

Build In-Demand Skills, Turn Entrepreneurship Into Low-Risk Experiment
Taking the leap into entrepreneurship doesn’t have to be reckless. Shaw Talebi’s story is the blueprint for doing it safely. He gave himself oxygen: 12 months of runway. That alone turned a “risky jump” into a reversible experiment. Worst-case scenario? He could return to a data science job with ease because he had built real, in-demand skills. Best-case scenario? He finds something that works before the money runs out. And he did. One month before hitting zero, he launched his first AI cohort and made 10K. That was the signal. From there, he doubled down. The lesson is simple: build skills the industry wants, and entrepreneurship becomes low-risk. You’re never stuck. You’re exploring with a safety net. That’s why at Towards AI, and why Shaw teaches as well, we focus on giving people the foundational skills that make them employable and able to experiment with building. When you have valuable skills, opportunity becomes optionality. I’m Louis-François, PhD dropout, now CTO & co-founder at Towards AI. Follow me to learn more about AI 🚀 #entrepreneurship #founderlife #careertransition #ai #indiehacker

How To Try Entrepreneurship Without Ruining Your Life
The video tackles a practical question many aspiring founders face: how to dip a toe into entrepreneurship without jeopardizing financial stability. Using the experience of Shah Talibi as a case study, the presenter outlines a step‑by‑step framework that hinges on...

Master Python Projects with a Simple Four-Step Workflow
If you’re learning Python and building projects follow this simple workflow: Plan → Write → Test → Debug (+ Code with AI) This carousel breaks down the workflow beginners should use to build projects. If you want to learn Python + AI through hands-on...

Why Developers Should Not Ignore Kimi’s CLI
The video announces Kimi’s newest offering – a command‑line interface (CLI) agent that brings AI‑driven coding assistance directly into the developer’s terminal. Positioned as a competitor to established tools like Cloud Code, Gemini and OpenAI’s offerings, the Kimi CLI aims...

The Truth About Working for Yourself in AI
The video explores the realities of transitioning from a traditional AI role within a large corporation to running an independent AI consultancy, using Shah Talebbi’s journey from a data‑scientist at Toyota to founder of an AI education community as a...

UK Court Rules AI Training Not Copyright Infringement
Getty Images sued Stable Diffusion (Stability AI) in the UK and many expected this case to finally answer a big question: "Is training AI on copyrighted data illegal?" But the outcome surprised everyone. Getty claimed millions of their photos were used during training and...

Two AI Agents Streamline Product Shipping in Minutes
Everyone asks how to ship faster as an AI engineer. @ShawhinT nailed the answer. He’s a former senior data scientist turned entrepreneur and one of the most efficient AI builders I know — the guy is literally shipping full products,...

How Fast Can You Build With AI?
The video explores a streamlined workflow for AI engineers aiming to ship products at maximum speed, featuring Shah Terebi’s personal methodology. Terebi, a former senior data scientist turned AI educator, outlines how he leverages a combination of voice‑driven ChatGPT sessions,...

Gemini 3 & Nano‑Banana
Proudly repping that Gemini merch. Thanks for sending that @googleaidevs @GoogleAI ! Gemini 3 and all suites of models including nano banana 2.5 are a clear step forward and we use it in most of our projects and courses. Honestly, amazing progress...

Open-Weight Models Accelerate AI; China Poised to Lead
We keep talking about “open-source models" But honestly, that’s not where most of the real momentum is right now. What’s actually shaping the ecosystem today are "open models" Especially the ones released as open weights. Not fully open-source. Not fully closed either. Just open enough...

Upgrade Skills, Not Just Hardware, for AI Success
Everyone’s out here upgrading their setups today. New laptops, new GPUs, new toys. But the truth is simple: the real leverage isn’t the machine. It’s whether you actually know how to build and deploy AI on it. So if you’re upgrading...

Build Real AI Apps with 40% Off Today
If you’ve been wanting to jump from using AI tools to actually building real AI applications, this is your moment. The Black Friday window just opened for the Towards AI Academy, and it’s the lowest price we offer all year....

