

Moonshot AI Releases 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔 to Replace Fixed Residual Mixing with Depth-Wise Attention for Better Scaling in Transformers
Moonshot AI introduced Attention Residuals (AttnRes), a drop‑in replacement for standard residual connections in PreNorm Transformers that applies softmax attention over previous layer outputs. The approach includes a full version that attends to all earlier layers and a Block AttnRes variant that aggregates layers into blocks, cutting memory and communication costs from O(Ld) to O(Nd). Experiments show lower validation loss across model sizes, with Block AttnRes matching baseline performance that would otherwise require 1.25× more compute. Integrated into the 48‑billion‑parameter Kimi Linear MoE, AttnRes delivers consistent gains on benchmarks such as MMLU, GPQA‑Diamond, and HumanEval with under 4% training overhead.

Meet OpenViking: An Open-Source Context Database that Brings Filesystem-Based Memory and Retrieval to AI Agent Systems Like OpenClaw
OpenViking is an open‑source context database from Volcengine that reimagines AI‑agent memory as a virtual filesystem. It maps resources, user data, and agent skills into hierarchical directories accessed via a `viking://` protocol, replacing flat chunk‑based RAG with directory‑aware retrieval. The...

Zhipu AI Introduces GLM-OCR: A 0.9B Multimodal OCR Model for Document Parsing and Key Information Extraction (KIE)
Zhipu AI and Tsinghua University unveiled GLM‑OCR, a 0.9 billion‑parameter multimodal model designed for efficient document understanding. The architecture pairs a 0.4 B CogViT visual encoder with a 0.5 B GLM language decoder and introduces Multi‑Token Prediction to boost decoding speed by roughly...

Stanford Researchers Release OpenJarvis: A Local-First Framework for Building On-Device Personal AI Agents with Tools, Memory, and Learning
Stanford’s Scaling Intelligence Lab released OpenJarvis, an open‑source framework for building personal AI agents that run entirely on a user’s device. The platform introduces a five‑primitives architecture—Intelligence, Engine, Agents, Tools & Memory, and Learning—to modularize model selection, inference runtime, agent behavior, tool...

How to Build a Self-Designing Meta-Agent That Automatically Constructs, Instantiates, and Refines Task-Specific AI Agents
Developers can now use a meta‑agent framework that automatically designs, configures, and runs AI agents from a simple task description. The system parses the task, selects appropriate tools, memory architecture, and a ReAct‑style planner, then instantiates a fully functional runtime...

ByteDance Releases DeerFlow 2.0: An Open-Source SuperAgent Harness that Orchestrates Sub-Agents, Memory, and Sandboxes to Do Complex Tasks
ByteDance has open‑sourced DeerFlow 2.0, a SuperAgent framework that runs tasks inside isolated Docker containers rather than merely generating text. The system decomposes complex prompts into parallel sub‑agents, each operating in its own sandbox, and then converges results into a...

The ‘Bayesian’ Upgrade: Why Google AI’s New Teaching Method Is the Key to LLM Reasoning
Google researchers propose Bayesian Teaching, a method that trains large language models (LLMs) to emulate a Bayesian assistant’s belief‑updating process rather than simply memorizing correct answers. By fine‑tuning on synthetic flight‑booking interactions, the approach forces LLMs to reason under uncertainty,...

A Coding Guide to Build a Complete Single Cell RNA Sequencing Analysis Pipeline Using Scanpy for Clustering Visualization and Cell...
The article presents a step‑by‑step Python tutorial that builds a full single‑cell RNA‑sequencing (scRNA‑seq) analysis pipeline using Scanpy. It walks through data loading, quality‑control filtering, normalization, highly variable gene selection, PCA, neighbor‑graph construction, UMAP embedding, Leiden clustering, and marker‑gene based...

Building Next-Gen Agentic AI: A Complete Framework for Cognitive Blueprint Driven Runtime Agents with Memory Tools and Validation
The tutorial introduces a full cognitive blueprint framework that structures agent identity, goals, planning, memory, validation, and tool access. It demonstrates how YAML‑based blueprints can instantiate distinct agent personalities, such as a research bot and a data analyst bot, without...

