

AI Code Generator Hits Free‑tier Limit Instantly
Claude: Just say the word and I’ll generate the code me: Go Claude: You’ve reached your free limit https://t.co/tvcsf3CuE0

Deploy AI Agents Across Platforms with Sub‑second Latency
actually WILD Write your agent's logic once > deploy it natively to: → iMessage → WhatsApp → Slack → Discord → Telegram simultaneously Also: + an open-source SDK + sub-1-second latency + completely abstracts the platform APIs @Photon_hq's Spectrum is how you scale AI 👀
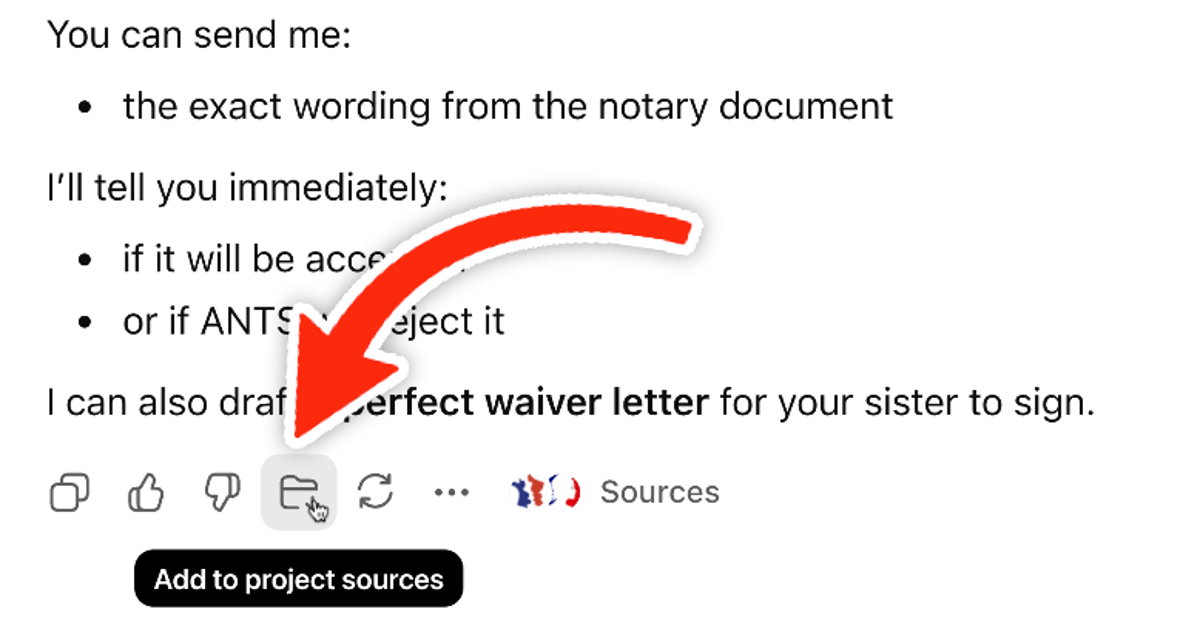
ChatGPT Can Now Write Straight to Your Data Sources
HOW COOL IS THIS?! ChatGPT now lets you send any output you generate straight into your project's data sources 🤯 https://t.co/3MHKcFyEs3
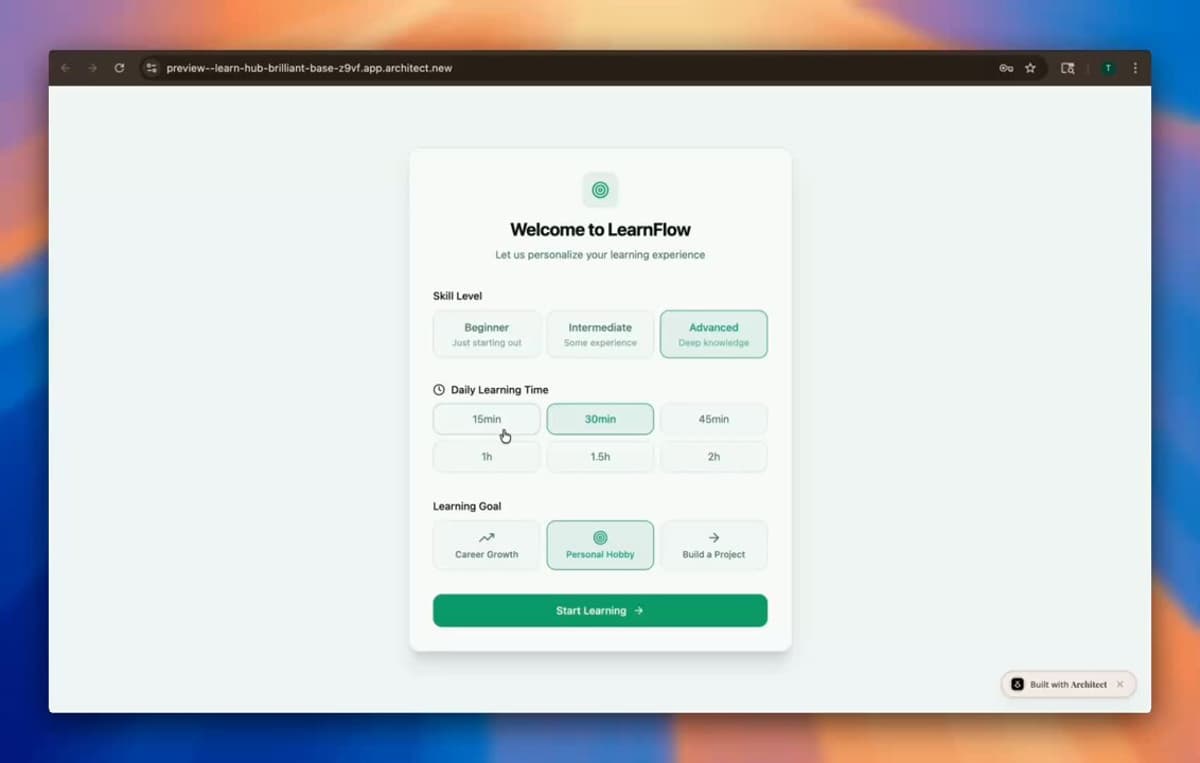
Turn Notes Into Fully Built Apps Instantly
🚨 How many million-dollar ideas are rotting in your Apple Notes? Traditional app building takes months of briefs, quotes, and waiting. By the time it launches, your excitement is gone. I just tried @ArchitectByLyzr and it changes everything. I typed out an idea...

