
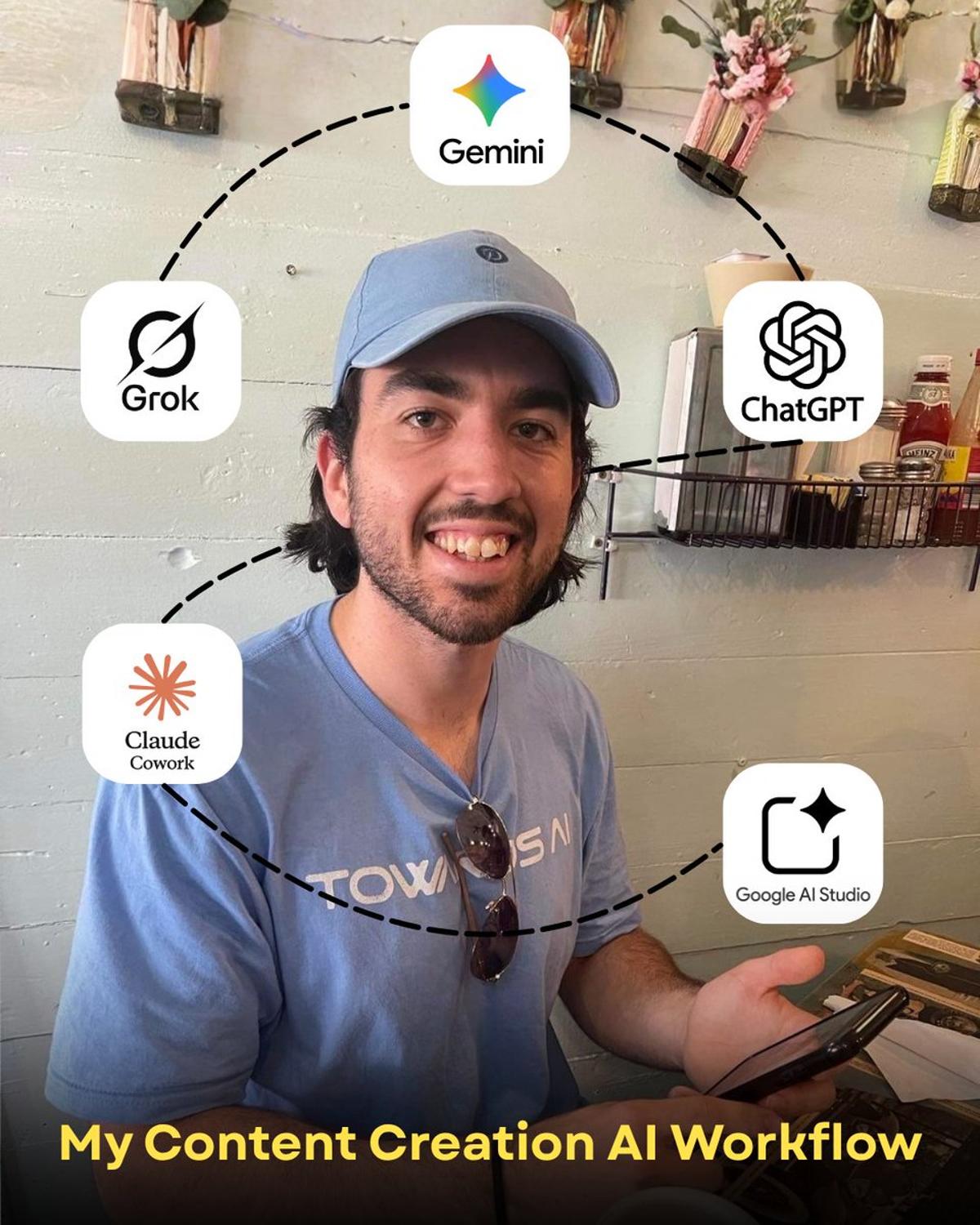
Combine Five AI Tools to Cut Research Time
I teach AI for a living. Here's my AI stack for researching and writing content. If you use AI for research or content creation, this workflow can save you 4-6 hours. I don't use one tool. I use five. Each one handles a different step. Here's my workflow: Step 1 - I start research with Grok. It's the best tool for finding what people are saying on Twitter. Tweets, threads, engineer reactions - things you won't find through a regular search. Step 2 - I run deep research on Google Gemini. It pulls from more sources than anything else I've tried. This gives me the full picture of the topic. Step 3 - I run ChatGPT deep search as a second pass. It catches things Gemini misses. Different tools surface different sources. Now I have three research documents, each with different strengths. Step 4 - Everything goes to Claude Cowork. I built a skill file that tells Claude how to cross-reference all three documents, find gaps, and draft the first version based on my writing style and rules. I iterate 2-3 rounds with it, then edit fully myself. Step 5 - For visuals, I use AI Studio. Thumbnails, infographics - it's better than anything else I've tested for this. No single AI tool does everything well. Grok can't do deep research well. Gemini can't find tweets. ChatGPT catches what both miss. Claude puts it all together. I used to do all of this manually. This workflow saves me hours every week. Let me know in the comments - what does your content creation workflow look like?