Google Launches TensorFlow 2.21 And LiteRT: Faster GPU Performance, New NPU Acceleration, And Seamless PyTorch Edge Deployment Upgrades
Google released TensorFlow 2.21, promoting LiteRT from preview to a production‑ready on‑device inference framework that replaces TensorFlow Lite. LiteRT delivers a 1.4× speed boost on GPUs and introduces unified NPU acceleration for edge hardware. The update expands low‑precision operator support, adding...

OpenAI Introduces Codex Security in Research Preview for Context-Aware Vulnerability Detection, Validation, and Patch Generation Across Codebases
OpenAI has rolled out Codex Security, an application security agent, in research preview for ChatGPT Enterprise, Business, and Edu customers via Codex web. The tool builds a project‑specific threat model, validates vulnerabilities in sandboxed environments, and generates context‑aware patches. In...

Liquid AI Releases LocalCowork Powered By LFM2-24B-A2B to Execute Privacy-First Agent Workflows Locally Via Model Context Protocol (MCP)
Liquid AI unveiled LFM2-24B-A2B, a 24‑billion‑parameter sparse Mixture‑of‑Experts model, paired with the open‑source LocalCowork desktop agent. The architecture activates only about 2 billion parameters per token, fitting into a ~14.5 GB RAM footprint on an Apple M4 Max. LocalCowork runs entirely offline,...

OpenAI Releases Symphony: An Open Source Agentic Framework for Orchestrating Autonomous AI Agents Through Structured, Scalable Implementation Runs
OpenAI unveiled Symphony, an open‑source framework that orchestrates autonomous AI coding agents through structured implementation runs. Built on Elixir and the Erlang/BEAM runtime, it leverages fault‑tolerant concurrency to manage hundreds of isolated tasks. The system polls issue trackers such as...

YuanLab AI Releases Yuan 3.0 Ultra: A Flagship Multimodal MoE Foundation Model, Built for Stronger Intelligence and Unrivaled Efficiency
YuanLab AI unveiled Yuan 3.0 Ultra, a trillion‑parameter mixture‑of‑experts (MoE) foundation model that activates only 68.8 billion parameters. The model introduces Layer‑Adaptive Expert Pruning (LAEP), which removes underused experts during pre‑training, shrinking total parameters by 33.3% while preserving performance. Combined with an Expert...

Meet SymTorch: A PyTorch Library that Translates Deep Learning Models Into Human-Readable Equations
Researchers at the University of Cambridge introduced SymTorch, a PyTorch library that embeds symbolic regression into deep‑learning pipelines. The tool wraps any nn.Module, records activations, and uses PySR to distill closed‑form equations that replace neural components. In a proof‑of‑concept on...

A Coding Guide to Build a Scalable End-to-End Analytics and Machine Learning Pipeline on Millions of Rows Using Vaex
The MarkTechPost tutorial walks through building a production‑style analytics and machine‑learning pipeline with Vaex on a synthetic 2 million‑row dataset. It showcases lazy feature engineering, approximate city‑level aggregations, and seamless integration with scikit‑learn via Vaex‑ML. The guide also demonstrates model training,...

FireRedTeam Releases FireRed-OCR-2B Utilizing GRPO to Solve Structural Hallucinations in Tables and LaTeX for Software Developers
FireRedTeam unveiled FireRed-OCR-2B, a 2‑billion‑parameter vision‑language model that treats document parsing as a structural engineering problem rather than pure text generation. Leveraging the Qwen3‑VL‑2B‑Instruct backbone, the model introduces a three‑stage progressive training pipeline capped by Format‑Constrained GRPO to enforce syntactic...

How to Build an Explainable AI Analysis Pipeline Using SHAP-IQ to Understand Feature Importance, Interaction Effects, and Model Decision Breakdown
The tutorial demonstrates how to construct a full explainable‑AI pipeline using the SHAP‑IQ library to extract both feature importance and pairwise interaction effects from a Random Forest model trained on the California housing dataset. It walks through environment setup, utility...

Google AI Introduces STATIC: A Sparse Matrix Framework Delivering 948x Faster Constrained Decoding for LLM Based Generative Retrieval
Google DeepMind and YouTube researchers unveiled STATIC, a Sparse Transition Matrix‑Accelerated Trie Index that converts prefix‑tree constraints into a static CSR matrix for vectorized sparse operations. The framework achieves 0.033 ms per decoding step, delivering a 948× speedup over CPU‑offloaded tries...