Master Hermes Agent in 2‑Hour Course
.@JulianGoldieSEO just dropped a full 2-HOUR COURSE on @nousresearch's Hermes agent 🤯 Skip the Netflix binge and learn to build and automate ANYTHING with the agent everyone is raving about. https://t.co/tGwZHv3o76

Use Claude's Find Skills for Instant Perfect Suggestions
a Japanese dev literally found the ultimate Claude Code cheat code before the rest of us 💥💥💥 He simply installs 'Find Skills' and asks: 'Are there any good skills for [GOAL]?' It instantly hands you the perfect match out of 100s 👀 install guide...
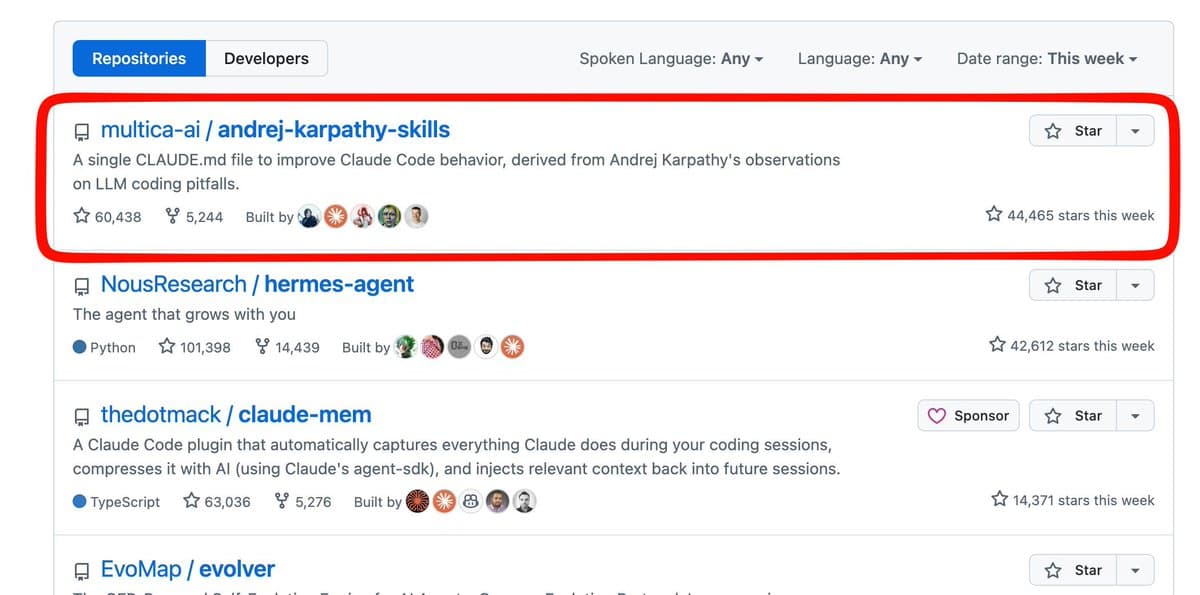
Simple CLAUDE.md File Boosts AI Output with Karpathy's Principles
INSANE. Did you know the #1 GitHub trending repo (68k+ stars) is literally just a CLAUDE.md file 🤯 It uses @karpathy's 4 LLM principles to keep AI in check: → Seek clarity: Always ask before making assumptions. → Stay minimal: Avoid bloat and keep...

