

Architecture and Data Trump Size in Small Language Models
In this AI Chitchat episode, we sit down with Fernando from Liquid AI to unpack the rise of small language models (SLMs) and why architecture + data now matters more than raw parameter counts. We cover hybrid transformer/convolutional designs, neural architecture search (NAS), and what it takes to make models smaller, faster, and efficient enough to run locally on consumer GPUs or modern laptops-without sacrificing capability. Fernando shares hard-won lessons from pre-training and post-training: why data quality is king, when optimizers like Adam vs. Muon shine (architecture-dependent!), and practical methods such as layer freezing (Spectrum) and LoRA trade-offs. We dig into distillation (token-prob vs. hidden-state matching), the reality of RLFT for SLMs, and where on-device, agentic AI is heading next: think private, offline assistants that actually manage your email, calendar, research, and more. https://t.co/nv6t6QldiR

Master Byte Pair Encoding in Under 10 Minutes
Let's learn/revise byte pair encoding (BPE) in less than 10 mins! Let's say our corpus consists of these four words. we have appended to all words which says its end of the word. The number denotes the number of times...

Exploring Small Language Models and On‑Device AI
On Monday, 27th October, I will be talking with Fernando from Liquid AI about small language models, model training, efficiency, reinforcement learning, on device agents and more.... Join us. Its live and you can also ask questions :) https://t.co/vmi5TNli5k

ChatGPT Performance Lagging for Users Today
is it just me or chatgpt is super slow for everyone today?
Multilingual YouTube Video on Vibe Coding with Google AI Studio
You can watch my latest youtube video in many languages now! I talk about vibe coding using google ai studio :) https://t.co/6dwo8ArGn3

Massive Funding, yet Just a Fine‑tuning API
Step 1: get $2B in funding Step 2: build a fine tuning api 🤦🏽♂️

Good AI/ML Jobs Are Harder to Find Than Ever
finding a job in ai/ml is hard these days. finding a good job in ai/ml is harder.
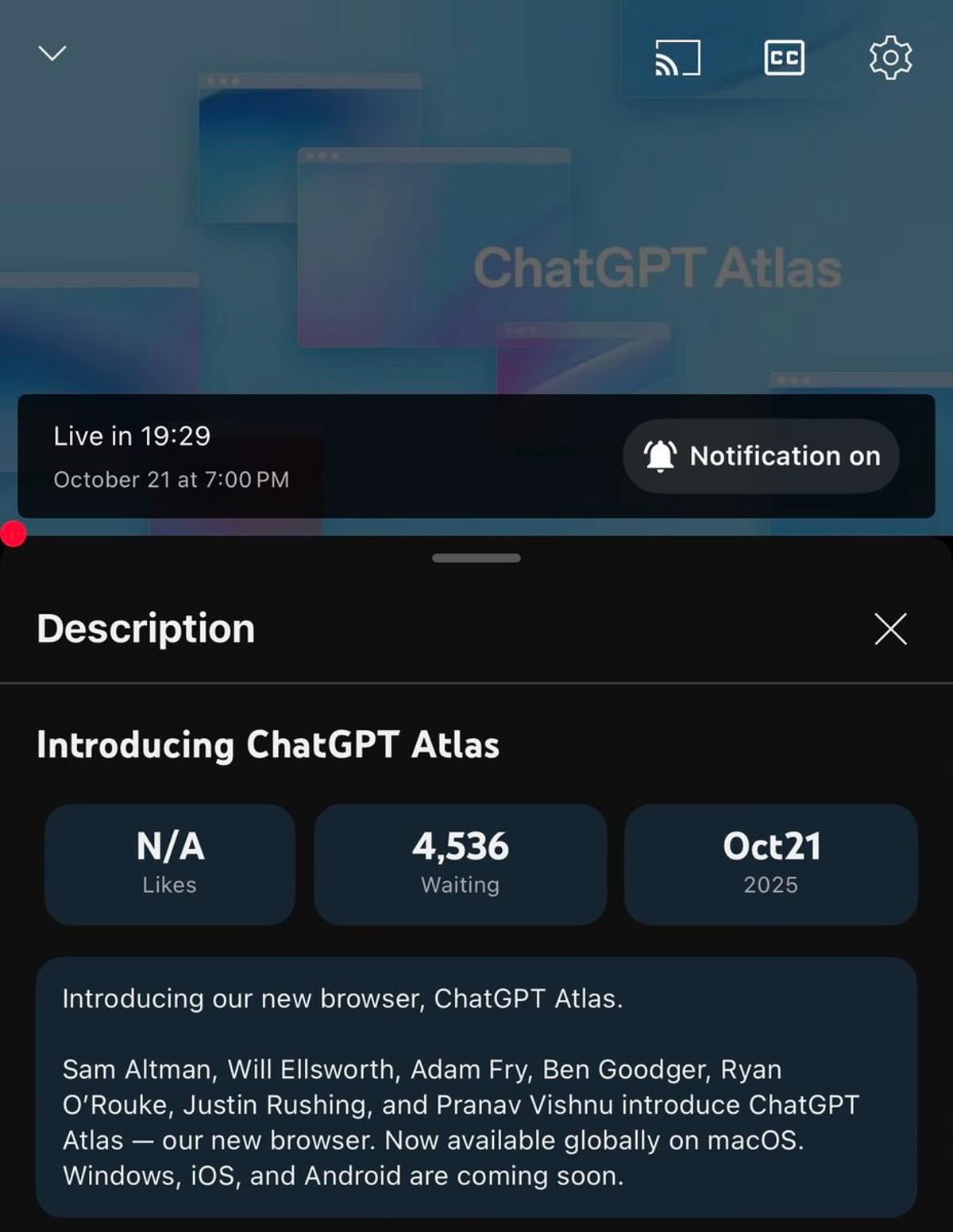
ChatGPT Atlas Launches as macOS Browser
ChatGPT Atlas. Macos browser https://t.co/1jdCCZN5Gl