A Complete End-to-End Coding Guide to MLflow Experiment Tracking, Hyperparameter Optimization, Model Evaluation, and Live Model Deployment
The article presents a step‑by‑step tutorial that builds a production‑grade MLflow workflow, covering tracking server setup, nested hyperparameter sweeps, automatic logging, model evaluation, and live REST‑API serving. It demonstrates how to configure a SQLite backend, use MLflow autologging for scikit‑learn...

Google DeepMind Introduces Unified Latents (UL): A Machine Learning Framework that Jointly Regularizes Latents Using a Diffusion Prior and Decoder
Google DeepMind unveiled Unified Latents (UL), a new framework that jointly trains an encoder, diffusion prior, and diffusion decoder to regularize latent representations. By using a deterministic encoder with fixed Gaussian noise and a reweighted decoder ELBO, UL bridges the...
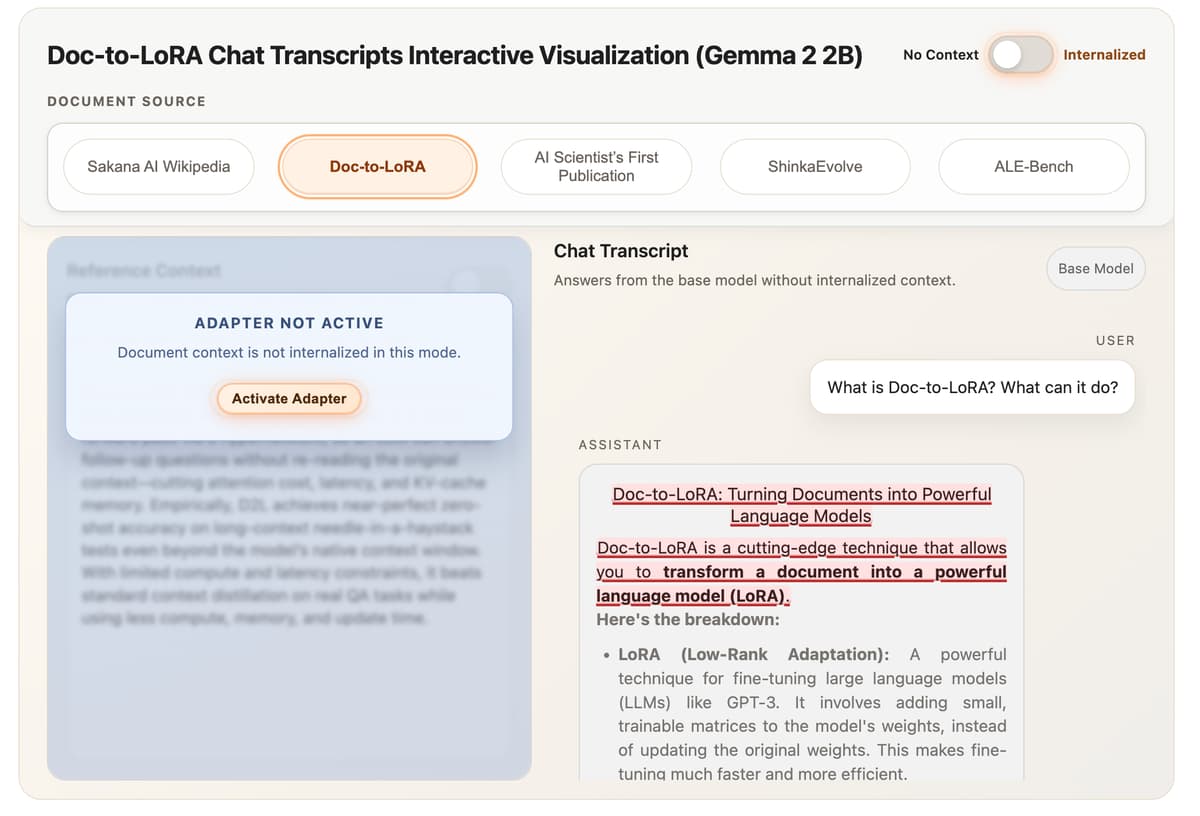
Sakana AI Introduces Doc-to-LoRA and Text-to-LoRA: Hypernetworks that Instantly Internalize Long Contexts and Adapt LLMs via Zero-Shot Natural Language
Sakana AI unveiled two hypernetwork‑based methods—Text‑to‑LoRA (T2L) and Doc‑to‑LoRA (D2L)—that generate low‑rank adaptation matrices for large language models in a single forward pass. T2L creates task‑specific LoRA adapters from plain‑language descriptions, while D2L compresses entire documents into parameter updates, eliminating...
Perplexity Just Released Pplx-Embed: New SOTA Qwen3 Bidirectional Embedding Models for Web-Scale Retrieval Tasks
Perplexity unveiled pplx-embed, a pair of multilingual embedding models built on Qwen3 with bidirectional attention and diffusion‑based pretraining. The 0.6 B and 4 B variants are engineered for web‑scale retrieval, offering native INT8 quantization and Matryoshka representation learning. Two specialized versions—pplx‑embed‑v1 for...