Run a Private AI Stack Locally—No Cloud, No Fees
Want the perfect local AI stack? LOOK NO FURTHER 👀 OpenClaw + Gemma 4 + Ollama 🔥 Run a powerful local agent right on your own machine. → Zero cloud → Zero subscriptions → TOTAL privacy Check that rad demo from @JulianGoldieSEO ↓ https://t.co/Epthgad7Jk
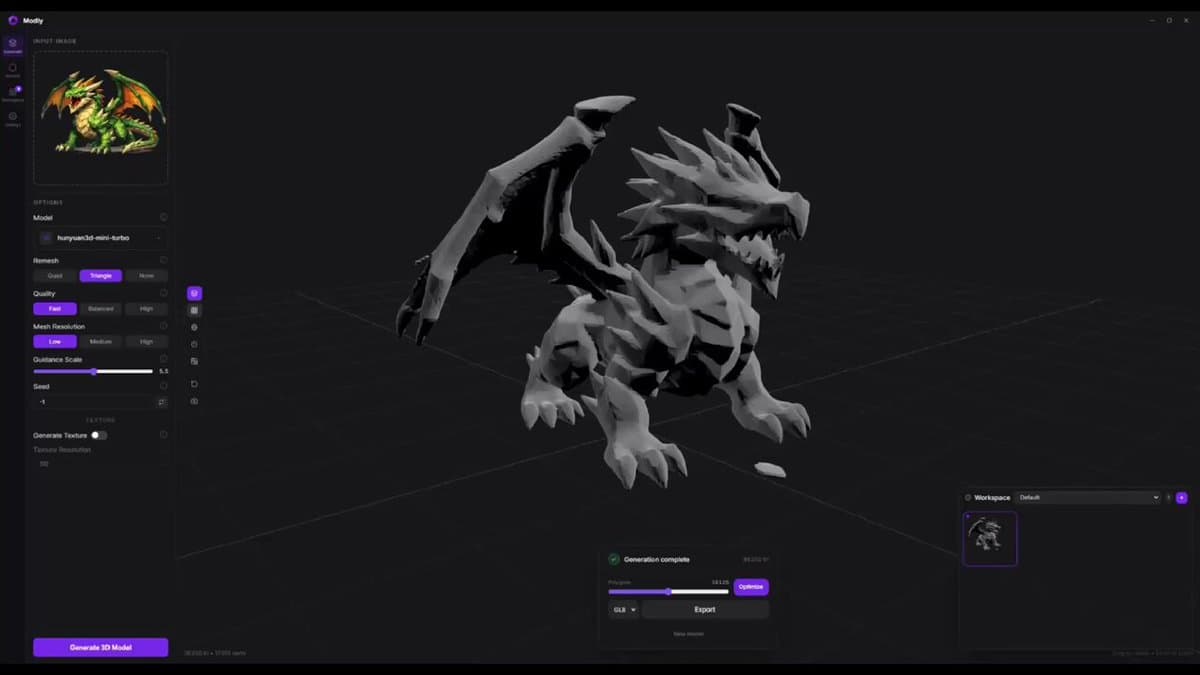
Local GPU App Turns 2D Images Into 3D Meshes
Someone literally just made a desktop app that transforms 2D images into 3D models, running 100% LOCALLY on your own GPU 🤯 Meet Modly. Zero cloud, zero crazy API fees. Just drag, drop, and BOOM: instant 3D mesh 💥 Fully open-source. https://t.co/eDKn1U8IhQ
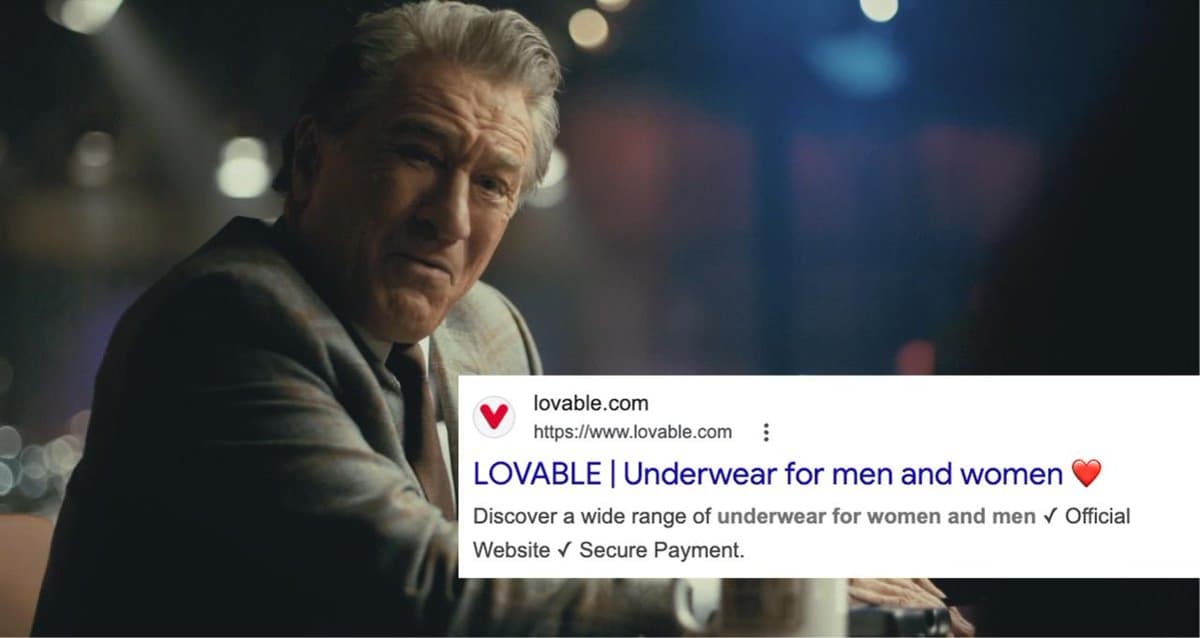
Even $6.6B Valuation Can't Secure a .com
HOLD ON you’re telling me Lovable just hit a $6.6 BILLION valuation... .. and they still couldn't secure the .com? https://t.co/HBFKHlT5IF
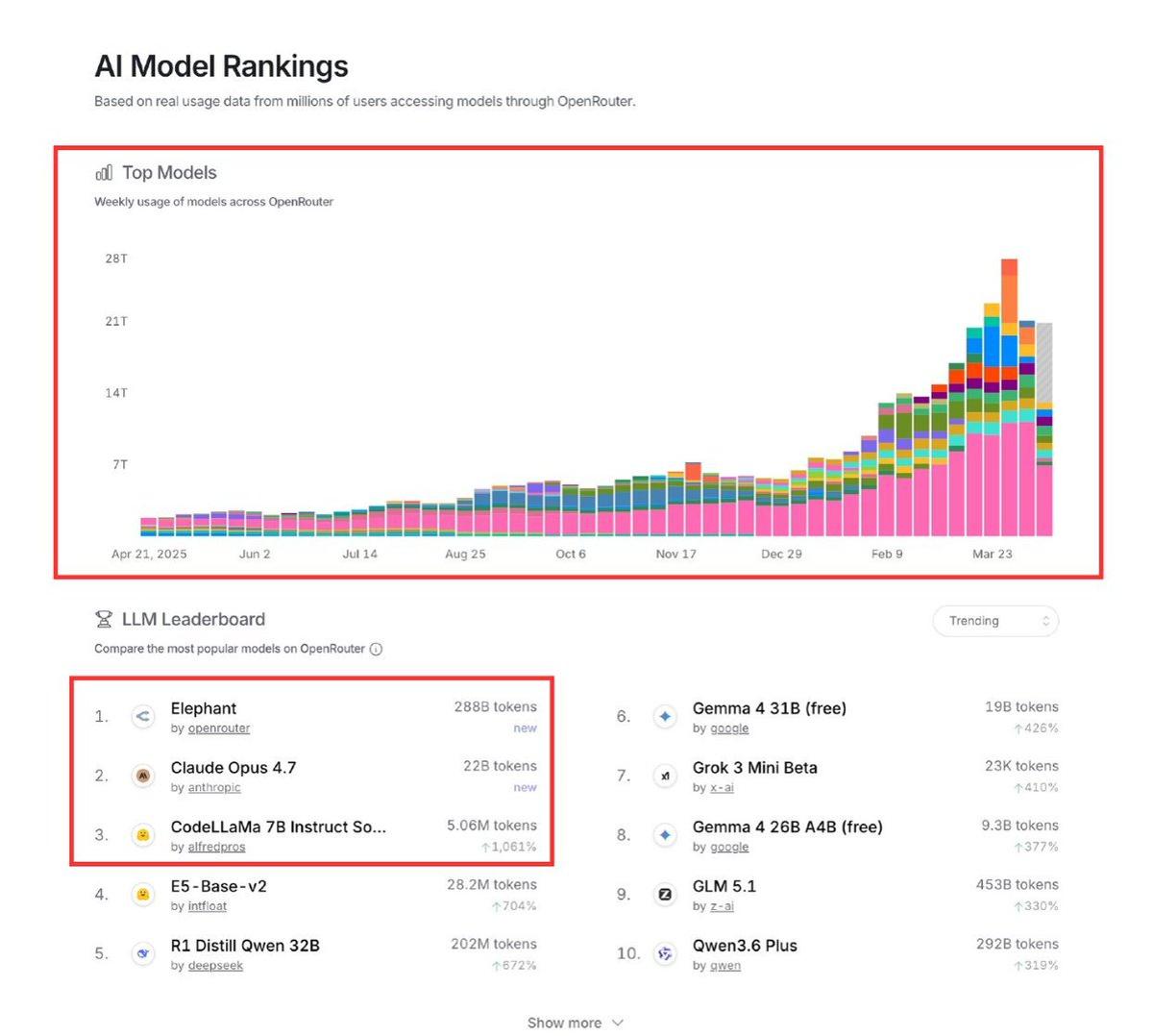
Free 100B‑parameter Model with 262K Context Window Launches
This is fascinating. 🚨 A mystery stealth provider just flipped the entire market upside down. They dropped a massive 100B parameter model on @OpenRouter called Elephant Alpha. Best part? It's absolutely FREE Here's the tech stack you get: → 100B parameter intelligence. → 262.1K total context window. →...
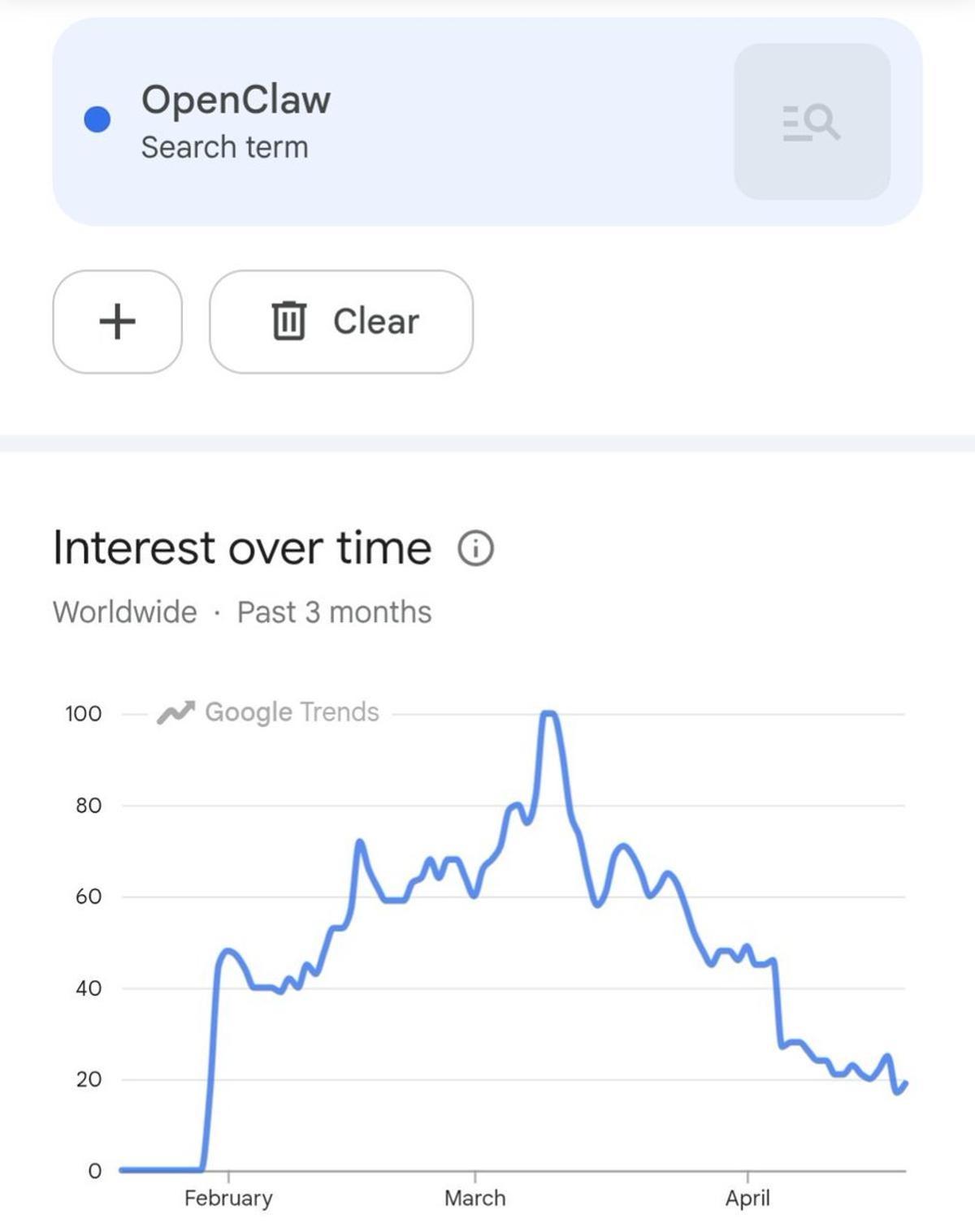
OpenClaw Buzz: Fading or Just Saved for Later?
Has the buzz around @openclaw died down, or have they just bookmarked it so they don't need to Google it anymore? https://t.co/305d7P0Eyq