Defining “Large” In Language Models: GPU Limits
how large the model should be to be called large language model? if it doesnt fit on home gpus, its large?

Reevaluating BERT: Still an LLM?
do we still consider bert as an llm?

Season Finale: Join AI Chat Series Before Nov 15
ill end the first season of ai chit chat series soon. if you want to be a part of it or if you want me ask someone to be a guest, let me know asap :) im fully booked till...

Start Using MLX with Guidance From the MLX King
This is today. Learn how to get started with MLX from the MLX King himself. DON'T MISS IT! https://t.co/F4SbYuS8GN

AutoTrain Paper Reaches Five Citations After Months
Opened google scholar after several months and to my surprise AutoTrain paper has 5 citations now 🤩 https://t.co/zjuZnIMIwb

NanoChat Code Sparks Fresh Look at LLM Theory
Karpathy’s nanochat codebase motivated me to revise llm theory

Found a Goldmine for Scalable Search and RAG
I've been looking for how search and RAG can be done on large scale and actual data, and there's just toy examples everywhere I look. Not just some pdfs or a website with everything in context, but actual search, retrieval,...

Seeking Comparison: Nvidia Spark Vs. M4 Max
did anyone compare nvidia spark with m4 max?

From Kaggle Grandmaster to Meta Engineer
From Kaggle Grandmaster to Meta Engineer (w/ Andrey Lukyanenko) https://t.co/Z7ptCO9VH6
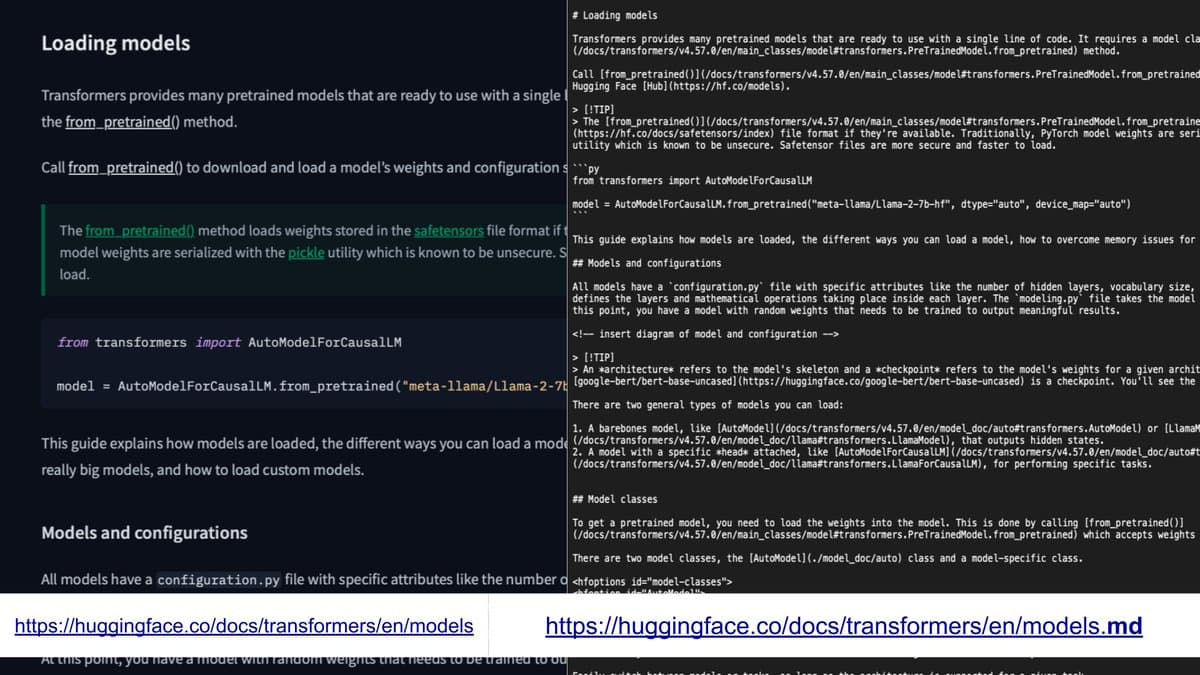
Add .md to URLs for Instant Markdown Access
cool new feature from huggingface. appending ".md" to any docs url will now give you the markdown which can be used as context for your favorite llm or more 🚀 https://t.co/BlRVWjRp4R