Community BFCM: $349 → $209 for Full-Stack AI Engineering
In this brief Black Friday announcement, Louis‑François Bouchard promotes a 40% discount on all AI engineering courses, highlighting the Full‑Stack AI Engineering program dropping from $349 to $209 as the flagship offer. He outlines how the course equips learners with...

KV Cache Speeds up AI After First Prompt
Your first question to an AI model takes a moment… But the next ones appear almost instantly, there’s a simple reason behind it. The model keeps a small snapshot of the work it already did. This is called the "KV Cache". When an AI...

AI Uses Embeddings, Not Memory, to Understand Context
Ever wondered how AI “remembers” your question… without having memory? 🤔 Every time you chat with an LLM, it somehow knows what you said before. But here’s the secret: It doesn’t remember your words. It understands meaning through something called embeddings. Embeddings are how machines...

LLM Production Guide Now Available in Simplified Chinese
Another cool milestone to share: My book Building LLMs for Production just got translated into Simplified Chinese!! …and I (again) can’t really proofread it. 😅 Still, it feels incredible. Posts & Telecom Press reached out last year asking to translate the book, and...

Essential ML Primer: From Basics to Cutting‑Edge Techniques
Since my review of the book actually made it inside, I'll just share it here: This book is an excellent starting point for beginners looking to understand the essential history and foundational concepts of machine learning. With well-structured code sections...
Is Synthetic Data Ruining LLMs?
The video centers on the contentious role of synthetic data in training large language models (LLMs) and vision‑language models (VLMs), featuring Leticia, a newly minted PhD who specializes in these areas. She weighs the benefits and drawbacks of generating artificial...

Synthetic Data Boosts Small Models, VLMs Need It
Synthetic data might be the most misunderstood topic in AI right now. Is it a cheat code for training better models or a trap that slowly collapses model diversity? Here's what @AICoffeeBreak, one of the sharpest minds in VLMs and...

VLMs Hallucinate when Text Dominates over Visual Grounding
What if your vision language model isn’t actually seeing… but mostly guessing from text? 👀 @AICoffeeBreak explains it perfectly: when VLMs rely too heavily on text, they start hallucinating answers based on the most common phrasing in their training data instead...

VLMs Rely Too Much on Text !!
The video highlights a growing concern in the field of vision‑language models (VLMs): they tend to lean heavily on textual cues at the expense of visual grounding, leading to what researchers call "text‑driven hallucinations." Leticia, a recent PhD graduate specializing...

Stay Relevant: Master AI Faster Than a Degree
𝗬𝗼𝘂 𝘄𝗼𝗻’𝘁 𝗯𝘂𝗶𝗹𝗱 𝗮 𝗰𝗮𝗿𝗲𝗲𝗿 𝗶𝗻 𝗔𝗜 𝗶𝗳 𝘆𝗼𝘂 𝗸𝗲𝗲𝗽 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗹𝗶𝗸𝗲 𝗶𝘁’𝘀 𝟮𝟬𝟮𝟬. A lot of people ask me if it’s still worth doing a Master’s to learn 𝘼𝙄. Honestly, for most people, it’s not about the degree anymore. It’s about staying...

AI Success No Longer Requires Academic Publications
Many people still believe you need to publish research to succeed in AI. That might’ve been true a few years ago, but things have changed 👇 I’ve done research during my Master’s and PhD. Most of my work never made it to...
Why AI “Forgets” Your Conversation
The video explains why large language models (LLMs) like ChatGPT appear to “forget” earlier parts of a conversation: they simply lack a true memory and are constrained by a fixed context window of only a few thousand tokens. When a...

Real-World AI Lessons for Production LLMs Inside
I packed years of real-world AI lessons into one book. If you want to actually build LLM systems that work in production, it’s all inside. Building LLMs for Production is available on Amazon, O'Reilly, and as an e-book (cheaper) on the...

Everything I Learned About LLMs in One Book
Louis‑François Bouchard, CTO and co‑founder of 2RD AI, introduces his new book *Building LLMs for Production*, a practical guide for developers who want to move from curiosity about large language models to building real‑world, value‑adding applications. The video outlines the book’s...

LLMs Sound Confident, Not Truthful—Question Their Answers
LLMs don’t know what’s true. They just try to sound helpful. If you ask the wrong question, you can still get a very confident answer. And confidence is not accuracy. Use AI to challenge your reasoning, not to replace it. But you need to be...