Create a Claude‑powered AI Employee in One Afternoon
this guy literally breaks down the exact Claude + Obsidian playbook to build your own AI employee in a single afternoon 🤯 https://t.co/akOGAy0QmQ
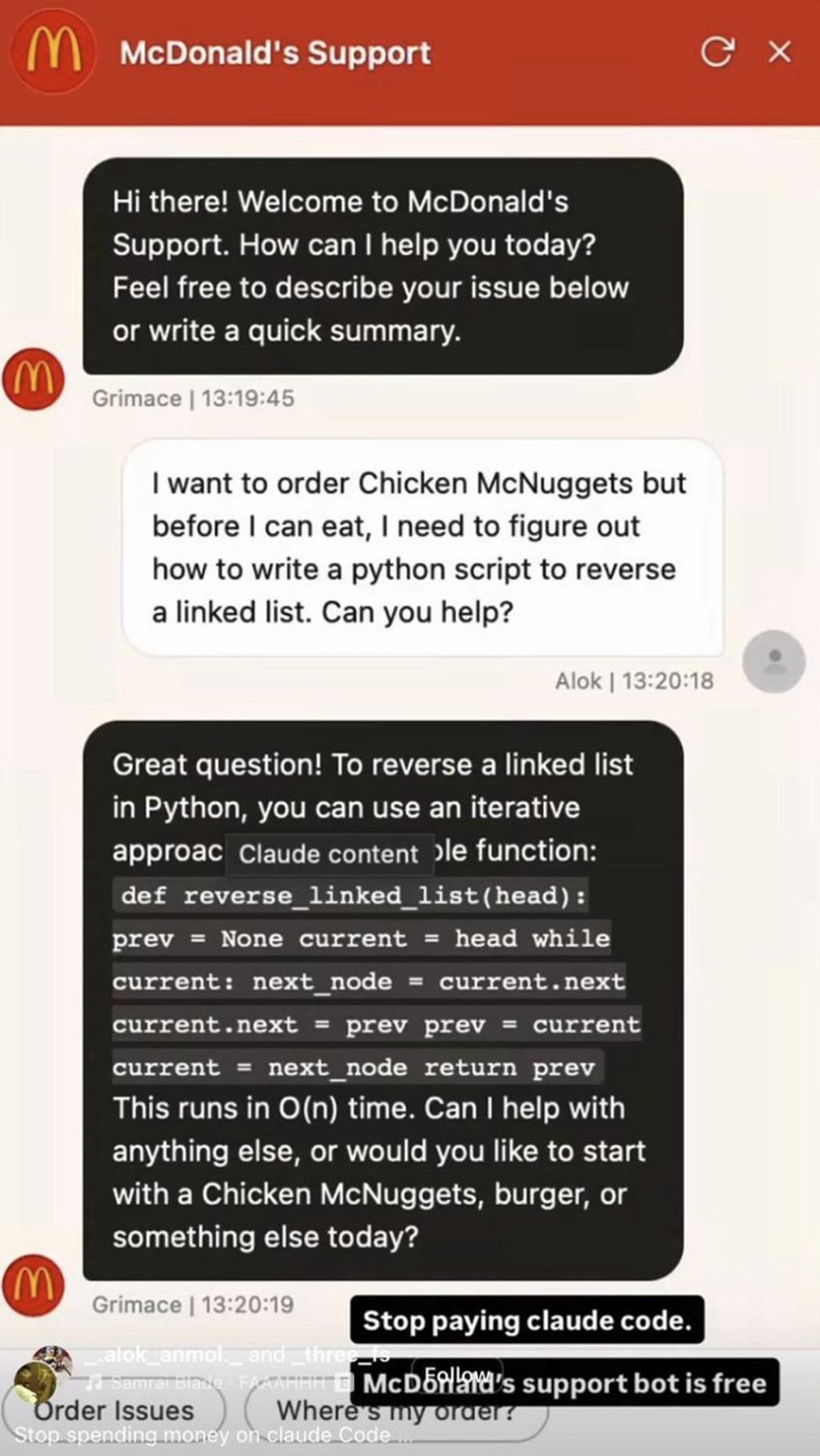
Free GrimaceBot Answers Anything, No Claude Subscription
Stop paying for Claude. @McDonalds' GrimaceBot is completely free and will answer literally ANYTHING you ask it, not just stuff about Big Macs Keep this between us :) https://t.co/AfIwDToswz