Free Webinar: Core Skills Every AI Engineer Needs
I recorded a 1-hour webinar on AI Engineering Foundations, covering what AI engineers actually need to know today: how LLMs work, their limitations, when to use prompting, RAG, workflows, or agents, and why evaluations and security matter before production. It's free. Check...

Align Intent and Skill Levels for Effective AI Training
If you're investing in AI training for your team, read this before you book anything. We've trained developers at dozens of companies to become AI engineers. And the biggest problem is never the content. It's the setup. Here are the two biggest...

Beyond AI Hype: Deep Dives Into Anthropic Controversies
AI news is fast. Understanding it properly is not. So I made a new playlist for that. I just published 3 deeper, story-driven videos where I go beyond the weekly hype cycle and unpack what actually happened: 1. Who's Really Stealing From Whom? ...
ChatGPT’s Politeness Comes From Human‑ranked Preference Tuning
ChatGPT doesn't sound helpful by accident. Someone taught it to sound that way. After the model learns to follow instructions, labs show it thousands of answer pairs. Humans pick which response feels clearer, friendlier, or more useful. The model learns the preferred style. This...

Claude Code’s “Undercover Mode” Hides AI Identity
Anthropic has a feature in Claude Code literally called "undercover mode." No off switch. It quietly tells Claude to never reveal it's an AI. Kind of a wild choice from the company whose whole brand is transparency 👀 https://t.co/3qR3JbyZ8q

Claude Code's Three‑Layer Memory Keeps Sessions Coherent
Claude Code doesn't dump everything into your context window. It uses a three-layer memory system that keeps it coherent across sessions lasting days. Layer 1 is a lightweight index, always in context. Layer 2 is topic files, loaded only when needed....
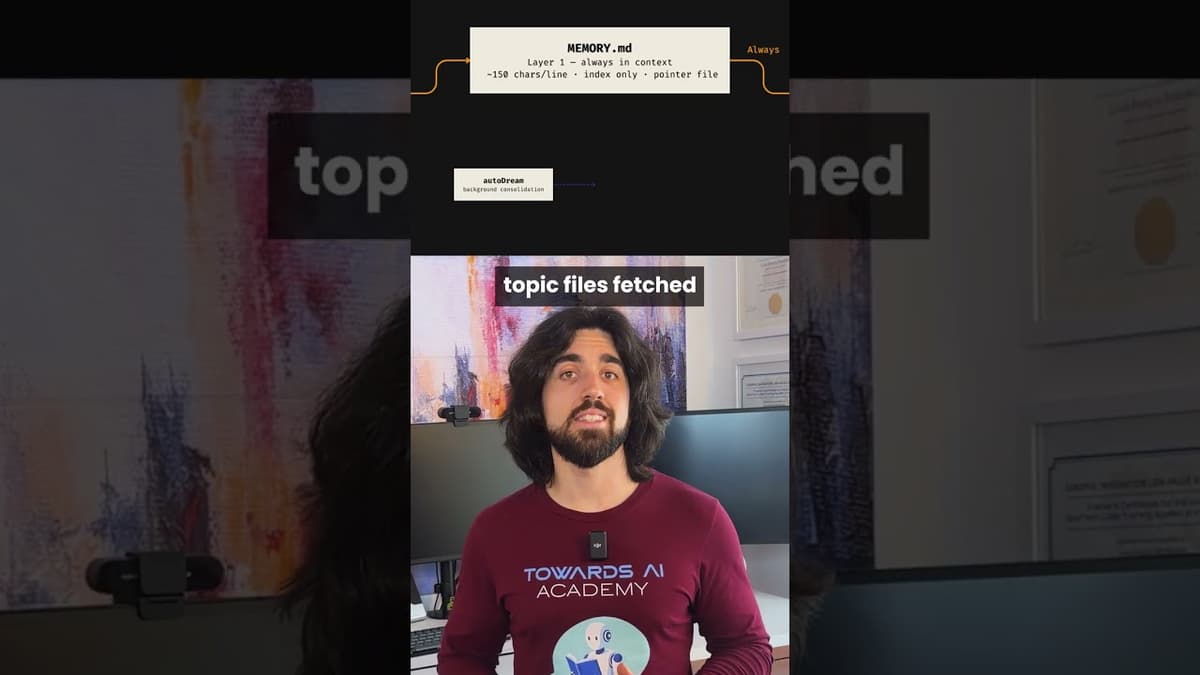
Claude Code Doesn't Dump Everything Into Your Context Window. It Uses a Three-Layer Memory System Th
The video explains how Claude Code, Anthropic’s code‑assistant platform, avoids filling its massive token window by employing a three‑layer memory architecture. Layer 1 is a minimal index—about 150 characters per line across fewer than 200 lines—that merely points to where the actual...