OK Computer Just Fixed My Slide Deck... By Itself
Today’s video spotlights Moonshot AI’s Kimi platform and its newly launched OK Computer agent mode, a free‑to‑use alternative to the market’s dominant chatbots. OK Computer transforms the traditional LLM from a token‑spitting text generator into an autonomous agent that...

Tavus PALs: AI Avatars with Multimodal Memory
The line between human and machine interaction keeps blurring, and Tavus’s new PALs launch pushes that frontier to the next level. What stands out isn’t just the realism with a nice avatar talking to us, it’s the engineering behind it: multimodal...

Kimi K2 vs GPT-5: The New DeepSeek Moment?
Moonshot AI’s Kimi K2, a 1‑trillion‑parameter mixture‑of‑experts model with only 32 billion active parameters, claims state‑of‑the‑art performance, surpassing GPT‑5, Claude and Grok‑4 on a range of benchmarks including the demanding Humanity‑Last‑Exam test. The model features a 256,000‑token context window, tool‑use interleaving, and...

Tiny 7M Model Beats Massive Counterparts in Reasoning
Tiny 7M Model that Surpassed DeepSeek-R1, Gemini 2.5 Pro, and o3-mini at Reasoning on ARC-AGI 1 & 2 🧠 Last week, I attended @jm_alexia's talk at Mila and I don’t think anyone expected a 7-million-parameter model to outperform models 10,000× larger. Alexia...
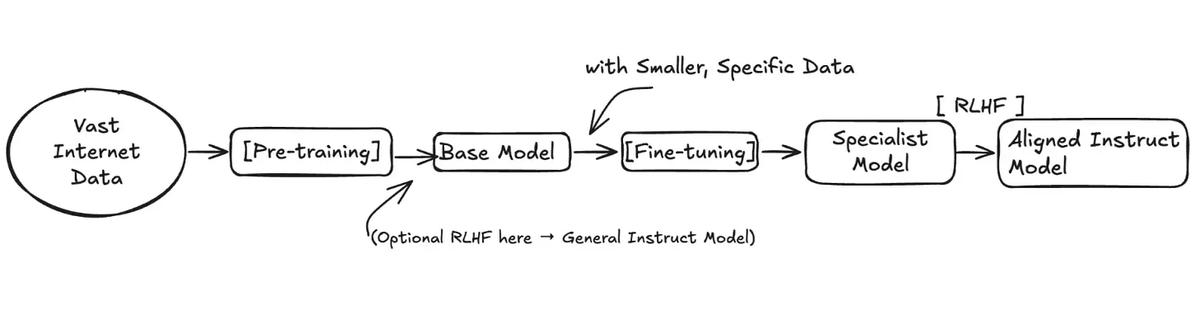
Plain-English Guide to How LLMs Really Work
Excited to share our new guest post with @systemdesignone on the System Design Newsletter: “Everything You Need to Know to Understand How LLMs Like ChatGPT Actually Work — 33 Concepts, No Math.” If you’ve ever felt LLMs are “magic,” this is your...

Overthinking Hurts LLMs: Intuition Beats Chain‑of‑thought
What if thinking harder actually makes LLMs worse? 🧠 A new paper by Tom Griffiths shows that both humans and AI models can perform worse when forced to reason step-by-step. In tasks like face recognition or grammar learning, “thinking out loud”...
When Less Thinking Makes AI Smarter 🤯
A recent paper by Tom Griffith finds that prompting large language models to engage in explicit reasoning—often called "thinking" or chain‑of‑thought—can actually lower performance on a range of tasks compared to direct answers. The phenomenon mirrors Kahneman’s System 1 versus System 2...
RAG Boosts Memory, Fine‑tuning Sharpens Judgment
Most people still confuse RAG and fine-tuning — and it’s costing them weeks of wasted effort. Here’s the simple truth: RAG gives your model better memory. Fine-tuning gives it better judgment. RAG connects your model to an external brain so it can retrieve...
RAG or Fine-Tuning? Most People Get This Wrong...
The speaker warns that many organizations mistakenly favor fine‑tuning LLMs over Retrieval‑Augmented Generation (RAG), despite fine‑tuning’s high data, expertise, and cost requirements. Fine‑tuning demands millions of tokens, extensive data cleaning, and specialized ML talent to avoid over‑ or under‑training, making...
4x Faster Coding with AI? Meet Composer by Cursor
Cursor unveiled its 2.0 platform alongside a new AI model called Composer, which the company says generates code up to four times faster than competing models while delivering near‑state‑of‑the‑art quality. Composer appears to be a fine‑tuned version of a Chinese...
How to Fix LLM Hallucinations ?
The video explains that LLM hallucinations arise when context is missing, ambiguous, or overly large, and can be curbed by grounding the model in clean, factual data through precise prompts and retrieval‑augmented generation. It details a pipeline that includes clear...