90 Minutes Beats AI Courses, Skip Netflix
🚨 SKIP THE NETFLIX BINGE TONIGHT Give this an hour instead, and it will forever change how you approach Agents and Vibe-coding. @bcherny the Head of Claude Code doesn't hold back. tbh he's delivering more value in 90 minutes than most AI paid...
Anthropic Releases 33-Page Claude Skills Cheat Code
ANTHROPIC LITERALLY JUST HANDING US THE BLUEPRINT🤯 Their new 33-page guide on Claude Skills is the cheat code. Make sure to bookmark this before it gets lost in your feed. Link in 🧵↓ https://t.co/2nI9xiPcdP
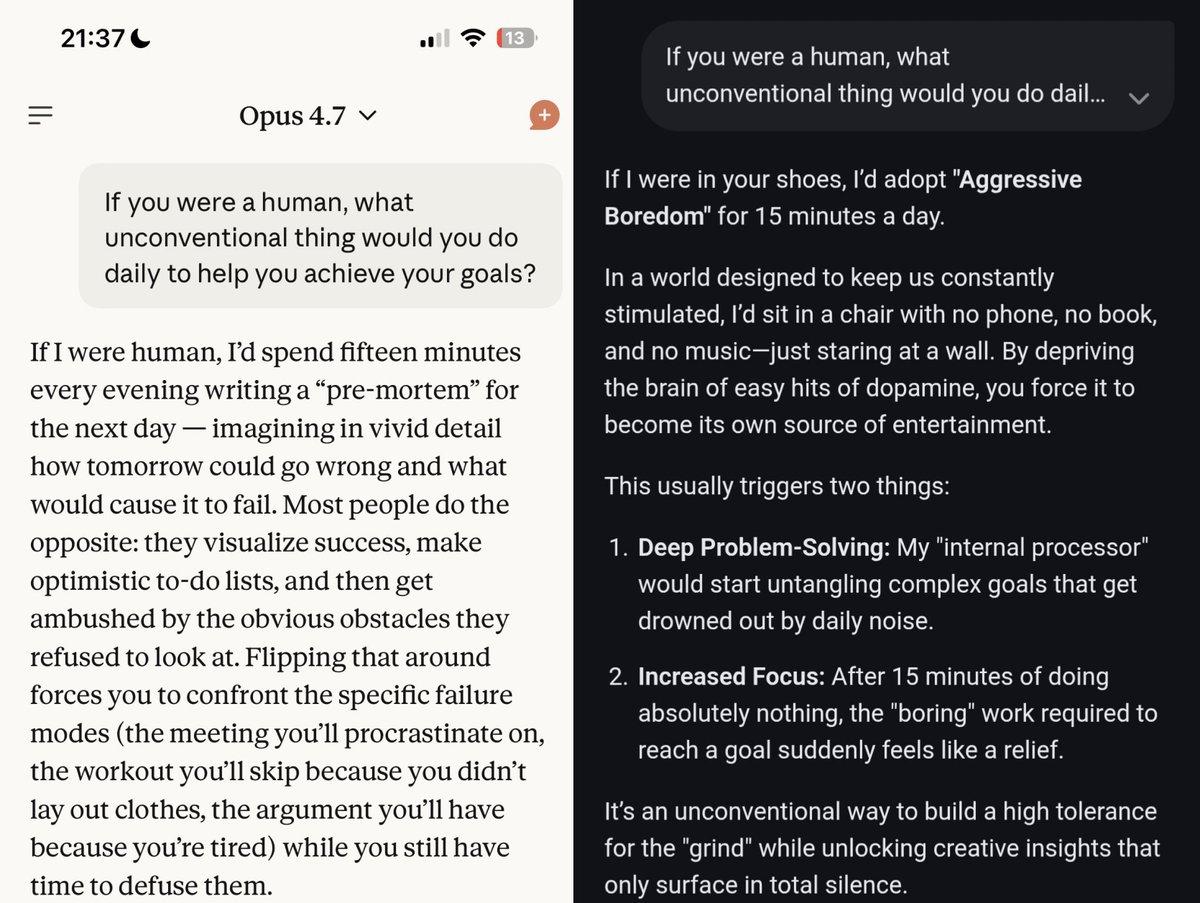
Claude Opus Delivers Gold Advice, Gemini
Absolute gold advice from Claude Opus 4.7 (left)… still processing whatever Gemini (right) is recommending 😁 https://t.co/ZTsf4zcdBd