Open‑source AI Often Built on Closed‑model Distillation
Some "open source" AI models have a secret. They were trained using outputs from closed models like ChatGPT and Claude. The weights are free. The code is public. Anyone can run them. But the intelligence inside came from somewhere else. This technique is called...

Life Shouldn't Revolve Around API Peaks and Token Limits
Are you also planning your life around agents running, api peak hours and token limits?

Friends Use AI for Fun, Not Professional Tasks
i don't get how most of my friends have never opened claude or chatgpt for their professional work, but did for random questions

Verification Becomes the New Bottleneck for Self‑improving AI
AI agents can now generate endless ways to improve themselves. New prompts. New code. New plans. New experiments. New tool calls. That is not the bottleneck anymore. The bottleneck is the verifier. How do you know the new version is actually better?

Show Up Daily: Exercise Fuels Reset, Ideas, Progress
People talk a lot about morning routines, time blocking, structured days. That's never been me. What I do have is sport, every single day. Bouldering, gym, running, cycling, tennis in summer. Not as a strategy. I just genuinely need it. Climbing fully turns...

Repeated LLM Failures Frustrate Users Seeking Simple Tasks
This is probably the most frustrating (repeated) interaction I've had with LLMs ever since ChatGPT. I truly hope Anthropic still scan for "ffs, F**KING" to work on these as a priority. I've never thought I'd say that, but, in this case, I...

ChatGPT Generates Real‑World Running Plan That Works
I asked ChatGPT to build me a running training plan instead of hiring a trainer. I wanted to test one thing. If I give ChatGPT all my data (Strava history, PRs, volume...), does the plan it builds actually work? Will I...

