

Build Real AI Projects, Not Prompt Tricks, for Interviews
You don’t prepare for AI engineering interviews by collecting prompt tricks or LeetCode. You prepare by building something real. Because interviews don’t reward: “I know this technique.” They reward: “I built this. Here’s how it works. Here’s what failed. Here’s what I measured. Here’s what I’d improve.” That’s why I’m stubborn about project-based learning. The real skill is not prompting. It’s the full loop: Define the problem. Choose a baseline. Collect and clean data. Build the pipeline. Evaluate properly. Iterate. Document tradeoffs. Deploy something that runs outside your notebook. If you’ve never gone through that entire cycle, interviews feel abstract and stressful. If you have, they feel familiar. That’s exactly why we built our Full Stack AI Engineering course around one core idea: You don’t just learn RAG, prompting, fine-tuning, and agents in isolation. You build a real LLM product end-to-end. You start with data collection. You build a full RAG pipeline. You evaluate it. You improve it. You deploy it. You submit your own final project. You walk away with a working product, not notes. If you’re serious about transitioning into LLM roles or leading GenAI projects properly, I’ll put the link in the comments. What’s one project you built that changed how you think about AI engineering?

Scale AI Training: Replace Human Feedback with AI Evaluations
Training AI with human feedback works well. But humans are slow, expensive, and inconsistent. So how do you scale feedback to millions of examples? You replace the human with AI — or remove opinions entirely. That's RLAIF and RLVR. Swipe through the carousel to understand: RLAIF...
Ask Three Questions Before Building or Using APIs
A client messaged me frustrated last month. They'd spent 3 months building something from scratch... that an API could have handled in a week. I've seen the opposite too. Teams so dependent on third-party APIs that one pricing change broke their entire business model. Both...

Boring, Well-Documented Work Beats Flashy AI Projects
After 100+ AI engineering interviews, here’s the pattern I didn’t expect: The strongest candidates are not the ones with the coolest projects. They’re the ones that care enough to make the boring work. Boring is good. Boring means: clear scope clear outputs clear measurement clear tradeoffs clear documentation One...

How AI Agents Actually Work: ReAct vs Plan-and-Execute
The video explains two agentic AI patterns—ReAct (Reason+Act) and Plan-and-Execute—that enable large language models to plan, use tools, verify results, and adapt mid-task instead of producing single-pass, unverified outputs. ReAct interleaves thought, action, and observation in loops, allowing dynamic recovery...

Quantify AI Evaluations: Simple Accuracy Beats Intuition
Quick question for AI engineers (and yes, it’s uncomfortable): If your evaluation is “it looks right”… what happens when it looks right and is wrong? With these kinds of evaluations, you probably won't pass the first interview. This is why I push...

LLMs Hallucinate; They’re Pattern Matchers, Not Calculators
You asked ChatGPT a question. It answered confidently. It was completely wrong. LLMs don't check facts. They predict the next likely word. That's called Hallucination. Also LLMs have Poor Mathematical & Logical Reasoning. They are not calculators. They are pattern-matchers. Swipe through the carousel to understand: Hallucination...

Reproducibility Beats Impressiveness in AI Take‑Home Submissions
I have a simple take-home rule for our AI engineering interviews: If I can’t run your project in a fresh environment quickly, the project isn’t done. Not because I’m strict. Because that’s what working in a team feels like. A strong README doesn’t read...

Benchmarks Aren’t Enough: Use Metrics for Real AI Performance
How do you know which model is actually better? For that we use Benchmarks. Benchmarks measure raw capability. But you can't rely only on benchmarks. A model can score high on tests and still give terrible answers in real use. That's why we also measure...

Build a Tiny End‑to‑end Pipeline, Then Ship, Measure, Explain
If you want practice that actually maps to modern AI engineering take-homes, do this. Not “study more questions”. Build a small pipeline and prove it works. A realistic weekend plan: Hour 0 to 1: pick 10 messy documents (invoices are perfect) Hour 1 to 3:...

AI Now Handles Text, Images, and Audio Simultaneously
Early AI models could only handle one type of input. Now they can process text, images, and audio at the same time. That's multimodality. Reasoning models work differently. They break problems into steps first. Like a built-in "let's think step by step." Swipe through the carousel...

Distilled Small Models Power Local AI Writing Assistants
MacBooks run AI writing assistants locally. No internet needed. That's what small language models make possible. Big AI models are powerful. But they’re also expensive to run. As AI moves into real products, that becomes a problem. SLMs are built to do specific tasks well. They’re faster,...

