
Zach Wilson
Data engineer; FAANG‑scale data engineering, platform tips

Stunning Cohort Success Yet Feeling Detached After Airbnb Exit
My three cohorts this year have had stunning results: - 98% customer satisfaction - 6 billion tokens burnt - 18% of students have already seen a career change (reaching this milestone in 3 months is wild) - 3 different startups funded - ~300 unique capstone projects built Yet I feel the most detached from this work that I ever have since I quit working at Airbnb. The two paths I see for myself: 1/3
Human‑augmented Agentic Coding Maximizes ROI
Many companies are wasting thousands of dollars on unclear autonomous agents. Other companies are too conservative and think automated meeting notes makes them “AI-native” The middle path is where you see the highest ROI: - engineers using agentic coding This has clear success...
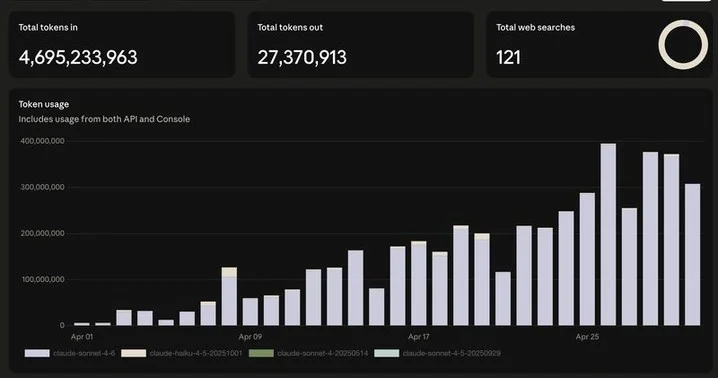
Performance‑First Proxy Tracking Saves Costs and Student Frustration
My students burnt 4.7 billion tokens in 30 days, and I spent over $15,000 on Anthropic credits. It was totally worth it, and here's what I learned: - Proxy tracking is good, but it needs to be performant, otherwise, your students...

Snowflake's Micro-Partitions Promote Lazy Modeling, Undermine Optimization
eczachly I hate Snowflake micro partitions and optimizations for a few reasons - they make data modeling lazy If you don’t have to understand the partitioning or shape of your data. You can just slap the data into Snowflake and call it a...

Choosing Exit Over 2% $50M Gamble
I've been thinking about this math a lot and weighing if that 2% chance of $50m is worth it. I've built DataExpert.io to $2M ARR over the last three years. I could exit for $8-10m now. In 3 years not...