

Use JAX + Keras 3 for Scalable Deep Learning
For anyone getting started with deep learning in 2025 and looking to do large scale training: use JAX + Keras 3. Unless you like suffering.

Babies Invent Crawling, Proving Invention Is Human Core
Crawling isn't innate (unlike walking). Every baby must *invent* crawling, from scratch, using extremely little data, and no reference to imitate. Which is why different babies end up with different ways of crawling. Sometimes people tell me, "you say AI isn't...

Boredom, Not IQ, Limits Mastery—Persist to Reach Flow
The bottleneck for deep skill isn't usually intelligence, but boredom tolerance. Learning has an activation energy: below a certain skill threshold, practice is tedious, but above it, it becomes a self-sustaining flow state. The entire battle is persisting until that transition.

Gemini Overtakes ChatGPT as Default AI Reference
People (outside of tech) used to say "ChatGPT" to mean "an LLM chatbot", because most of the time, that's what it was. But recently I've been hearing a lot of "Gemini told me..." The writing is on the wall

Clear Problem Specs Unlock Solutions, Vague Ones Stall
If a problem seems intractable, it's almost always because your specification of it is vague or incomplete. The solution doesn't appear when you "think harder". It appears when you describe the problem in a sufficiently precise and explicit fashion -- until...

ARC Prize Seeks Backend Engineer for AGI Evaluation
The ARC Prize foundation is hiring a backend engineer. If you're a builder with a strong track record and you're passionate about our mission of building the best AGI evals possible, please apply ⬇️