Microsoft Research Introduces CORPGEN To Manage Multi Horizon Tasks For Autonomous AI Agents Using Hierarchical Planning and Memory
Microsoft Research unveiled CORPGEN, an architecture‑agnostic framework that equips autonomous AI agents to operate in Multi‑Horizon Task Environments (MHTEs) where dozens of interleaved, dependent tasks coexist. The paper identifies four failure modes—context saturation, memory interference, dependency‑graph complexity, and reprioritization overhead—that...

Nous Research Releases ‘Hermes Agent’ to Fix AI Forgetfulness with Multi-Level Memory and Dedicated Remote Terminal Access Support
Nous Research unveiled Hermes Agent, an open‑source autonomous system built on the Hermes‑3 Llama 3.1‑based model. It introduces a multi‑level memory hierarchy that records successful workflows as searchable Skill Documents, giving the agent procedural recall across sessions. The platform also provides...

Tailscale and LM Studio Introduce ‘LM Link’ to Provide Encrypted Point-to-Point Access to Your Private GPU Hardware Assets
LM Studio and Tailscale have launched LM Link, a feature that lets developers access remote GPU rigs as if they were locally attached. The solution replaces public APIs and SSH tunnels with a private, WireGuard‑encrypted tunnel built on Tailscale’s userspace tsnet...

How to Build an Elastic Vector Database with Consistent Hashing, Sharding, and Live Ring Visualization for RAG Systems
The tutorial walks through building an elastic vector‑database simulator that uses consistent hashing with virtual nodes to shard embeddings across distributed storage. It includes a live, interactive ring visualization that shows how adding or removing nodes only reshuffles a tiny...

New ETH Zurich Study Proves Your AI Coding Agents Are Failing Because Your AGENTS.md Files Are Too Detailed
A new ETH Zurich study reveals that overly detailed AGENTS.md files degrade AI coding agent performance and raise inference costs. Experiments with models such as Sonnet-4.5, GPT-5.2, and Qwen3-30B showed auto‑generated context reduces success rates by about 3%, while human‑crafted...

Meta AI Open Sources GCM for Better GPU Cluster Monitoring to Ensure High Performance AI Training and Hardware Reliability
Meta AI Research has open‑sourced GCM, a GPU Cluster Monitoring toolkit designed to catch silent hardware failures that can derail large‑scale AI training. The system integrates tightly with the Slurm workload manager, providing job‑level attribution of power, temperature, and error...

Alibaba Qwen Team Releases Qwen 3.5 Medium Model Series: A Production Powerhouse Proving that Smaller AI Models Are Smarter
Alibaba’s Qwen team unveiled the Qwen 3.5 Medium series, including 35B‑A3B, 27B, and 122B‑A10B models that rely on Mixture‑of‑Experts and reinforcement learning. The 35B‑A3B model activates only 3 billion parameters yet outperforms the older 235 billion‑parameter Qwen‑3, demonstrating a new efficiency frontier. Qwen 3.5‑Flash...

Composio Open Sources Agent Orchestrator to Help AI Developers Build Scalable Multi-Agent Workflows Beyond the Traditional ReAct Loops
Composio has open‑sourced its Agent Orchestrator, a framework that replaces the brittle ReAct loop with structured, stateful multi‑agent workflows. The system splits responsibilities between a Planner that decomposes high‑level goals and an Executor that handles tool interactions, reducing greedy decision‑making....