New AI Models Hype, but Performance Often Unchanged
Have you seen OpenAI’s Atlas? And googles new update? And and minimax m2!! I just switched to the most recent Qwen model and… it performs the same 😂 This field is quite special to work in. So much hype around so...

Last Call: November AI Engineering Cohort Closes in 48 Hours
Louis‑François Bouchard’s October 31 note warns that enrollment for the November Full‑Stack AI Engineering cohort closes in 48 hours, with a live kickoff on November 2. The program, priced at $349 (one‑time) after a free preview, promises a production‑ready GenAI playbook previously...

MiniMax M2: The Open LLM Beating Claude and Gemini!
Minimax M2, an open 200-billion-parameter mixture-of-experts (MoE) model with only ~10 billion active parameters at inference, is being touted as a frontier alternative that outperforms many proprietary models on key benchmarks. The model ranks fifth on the artificial analysis benchmark,...

Research Skills Grow Without a PhD: Learn, Build, Share
During my conversation with @PetarV_93 - Senior Staff Research Scientist at @GoogleDeepMind and Lecturer at Cambridge. He said something that stuck with me. “You don’t need a PhD to think like a researcher. You need curiosity, discipline, and the courage to keep...

AI Research Agents Deliver Deep, Cited Analyses Faster
Ever tried using ChatGPT or Gemini for research, only to hit a wall when you need real multi-step analysis or technical synthesis? That’s why I tried OpenAI’s $200/Month plan for their research agent! After wasting hours piecing together reports and technical...

AI Book Crosses Language Barrier with Korean Translation
My book Building LLMs for Production just got translated into Korean. …and I can’t even read it to proof it. 😅 Still, it feels incredible. A Korean publisher reached out last year asking to translate the book, and now it’s available in Korean...

LLMs Follow Instructions, Not Truth—Verify Your Assumptions
When you use an LLM, remember this: it’s been trained to follow instructions, not to know what’s true. That means if you don’t know what you’re talking about, you might just be confidently guiding it toward your own mistakes — and it...

Use RAG for Dynamic Facts, Fine‑tune for Stable Expertise
Most people still mix up RAG and fine-tuning. Many of our clients start by wasting time fine-tuning when RAG would've worked. Here's the real difference:👇 ✅ RAG = Your model's external brain It doesn't change the model at all. Just connects it to a...

Agent Skills vs MCP: Complementary Roles in AI
New video! Agent Skills vs MCP: Which Is Better? A short video to understand why both exist and where each sits in the AI ecosystem. https://t.co/PodcbFyLFW https://t.co/PodcbFyLFW

Agent Skills vs MCP Which Is Better?
Entropic’s new agent skills package a skill as a simple folder containing a YAML metadata file, a skill.md description, and optional scripts or documents, providing a file-system, plugin-style alternative to the MCP client-server protocol. Unlike MCP, which exposes tools via...
Google’s Veo 3.1 Just Beat Sora?! 😳
Google has released Veo 3.1, a significant update to its AI video-generation model that improves output quality and introduces several new creative controls. Users can now supply one or multiple images as “ingredients” to populate or style generated videos, animate...
Weekly Free AI Deep Dives, No Fluff
Every week, I share something exclusive (and completely free) that I don’t post anywhere else. New tools, research, lessons, and ideas shaping the future of AI - broken down simply, without the noise. If you like learning how things actually work, this...