Show Process, Not Perfection, in AI Take‑Home Interviews
A question I get all the time: “How do I prepare for AI engineering interviews? Especially now that companies give 24-hour take-homes?” Here’s the uncomfortable answer. Most people prepare for interviews as if they were trivia games. They memorize definitions. They collect question lists. They grind...

The AI Engineer's Dilemma - Choose the Right AI System
The video centers on a pivotal design choice for AI engineers: whether to build a predictable, step‑by‑step workflow or an autonomous LLM‑driven agent. This decision shapes development speed, operational expenses, reliability, and the end‑user experience, and the speaker warns that...

Our New Agentic AI Engineering Course!
The video announces a new Agentic AI Engineering course designed to turn Python‑savvy developers into production‑ready AI engineers capable of building trustworthy, multi‑agent systems. It highlights the industry gap between flashy demos and deployable agents, emphasizing that real‑world agents must handle...

Own Your Data, Not Just Model Tuning
AI teams love tuning models. But they ignore the bike chain: data. Outsourcing labeling to people that care much less on the app’s success. Messy internal docs. No structured knowledge base. No call transcripts. No clean SOPs. Then they ask: “Why isn’t the model improving?” The highest ROI in...

Synthetic Data Ceiling Threatens Future AI Progress
Stack Overflow raised this generation of AI. ChatGPT, Claude, Gemini… they all grew up on human-written code, answers, debates, and mistakes. That human data was the fuel. Now the weird part: More and more content online is generated by models. Future models will increasingly train...

Friction, Not AI, Stops Non‑Technical Teams From Adopting
Non-technical teams aren't afraid of AI. They’re afraid of... - Clunky setup processes - Gatekept technical complexity - Theory they can't act on immediately - Having to master abstractions before seeing results - Learning Python just to "get started." - Outdated training models Teams checking out of AI...

Teaching What You Learn Turns Struggle Into Mastery
I failed to complete my PhD. But I discovered something 10x more valuable along the way... In 2019, I was a Systems Engineering student who loved math. And I fit the typical stereotype for people in my area of study: - Quiet - Nerdy - Introverted -...

42 AI Concepts You Actually Need to Understand LLMs
The episode breaks down the 42 essential concepts that underpin large language models (LLMs) and generative AI, covering topics such as tokens, context windows, hallucinations, embeddings, retrieval‑augmented generation, agents, alignment, and evaluation. By presenting these ideas in plain English without...

Ask 13 Critical Questions Before Building AI Projects
Most AI projects fail before you write a single line of code. Not because the tech is hard. Because you skipped the questions that actually matter. Most teams choose tools based on hype, not requirements. They pick frameworks before understanding scope. And start building before...

Agentic AI: Self‑Directed Planning vs Fixed Workflows
There are two ways to build AI systems. One follows predefined steps. The other decides its own next move. That’s the difference between workflows and agents. And when an AI can plan, choose tools, and act toward a goal on its own — that’s agentic AI. Swipe...

LLMs Don’t Think Like Humans (Here’s Why)
The video argues that large language models (LLMs) do not think like humans; they are trained to predict the next token in a sequence, not to understand meaning or intent. Luis Frana explains that while both humans and machines learn...

Everything You Need to Know About LLMs
The video explains that large language models (LLMs) are inherently limited—hallucinating facts, faltering on complex reasoning, inheriting biases, and being bound by a static knowledge cutoff. It argues that recognizing these constraints is the first step toward building dependable AI...

Unseen AI Agents Pose Hidden Risks without Human Oversight
You're probably already using AI agents without realizing they're making decisions you can't trace back. And if something goes wrong, you won't know until it's too late. AI agents aren't chatbots waiting for prompts. They set goals, plan multiple steps ahead, and take...

How AI Systems Reduce Mistakes
The video explains how AI developers use model ensembles—multiple models or versions working together—to cut errors that single models inevitably make. By aggregating diverse outputs and merging them intelligently, teams can achieve more reliable, stable results in high‑stakes environments. Three primary...

Vibe Coding Lets Non‑experts Build AI Apps Fast
Something funny happened during our recent AI training at NYPL. We had ~30 professionals in the room. Developers, IT folks, managers. Different stacks. Different backgrounds. And suddenly… they were all vibe coding. People who: didn’t have Python installed a week ago hadn’t touched frontend in years were used to...

How AI Double-Checks Itself
The video introduces self-consistency, a technique that transforms the inherent randomness of large language models into a reliability boost by generating several independent answers and aggregating them. Instead of forcing a single deterministic response, the model is run multiple times...