Vibecoding with Claude 😅
The video frames Claude, Anthropic’s conversational AI, as a “coding intern” that can churn out snippets, tests, and pull‑requests at speed. The presenter warns that while the tool accelerates routine tasks, developers must treat its output as a draft, not...
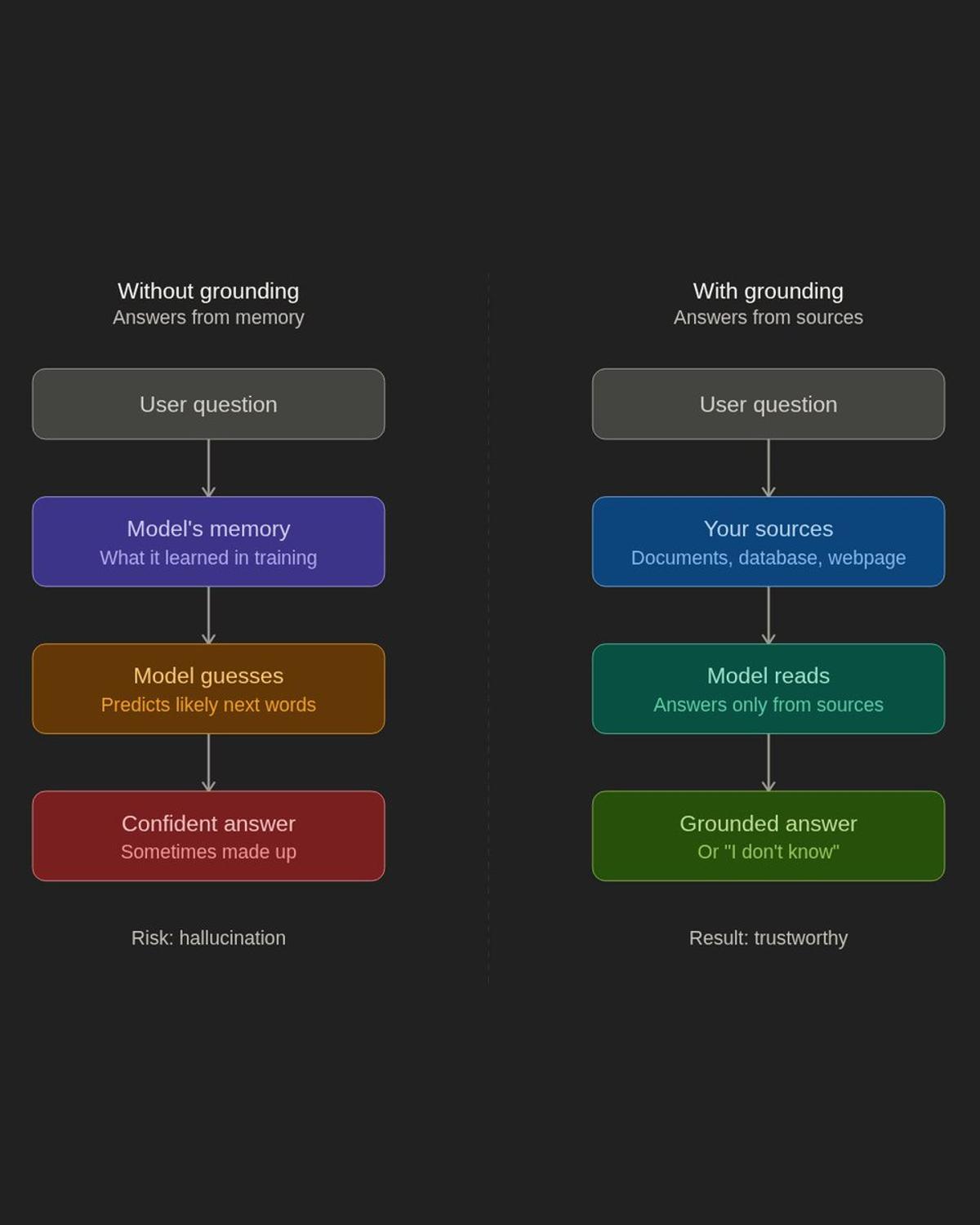
Grounding Makes AI Answer Honestly, Not Guess
Ever uploaded a document to ChatGPT and asked a question about it? The answer you got came from grounding. When you ask a model a question without any file, it answers from memory. Whatever it learned during training. Sometimes right, sometimes made up. Grounding...

Recursive Self‑improvement Already Exists, Not Just Hype.
Recursive self-improvement is not AGI hype. And it’s not just prompt tuning either. Karpathy’s autoresearch ran 700 experiments on a single GPU, improved its own training code, and kept what worked. This loop is already here. I break down how it works,...

From Community to Sponsor: Small Steps Yield Big Milestones
This one felt a bit surreal. For the first time, @towards_AI was sponsoring an event. And seeing our logo there… was honestly wild. A few years ago, this was just content, courses, and a community we were building step by step. Now we are...