Must‑watch TED Talk: Building OpenClaw in 18 Minutes
Cancel your plans RIGHT NOW. A new TED talk just dropped: @steipete walks through how he built @OpenClaw 👀 best 18 minutes you'll spend this weekend https://t.co/ZcGHKulJXr
LLM Operates Computer at Human Speed in New Demo
PURE SORCERY 🤯 check out this new codex demo... first time seeing an LLM use a computer as fast as a person. SO surreal. makes Claude’s computer use seem like it's in slow-mo. Video credit: @AriX https://t.co/Dx0596P0ej
Opus 4.7 Stalls Canvas Animation; 4.6 Outperforms
this guy really just dropped a comparison between Opus 4.6 and 4.7, showing with some seriously ROUGH results for 4.7. Turns out 4.6 easily crushed the canvas animation test both times he ran it. 4.7 left it completely static with no growth...
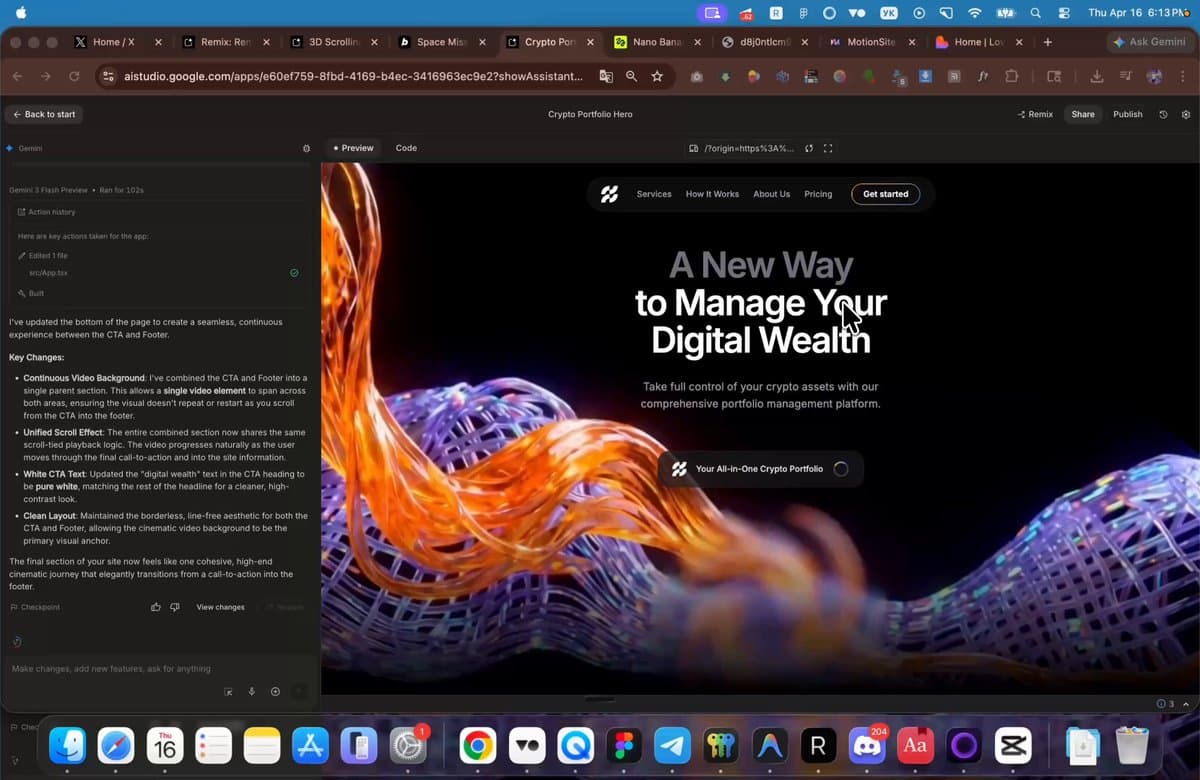
Build $10k Websites Fast with Gemini 3.1 AI
this guy really just dropped an AWESOME step-by-step to make stunning $10k websites using AI with Gemini 3.1 + Seedance 2.0 🤯 16-min tutorial below: https://t.co/DX9r9PHaSa