Beyond Simple API Requests: How OpenAI’s WebSocket Mode Changes the Game for Low Latency Voice Powered AI Experiences
OpenAI’s new Realtime API introduces a WebSocket‑based mode that streams audio directly to GPT‑4o, collapsing the traditional STT‑LLM‑TTS chain into a single, stateful connection. The protocol delivers full‑duplex communication, allowing the model to listen and speak simultaneously while maintaining session...

How to Build a Production-Grade Customer Support Automation Pipeline with Griptape Using Deterministic Tools and Agentic Reasoning
The MarkTechPost tutorial shows how to construct a production‑grade customer‑support automation pipeline with Griptape, combining deterministic Python tools and an LLM‑driven agent. Custom tools handle PII redaction, ticket categorization, priority scoring, SLA assignment, and escalation payload creation before any language...

VectifyAI Launches Mafin 2.5 and PageIndex: Achieving 98.7% Financial RAG Accuracy with a New Open-Source Vectorless Tree Indexing.
VectifyAI unveiled Mafin 2.5, a multimodal financial agent that achieved a record‑breaking 98.7% accuracy on the FinanceBench RAG benchmark, and released PageIndex, an open‑source framework that replaces traditional vector embeddings with a hierarchical tree index. The new stack natively ingests SEC...

A Coding Guide to Instrumenting, Tracing, and Evaluating LLM Applications Using TruLens and OpenAI Models
The tutorial demonstrates how to build a transparent evaluation pipeline for Retrieval‑Augmented Generation (RAG) applications using TruLens and OpenAI models. It walks through installing dependencies, chunking documents, creating a Chroma vector store with OpenAI embeddings, and instrumenting retrieval, generation, and...

A New Google AI Research Proposes Deep-Thinking Ratio to Improve LLM Accuracy While Cutting Total Inference Costs by Half
Researchers at the University of Virginia and Google challenge the prevailing notion that longer chain‑of‑thought prompts improve large language model performance. They introduce the Deep‑Thinking Ratio (DTR), which measures the proportion of tokens that only stabilize in the final layers...

Is There a Community Edition of Palantir? Meet OpenPlanter: An Open Source Recursive AI Agent for Your Micro Surveillance Use...
OpenPlanter is an open‑source recursive AI agent designed for micro‑surveillance and investigative journalism. It can ingest heterogeneous data—CSV, JSON, PDFs—and perform entity resolution with probabilistic anomaly detection. The platform uses a recursive sub‑agent delegation engine (default max‑depth 4) and a 2026‑grade...

NVIDIA Releases Dynamo v0.9.0: A Massive Infrastructure Overhaul Featuring FlashIndexer, Multi-Modal Support, and Removed NATS and ETCD
NVIDIA unveiled Dynamo v0.9.0, a major overhaul of its distributed inference platform. The update eliminates NATS and ETCD, swapping them for a ZeroMQ‑based Event Plane and native Kubernetes discovery, cutting operational overhead. It adds full multi‑modal support with an Encode/Prefill/Decode split,...

Zyphra Releases ZUNA: A 380M-Parameter BCI Foundation Model for EEG Data, Advancing Noninvasive Thought-to-Text Development
Zyphra unveiled ZUNA, a 380‑million‑parameter foundation model for EEG signals that uses a masked diffusion auto‑encoder to fill missing channels and boost spatial resolution. The model leverages a novel 4D rotary positional encoding to treat EEG data as spatiotemporal points,...
![[Tutorial] Building a Visual Document Retrieval Pipeline with ColPali and Late Interaction Scoring](/cdn-cgi/image/width=1200,quality=75,format=auto,fit=cover/https://www.marktechpost.com/wp-content/uploads/2026/02/blog-banner23-1-16-1024x731.png)
[Tutorial] Building a Visual Document Retrieval Pipeline with ColPali and Late Interaction Scoring
The tutorial demonstrates how to build a visual document retrieval pipeline using the open‑source ColPali model. It walks through creating a stable Python environment, rendering PDF pages as images, and generating multi‑vector embeddings for each page. Late‑interaction scoring matches natural‑language...

