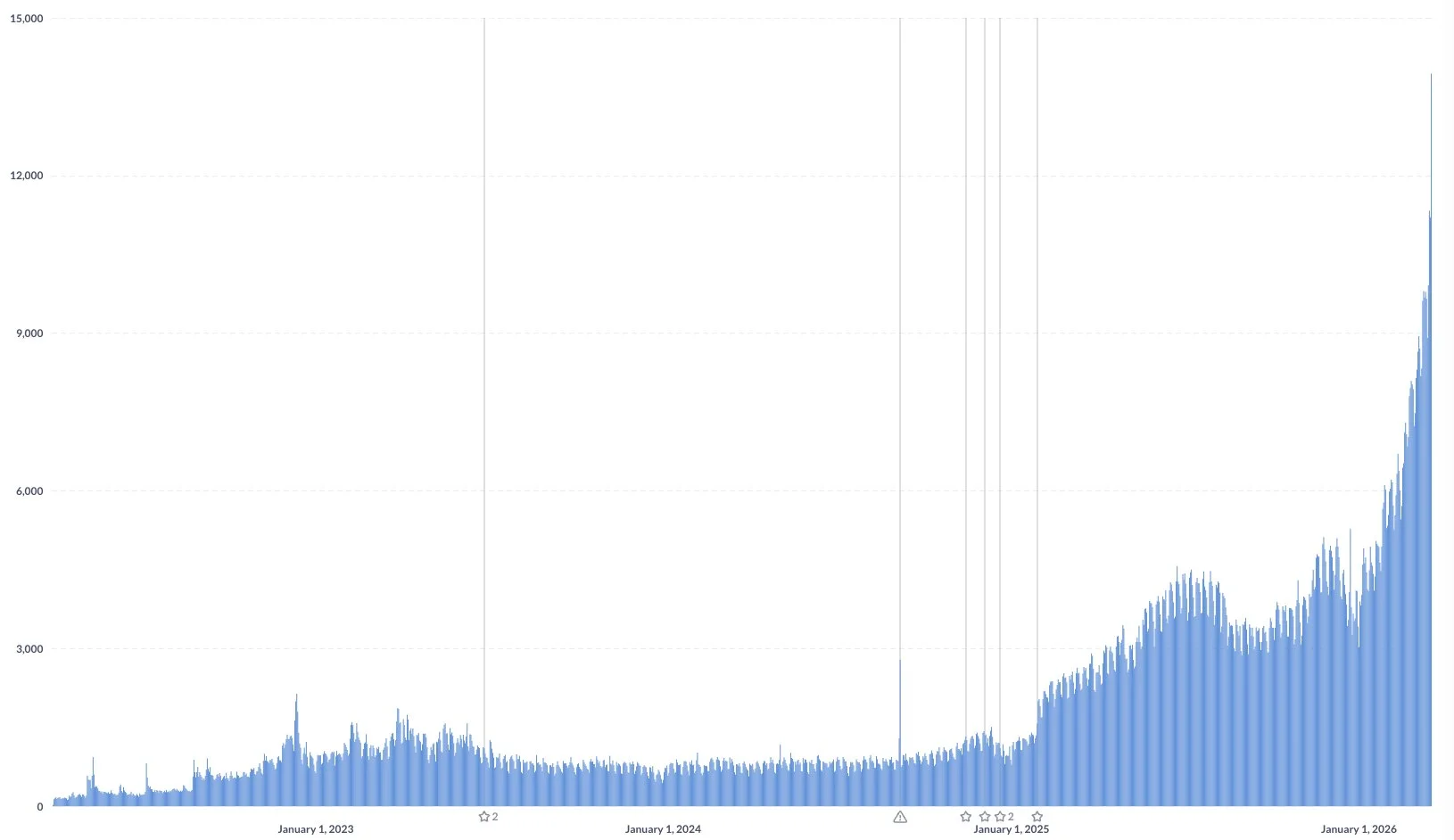
Railway's Weekly User Growth Doubles to 40%
This is interesting. Railway (all-in-one intelligent cloud provider) is reporting that they are experiencing 40% week to week user growth. It used be 20% yesterday.

AI Code Reviews Echo Endless Human Debugging Loops
I really do love these interactions. 1. Claude writes the code. 2. Codex reviews the code and provides feedback. 3. Claude acknowledges the bug and fixes it. 4. Codex says it is not fixed. 5. Claude acknowledges it is still not fixed correctly and fixes...

Building GPT‑OSS‑20B Inference From Scratch in PyTorch
GPT-OSS Inference from Scratch In this post, they implement GPT-OSS-20B inference from scratch in PyTorch. https://blog.yellowday.day/posts/gpt_oss_from_scratch/