Modular News Recommendation Framework Scales with Keras 3 and JAX
NewsRex! 🦖 A modular framework for SOTA news recommendation, built on Keras 3 + JAX backend for extreme scalability and performance with XLA acceleration. Extensible and easy to use. GitHub link in next tweet. https://t.co/zSVkOgIqQC
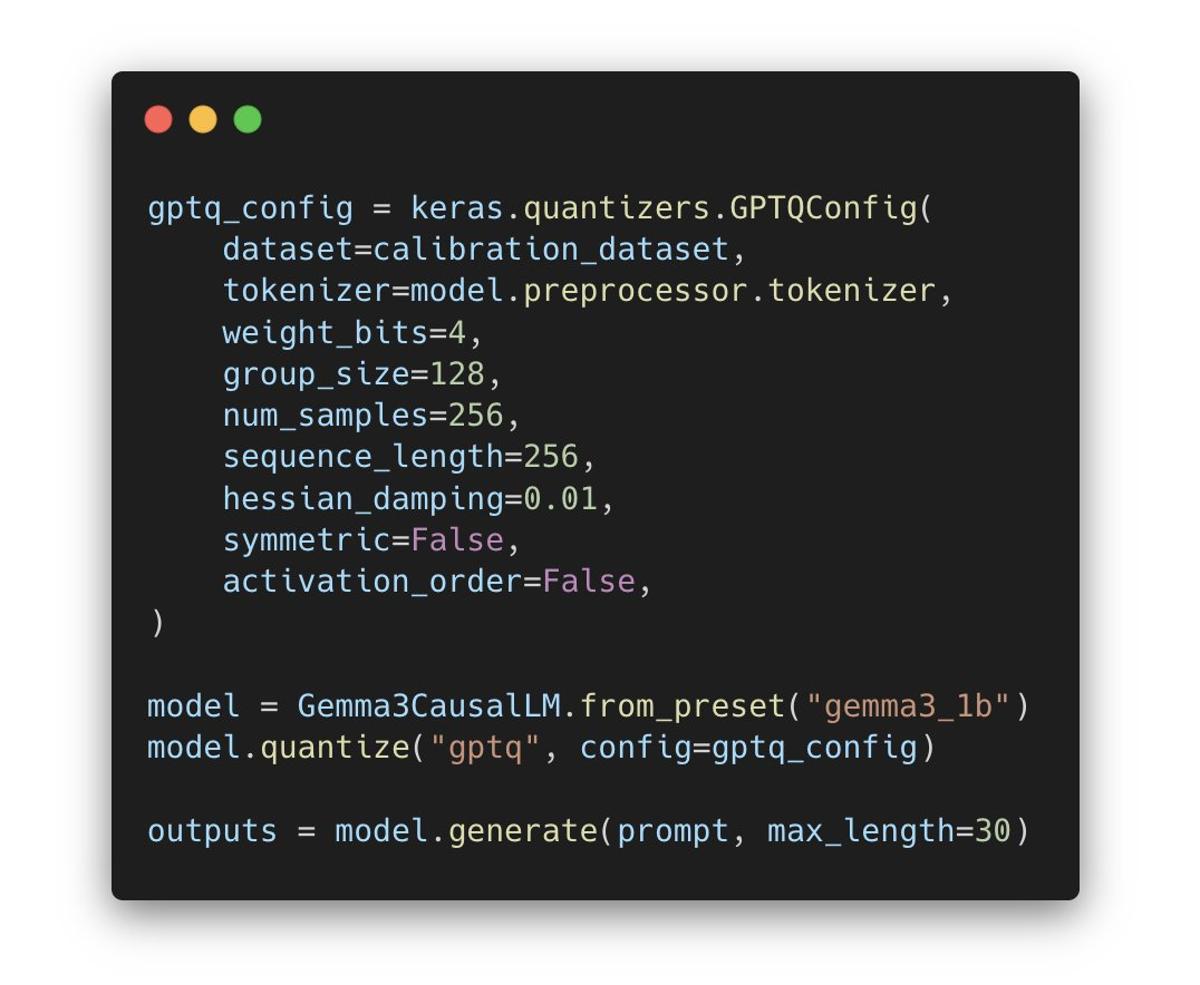
GPTQ Brings Int4 Layerwise Quantization to Keras 3
GPTQ is a post-training, weights-only quantization method that compresses a model to int4 layer by layer. For each layer, it uses a second-order method to update weights while minimizing the error on a calibration dataset. It comes built-in in Keras 3...
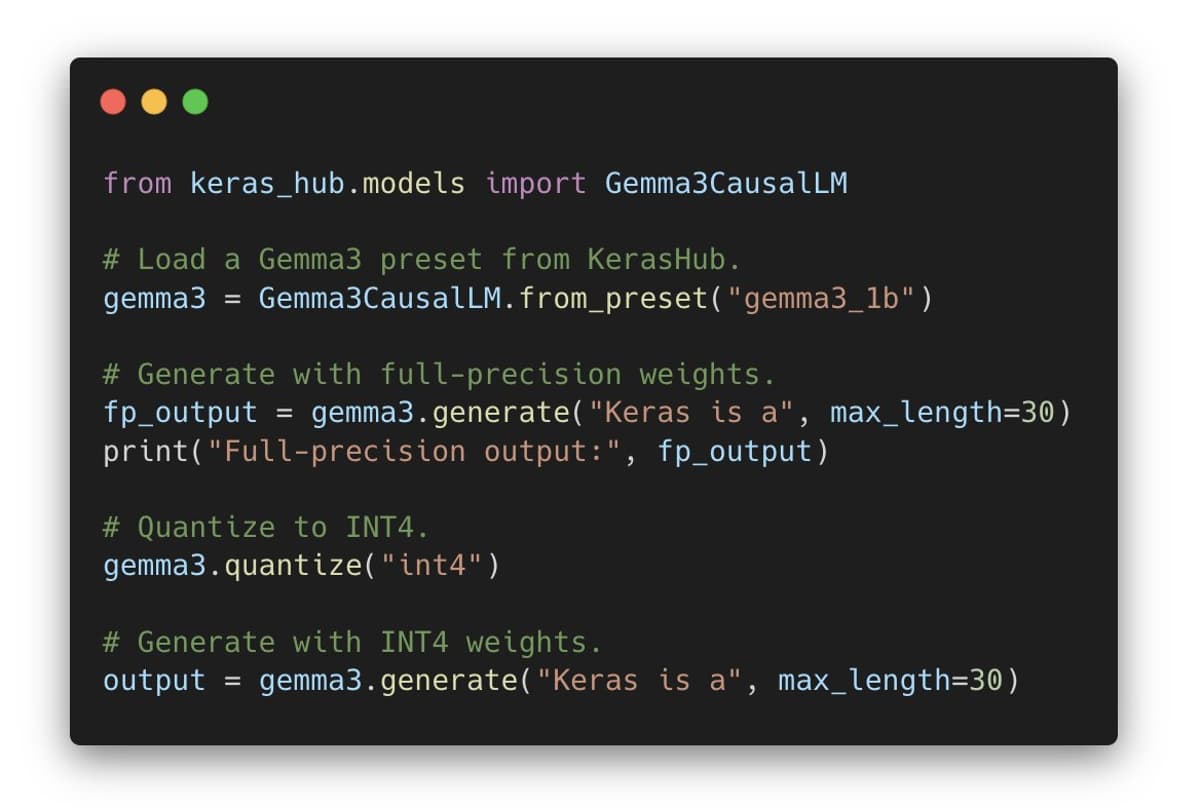
Accelerate Keras Models with Low‑precision Quantization
Run your models faster with quantized low precision in Keras! You can quantize any model (one of your own models or a KerasHub pretrained model) via `model.quantize(mode)`. Supports int4, int8, float8, GPTQ. Works with JAX, TF and torch. Links to guides in next...