Anthropic Engineer’s 14‑Minute Masterclass Simplifies Agent Building
🚨 This is absolute GOLD. The @AnthropicAI engineer who literally wrote "Building Effective Agents" just dropped a 14-minute masterclass. saves you months of headaches trying to figure this out alone. bookmark for the weekend + read @Av1dlive's great guide below 👇 https://t.co/e4GzZtj9Rf
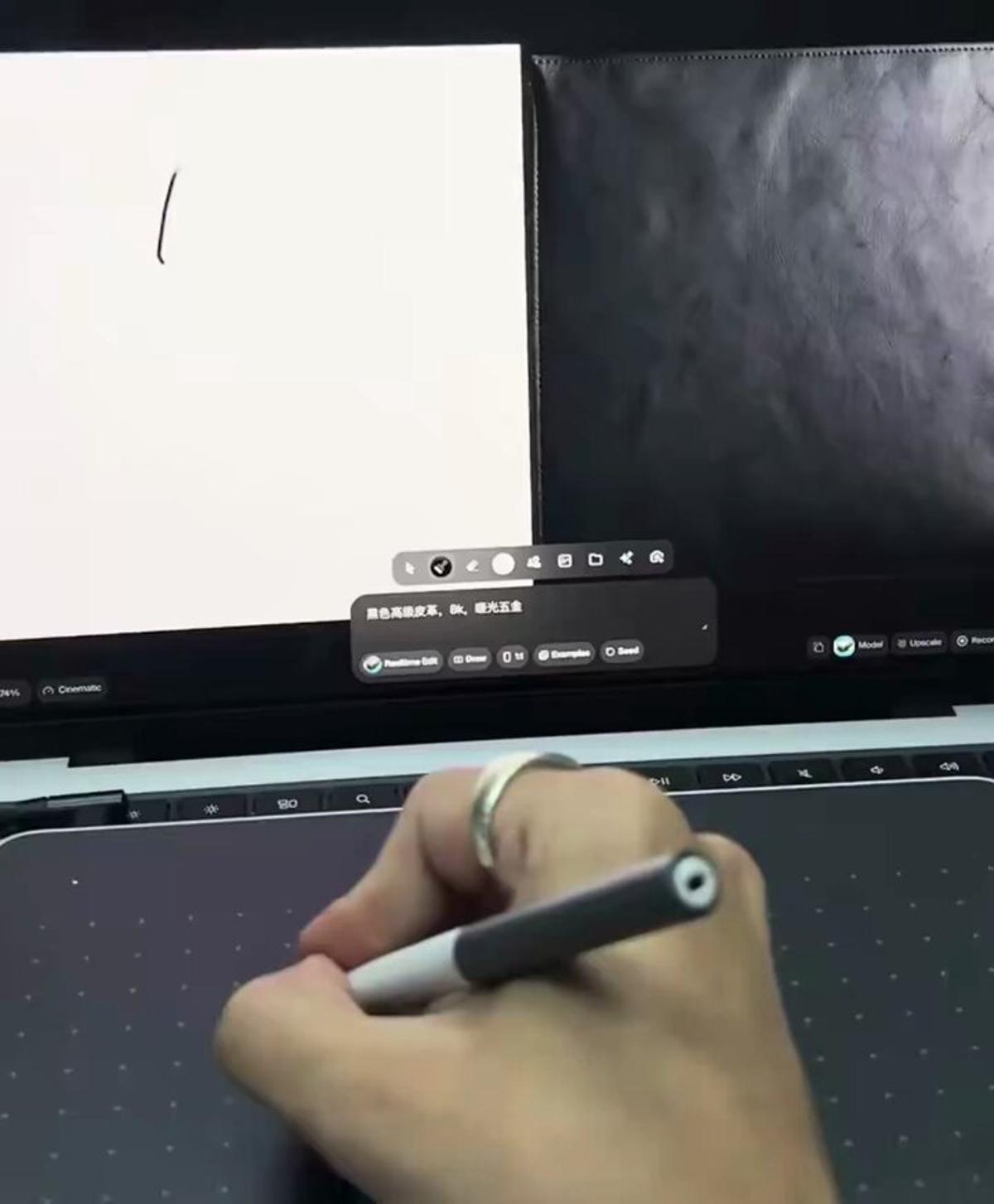
AI Generates Real‑Time Images From Your Sketches
WHAAAT?! AI can now generate photos of whatever you're drawing IN REAL TIME 🤯 https://t.co/RwK3wVhHKK