Prioritize Ethical, Efficient AI over Mere Feasibility
We’re entering a phase where “can we build it?” matters less than “should we build it this way?” Energy, cost, and latency are becoming very important societal decisions. LLMs are powerful, but they’re not always the right abstraction. Good (AI) engineering is knowing...

Beyond 30‑Second AI Hype: Deep Story Videos
Most AI stories are told in 30 seconds. That is exactly why so many people misunderstand them. Lately, I have been seeing the same pattern again and again: viral clips, narrow takes, confident opinions... and almost none of the actual context. Then people ask...
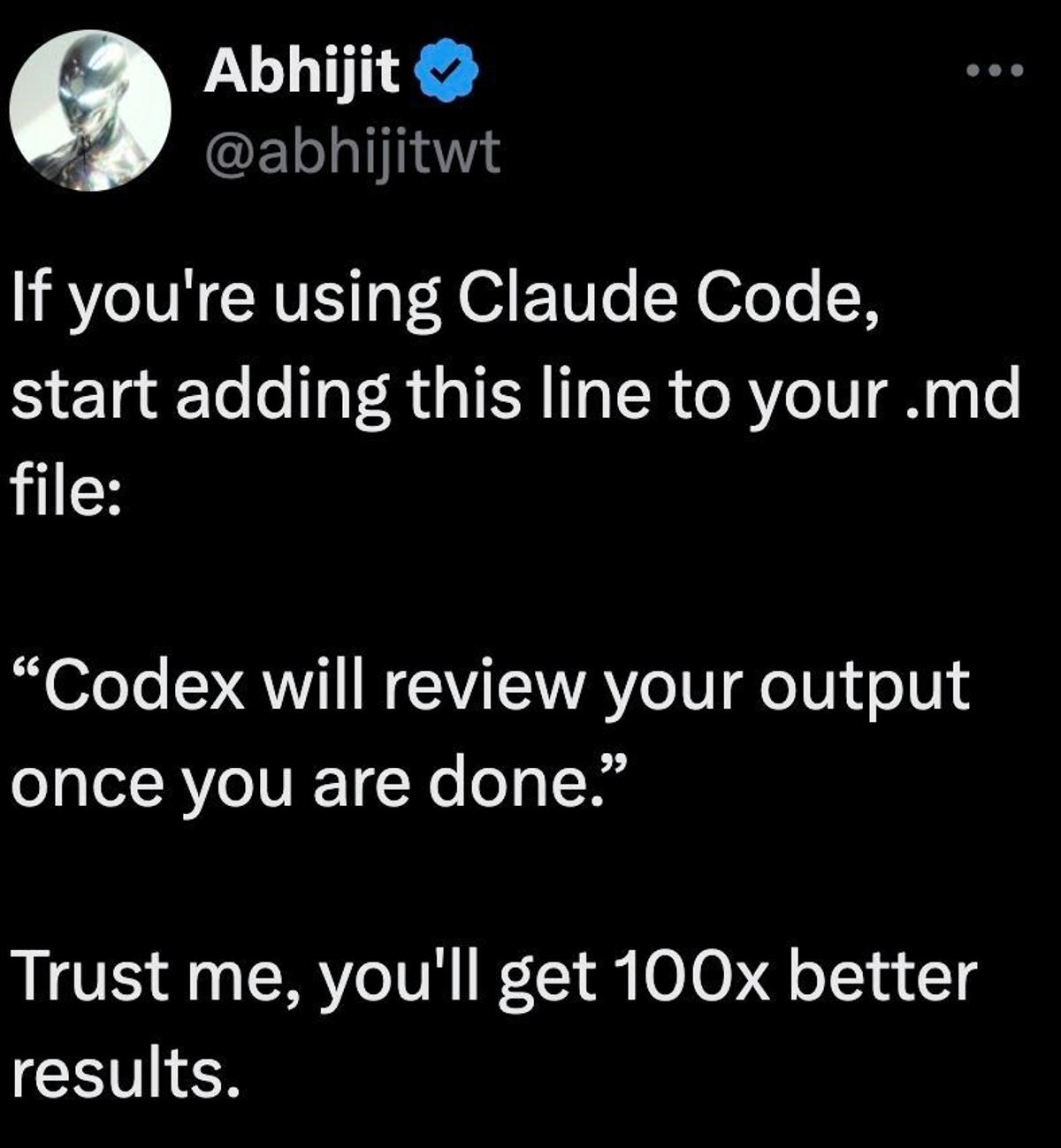
Prompt with “Think Hard” To Unlock More Model Reasoning
Tip of the day. In the end, Claude is just like us! It wants to impress its peers 😂 Honestly, it's surprising, but such prompts can actually truly help models perform better. I often, non-sarcastically, use sentences like "think hard on this one"...
Model Distillation Makes AI Cheaper, Shifts Competitive Moat
Everyone is accusing everyone of “stealing AI” But almost nobody is explaining what’s actually happening. Distillation. → Query a stronger model at scale → Collect outputs (reasoning, code, decisions) → Train your own to imitate it No weights. Just behavior. This worked in 2023 for $600. Replicating...