How to Build an Advanced, Interactive Exploratory Data Analysis Workflow Using PyGWalker and Feature-Engineered Data
The tutorial walks through building a fully interactive exploratory data analysis (EDA) workflow inside a Python notebook using PyGWalker. It starts with advanced feature engineering on the Titanic dataset, creating buckets, segments, and DuckDB‑safe columns for both row‑level and aggregated...

Cloudflare Releases Agents SDK v0.5.0 with Rewritten @Cloudflare/Ai-Chat and New Rust-Powered Infire Engine for Optimized Edge Inference Performance
Cloudflare unveiled Agents SDK v0.5.0, merging stateful Durable Objects with a Rust‑based Infire inference engine to run AI agents directly at the edge. The SDK lets each agent keep a persistent SQLite store of up to 1 GB, eliminating external database calls...

Agoda Open Sources APIAgent to Convert Any REST Pr GraphQL API Into an MCP Server with Zero Code
Agoda has released APIAgent, an open‑source tool that turns any REST or GraphQL API into a Model Context Protocol (MCP) server with zero code and no deployments. The proxy reads OpenAPI or GraphQL schemas, generates tool definitions, and uses DuckDB...

Moonshot AI Launches Kimi Claw: Native OpenClaw on Kimi.com with 5,000 Community Skills and 40GB Cloud Storage Now
Moonshot AI has rebranded its OpenClaw framework as Kimi Claw and made it a native, cloud‑hosted service on kimi.com. The platform now offers a persistent 24/7 AI agent environment, a 5,000‑plus skill registry called ClawHub, and 40 GB of dedicated cloud storage...
How to Build a Self-Organizing Agent Memory System for Long-Term AI Reasoning
The tutorial demonstrates how to construct a self‑organizing memory architecture for AI agents that moves beyond flat chat logs toward structured, persistent knowledge units. It introduces a SQLite‑backed database that stores atomic memory cells, groups them into scenes, and maintains...
![[In-Depth Guide] The Complete CTGAN + SDV Pipeline for High-Fidelity Synthetic Data](/cdn-cgi/image/width=1200,quality=75,format=auto,fit=cover/https://www.marktechpost.com/wp-content/uploads/2026/02/blog-banner23-22.png)
[In-Depth Guide] The Complete CTGAN + SDV Pipeline for High-Fidelity Synthetic Data
The article walks through a production‑grade synthetic data pipeline that combines CTGAN with the SDV ecosystem, starting from raw mixed‑type tables and ending with model serialization. It demonstrates how to attach metadata, enforce numeric and categorical constraints, and perform conditional...

Kyutai Releases Hibiki-Zero: A3B Parameter Simultaneous Speech-to-Speech Translation Model Using GRPO Reinforcement Learning Without Any Word-Level Aligned Data
Kyutai unveiled Hibiki‑Zero, a 3 B‑parameter decoder‑only model for simultaneous speech‑to‑speech and speech‑to‑text translation that operates without word‑level aligned data. The system uses a multistream architecture, the Mimi audio codec, and a novel Group Relative Policy Optimization (GRPO) reinforcement‑learning stage to...

How to Design Complex Deep Learning Tensor Pipelines Using Einops with Vision, Attention, and Multimodal Examples
The MarkTechPost tutorial showcases how Einops can express complex tensor transformations for deep‑learning pipelines with concise, readable syntax. It walks through real‑world patterns such as vision patchification, multi‑head attention, and multimodal token packing, demonstrating each operation using rearrange, reduce, repeat,...

Alibaba Open-Sources Zvec: An Embedded Vector Database Bringing SQLite-Like Simplicity and High-Performance On-Device RAG to Edge Applications
Alibaba Tongyi Lab unveiled Zvec, an open‑source, in‑process vector database designed for edge and on‑device retrieval‑augmented generation (RAG) workloads. Marketed as the “SQLite of vector databases,” it runs as a library inside the host application, eliminating the need for external...

A Coding Implementation to Establish Rigorous Prompt Versioning and Regression Testing Workflows for Large Language Models Using MLflow
The tutorial demonstrates how to treat LLM prompts as first‑class, versioned artifacts and apply rigorous regression testing using MLflow. It builds an evaluation pipeline that logs prompt versions, diffs, model outputs, and metrics such as BLEU, ROUGE‑L, and semantic similarity....