AI Projects Fail From Bad Decisions, Not Bad Models
Most AI projects don’t fail because of bad models. They fail because the wrong decisions are made before implementation even begins. Here are 12 questions we always ask new clients about our AI projects before we even begin work, so you don't...

When Facts Beat Preferences
The video introduces Reinforcement Learning from Verifiable Reward (RLVR), a framework that replaces human or model‑based preference judgments with an automated verifier that checks factual correctness. By tying rewards directly to objective outcomes—such as passing unit tests, solving equations, or...

RLAIF Explained Simply
The video introduces Reinforcement Learning from AI Feedback (RLAF), a method that replaces costly human reviewers with an AI “judge” to evaluate and rank model outputs, enabling small teams to scale alignment work. Human feedback is slow, expensive, and inconsistent, limiting...

Preference Tuning Explained
The video introduces preference tuning as the next step after instruction‑following models, focusing on shaping responses to sound helpful, clear, and human‑like. Rather than merely judging right or wrong answers, developers present paired outputs and label the one people prefer,...

Hacking AI without Code
The video explains that large language models (LLMs) are vulnerable to two distinct attack vectors—prompt injection and prompt hacking—where malicious text can override system instructions or bypass safety filters. Prompt injection occurs when an LLM consumes external content, such as a...

AI Defaults to Common Patterns; Prompt Carefully
This couple asked AI to generate a family for them. The result wasn’t what they asked for... This wasn’t AI judging them. It wasn’t choosing values. And it wasn’t preferring one family over another. It happened because of what AI is trained on. Image models learn...

Chain‑of‑Thought Reasoning Reduces AI Mist
Some questions are easy. Others need real reasoning. If a model jumps straight to the final answer, it can easily make mistakes. That’s where reasoning and chain-of-thought matter. Instead of guessing, the model breaks a problem into steps before reaching a conclusion. Once the prompt is set,...

Stop Overengineering: Workflows vs AI Agents Explained
The video clarifies the often‑confused terminology around AI‑driven workflows, agents, tools and multi‑agent systems, warning that many clients overengineer solutions by mis‑labeling simple pipelines as complex agents. The presenter draws a clear line: workflows are deterministic sequences you predefine, while agents...

AI Forgetfulness Explained: Context Windows Limit Memory
Ever noticed how an AI suddenly forgets what you were talking about? That’s not a mistake. It’s the context window. A model can only see a limited amount of text at once. Once that window fills up, older context drops out. Inside that window, prompting decides...
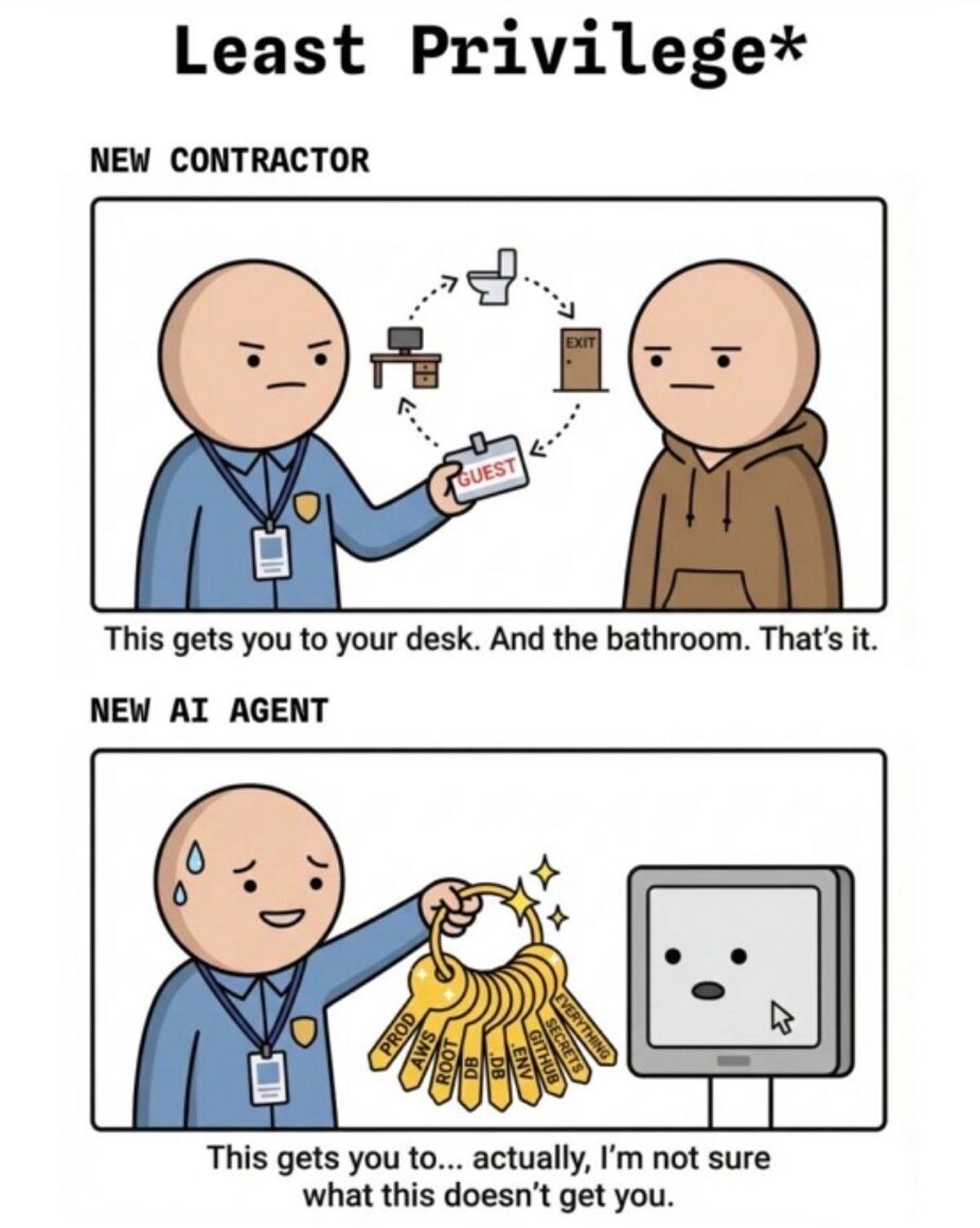
LLMs Aren’t Bulletproof Superhumans, They Have Vulnerabilities
Please stop considering LLM-based systems like bulletproof super humans. It’s powerful but has as much if not more vulnerabilities than one individual could. https://t.co/sYCgwmBDUO