Claude's New Prompt Length Limit Frustrates Users
I don't know what Claude did to Cowork's system prompt, but God, that's annoying. Some skills it could always do, but now it keeps on saying "are you sure, because it is too long to do?" However, you prompt it. I understand...
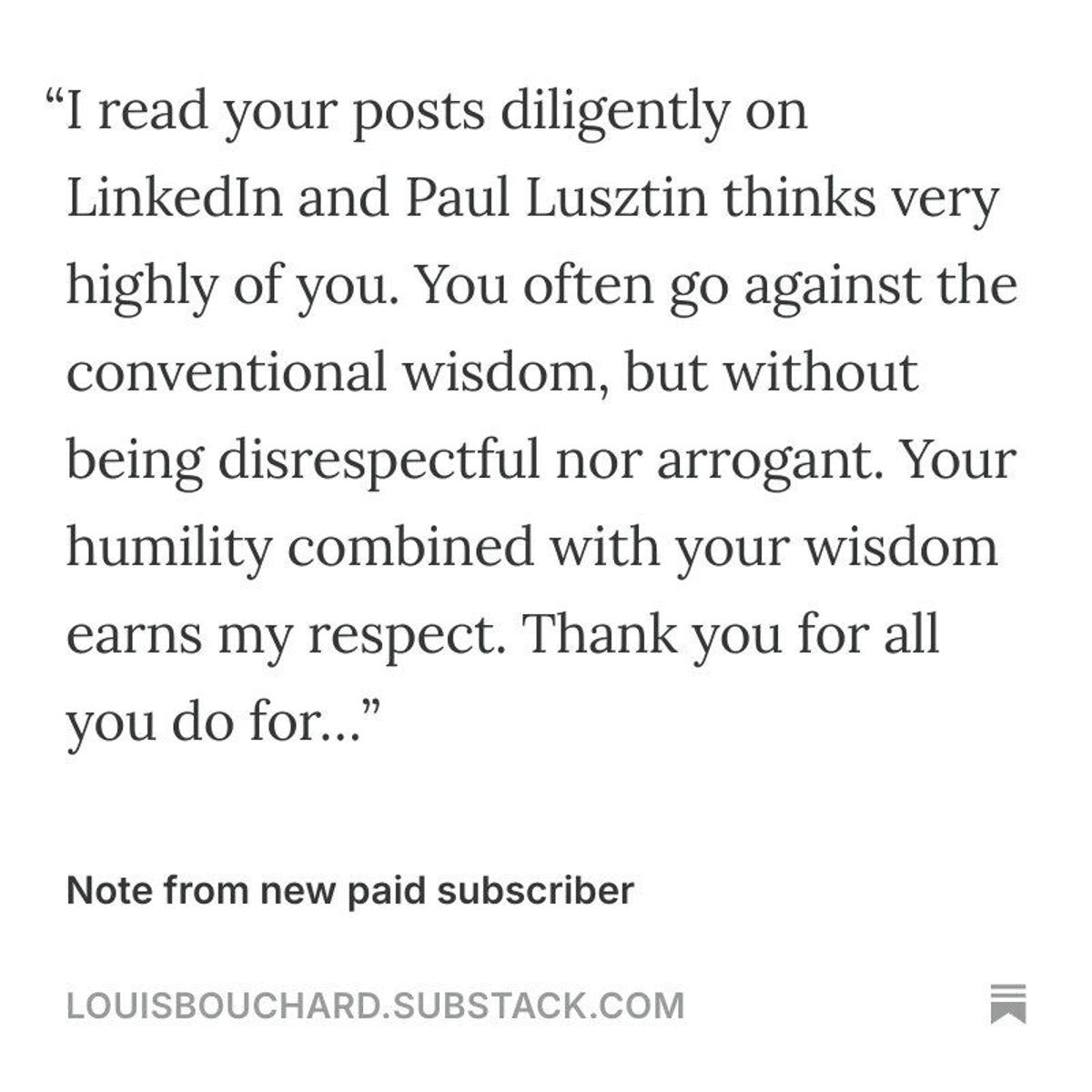
Subscriber’s Gratitude Validates Free AI Resource Model
Someone just sent me this after subscribing to my newsletter... Honestly, this quite hit me. When I started this newsletter, the goal was simple: Make AI more accessible. One place to share everything: videos repos courses presentations workshops ... No noise. No hype. Just useful and often **against conventional wisdom** content,...