How AI Evaluates Other AI
The video explains a growing solution to a fundamental bottleneck in AI development: evaluating model outputs at scale. Traditional human review of thousands of conversational turns is impossible, so researchers are turning to a technique called “LLM-as-judge,” where a state‑of‑the‑art...
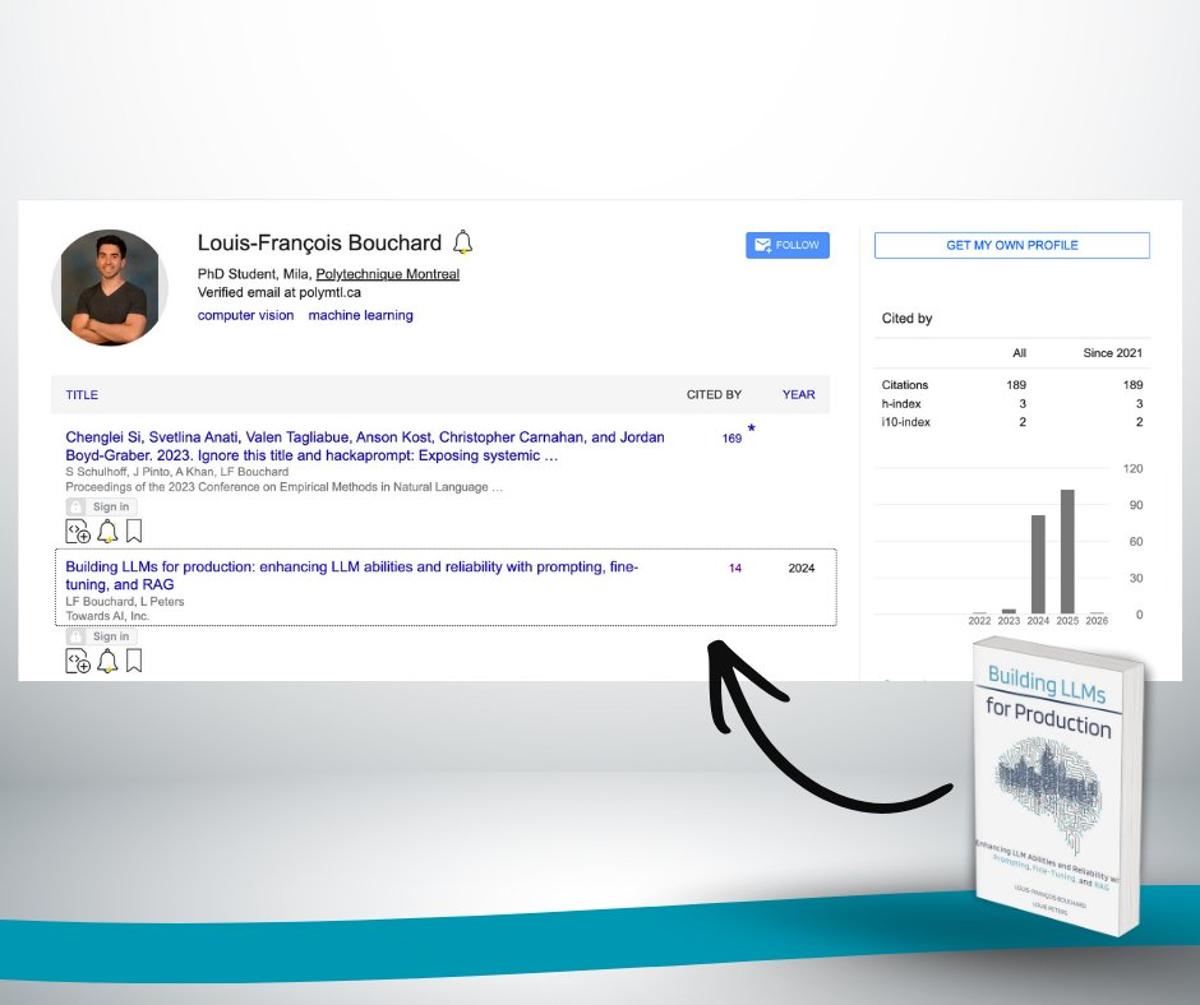
Practical LLM Production Guide Gains Academic Citations
Our book Building LLMs for Production is now being cited by research papers.📚✨ This book came from real work - building systems, fixing failures, rewriting chapters and learning what actually matters in production. It covers how to design, evaluate, and deploy reliable LLM...

Model Scores vs Real Performance
When choosing between LLMs such as GPT‑5, LLaMA or Claude, the video stresses that objective comparison hinges on benchmarks—standardized tests that quantify raw capabilities across diverse tasks. By applying the same evaluation suite, practitioners can rank models and pinpoint strengths...

Choosing the Right Model Type
The video explains how to choose between reasoning models and compact instruct models, emphasizing that architectural labels alone don’t guarantee suitability. Reasoning models are a newer class of large language models built to handle multi‑step problem solving by taking a...

Daily AI Term Videos: 42 Concepts, Halfway Done
For the past 29 days, I’ve been posting one short video every day explaining an AI term🎯 It’s part of a series I’m calling: “Introduction to AI in 42 Terms.” Each video explains one AI concept in simple language - no jargon, no hype,...

What Multimodal Really Means
The video explains that most existing AI systems are limited to a single modality—typically text—meaning they cannot directly interpret images or audio. This constraint hampers their usefulness when users pose questions that involve visual or auditory data, such as asking...

Make AI Drafts Sound Like Your Own Voice
Let's finally make LLMs work for you instead of against you, so your drafts stop sounding generic and start sounding like you. We’ll break down how to spot and remove “AI slop,” fix the generated-looking structure that gives it away, and...

5 Edits That Instantly Make AI Text Sound Human
The video explains how to edit AI‑generated text so it reads like a human author rather than a generic LLM output. Drawing on two years of experience at TORZI, the presenter outlines concrete techniques and a prompt template that keep...

Context, Not Prompts, Drives Consistent AI Answers
Your Prompts Aren’t the Problem❌ A full guide to getting consistently better answers from AI👇 When you use an AI assistant and think “Why is it suddenly confused?” Or “Why did this work 5 minutes ago but not now?” It’s rarely about wording. It’s about context. What the...

How Small Models Stay Smart
Distillation is the core method for turning massive, high‑performing AI models into compact, fast‑running versions without sacrificing much capability. By treating a large pretrained model as a teacher and a smaller model as a student, developers let the student mimic...

Multiple APIs ≠ Multi‑Agent: Use One Agent Wisely
One model calling 10 APIs is NOT a multi-agent system.❌ This is one of the most common mistakes I see. Tools are capabilities. Agents are decision-makers. If one model decides what to do next and calls multiple tools, you still have one agent, not many. Misunderstanding this...

Fine‑tuning Improves Feel, Alignment Ensures Safe Behavior
Do you know why a model feels “better” after fine-tuning? And why a very smart model can still give unsafe or confusing answers? In this post, we break down Fine-tuning and Alignment. This is part of Introduction to AI in 42 terms (we’ve covered...