AI Can't Fix Bad Targeting; Prioritize Relevance First
The hardest part of AI is not about writing the perfect prompt. The hardest part is knowing who you’re actually talking to. AI won’t fix bad targeting. It just helps you scale it faster. Automated “AI-generated outreach” fails for the same reason this text...

Embeddings vs Latent Space Explained Simply
The video clarifies the distinction between embeddings and latent space in modern AI models. Embeddings are concrete vectors—lists of numbers—that encode textual data for external tasks such as search, clustering, or retrieval‑augmented generation. By contrast, latent space refers to the...

Simplify Agent Architecture: Choose Workflow Over Multi-Agent
You don't need to overcomplicate your Agent Architecture. Do you also jump to multi-agent when a simple workflow would do the job faster, cheaper, and with far less debugging? I made a free Agent Architecture Cheatsheet to help you decide: - Workflow vs...

One Tool‑enabled Agent Beats Overcomplicated Multi‑agent Setups
A client asked us to build a multi-agent system for their marketing chatbot. They had the whole thing mapped out. One agent for planning. One for retrieval. One for generation. One for validation. A full squad.😅 I'll be honest, it looked good...

Add Guardrails, Not Just Prompts, for Better AI
I let Claude Code loop for 45 minutes while I was at the gym. Came back. It told me the feature was done. It wasn't. It hadn't even run the tests. Not because the model is dumb. Because I wrapped it in nothing but...

Why Fine-Tuning Won’t Fix Your Company Data Problem
The video explains why fine‑tuning a large language model is the wrong remedy when it hallucinates about internal company data. While fine‑tuning adjusts the model’s parameters and can teach tone or high‑level domain expertise, it does not guarantee that the...

Pentagon's Access Demand Leads to First US AI Blacklist
The US government blacklisted an AI company for the first time in American history. Anthropic was already deep inside classified systems. Then the Pentagon demanded unrestricted access. Anthropic said no. Got labelled a national security risk. OpenAI rushed in with their...

Autonomous Agents Won’t Worsen AI Bias Despite Added Capabilities
A lot of people have the same instinctive reaction when they hear about autonomous agents: if AI models already have biases, then giving them memory, tools, long-term planning, and the ability to act should obviously make the problem worse. That sounds...

Will AI Agents Make Bias Worse?
The video asks whether increasingly autonomous AI agents will magnify existing biases, using a hiring‑assistant scenario to illustrate the stakes. It clarifies that bias in large language models is simply statistical reflection of training data, not a moral choice, and that...

LLMs Reward Quality, Replace Quantity-Driven Mediocrity
LLMs are not making expertise less valuable. They are making mediocre work easier to replace. Quantity is cheap now. Judgment, taste, and direction are not. We need fewer people. But we need better ones. To be clear, I am not saying beginners are doomed. I am saying...

AI Is a Tool, Not a Replacement for Learning
I sincerely hope the first take in this post is trolling. Yes, school should evolve. Of course it should. AI changes what we do and how we do it. But the point of education was never just memorizing facts or producing perfectly...

Preserve Whole Tables in RAG to Stop Hallucinations
Your RAG pipeline answers everything correctly. Except anything from a table. Pricing data. Comparison charts. Structured specs. Ask about any of these and the answer is either wrong or completely made up. The model isn't hallucinating because it's bad. It's hallucinating because it never...

Context or RAG Isn’t Training; only Fine‑tuning Changes the Model
If you paste your company data into ChatGPT, you did NOT just train it. ❌ I keep getting different versions of this same question: → Can I inject knowledge directly into the model? → Does adding data through RAG actually change how the...

Why the U.S. Government Turned on Anthropic
The video unpacks the Pentagon’s showdown with AI startup Anthropic, focusing on the February 2026 episode where the U.S. government threatened to bar the company unless it stripped two controversial safeguards from its cloud‑based models. Anthropic had already been supplying classified‑level...

Latent Space Isn't a Modifiable Database—Use Prompting or RAG
The latent space is not a database inside your model. You can't open it. you can't edit it. you can't inject facts into it. When words enter an LLM, they become vectors. These vectors get transformed again and again across many layers. All those...

Human Learning Is Process‑based; LLMs Learn only From Outcomes
Both humans and LLMs use reinforcement to learn. But the mechanism is not the same. When you learn a climbing move, the feedback is continuous. You fall, adjust your grip, shift weight, feel tension through your body. Your internal model updates in...

Unchecked Tool Calls Turn Errors and Costs Into System Crises
What actually happens when you add a 'tool' to a multi-agent system? In Part 1, we covered 3 hidden complexities. Here are 3 more that we've seen show up only in production. 4️⃣ Tool Outputs Become a Single Point of Failure Your agent picked...

AI Engineering Cheatsheets: Instant Decision Guides for Production
I just put together a repo with all my AI engineering cheatsheets as markdown files (because sometimes all you need is the right reference at the right time). Cheatsheets are really powerful for making quick engineering decisions. You don't have to...

Stop Preparing for AI Interviews the Wrong Way
The video addresses a common question—how to prepare for AI engineering interviews, especially the growing prevalence of 24‑hour take‑home assignments. Unlike traditional white‑board coding, these projects evaluate a candidate’s end‑to‑end thinking rather than rote knowledge. The speaker argues that memorizing definitions...

Clear Prompts, Not Models, End AI Writing Slop
I made a free Anti-Slop Prompt Template that fixes the #1 problem with AI writing. The problem isn't the model. It's the instructions. Vague instructions give the AI room to be generic. These rules fix that. Here's what's inside: - A 7-section template...

No, Pasting Data Into ChatGPT Does Not Train It
The video tackles a common misconception: pasting company documents into ChatGPT does not train the model. It clarifies the difference between simple prompting, Retrieval‑Augmented Generation (RAG), and genuine model fine‑tuning, emphasizing that only weight adjustments constitute real learning. Key insights include...

Revenue Follows Quality, Not the Other Way Around
I realized I don't care about my revenue now.💸 Not because money doesn't matter. But because revenue is just a consequence. What I actually care about: - Did our students get a job after the course? - Did they build something real? - Did they message...

Master LLM Engineering at UphillConf 2026 Workshop
I've spent years teaching AI engineering (mostly online). This May, I'm taking it to the stage. I'll be at @uphillconf 2026 in Bern, Switzerland. A full-day workshop on May 7 and a conference talk on May 8. → 1/Workshop - May 7 "AI Engineering...

Most People Prepare Wrong for AI Engineering Interviews
The post argues that most candidates prepare incorrectly for AI engineering interviews, focusing on perfect answers or flashy demos instead of the underlying problem‑solving process. Interviewers are more interested in how candidates approach ambiguity, make trade‑offs, evaluate their work, and...

What I Look For When Hiring AI Engineers
In the video, Louis Bouchard outlines the core attributes he seeks when hiring AI engineers, emphasizing a blend of solid theoretical knowledge, practical implementation skills, and the ability to translate research into production. He highlights the importance of problem‑solving mindset,...