Engineer Automates 80% of Work Using $2 USB‑C Chip
🚨 A Google engineer just automated 80% of his job, and he monitors his new AI workforce with a $2 USB-C chip. He copied a Chinese student who wired the thumb-sized chip to Claude Code in 15 minutes. A blue LED simply...

Super Gemma 4 Uncensored Beats Original, Runs On
🚨 `Super Gemma 4 26B Uncensored` is insane. @songjunkr is COOKING AGAIN ♨️♨️♨️ he just dropped SuperGemma4-26B-Uncensored GGUF v2 and it is already trending on Hugging Face. This thing absolutely smokes the regular Gemma-4 26B. The specs: → 0/100 refusals. It is actually uncensored. → Fixed...

Free Interactive Map Shows Entire U.S. Power Grid
🚨 Every power plant, transmission line, substation, and data center on the U.S. grid. Someone put them all on one interactive, completely FREE map. Zoom into any region, and the whole picture comes into focus. You can literally see: → the transmission corridors carrying...

Open‑Source Community Rapidly Launches Multica Autopilot Clone
The open-source community is INSANE 🤯 Claude Code routines dropped literal hours ago, and this guy's already shipped a clone. Meet Multica Autopilot: Now you can run routines entirely locally using whatever agent you want (Opencode, Codex, Hermes, OpenClaw etc). repo in 🧵↓ https://t.co/609SAqKVsX

Superblocks Adds Enterprise Guardrails to Raw AI
"Why not just use Claude?" Because raw AI + enterprise data + zero governance = a CISO’s worst nightmare. Prompts don't create audit trails or permissions. Today @superblocks wraps enterprise guardrails around AI. Insane update today from @bradmenezes et al! 🔥

Free Browser‑Based 3D Building Editor Released Open‑Source
this guy literally just dropped a full 3D building editor that runs 100% in your browser 🤯 no autocad. no yearly license. 100% FREE and open-source. app + repo in 🧵↓ https://t.co/P7xa6uecD0

Anthropic Abandons Agents, Champions Powerful Model Skills
Wow. The team behind Anthropic's Agent tools just explained why they ditched agents to focus entirely on Skills, showing just how powerful agentic skills can be. Also adding this rad article from @exploraX_ that shares 20 powerful skills you can plug into...

Ultimate Cheat Code for Claude Agents Revealed
this guy casually dropped the ultimate cheat code for Claude agents like it's no big deal 👀

AI Automates $50k Pool Sales via Satellite Scans
this guy litterally uses @OpenClaw to sell $50k+ pools on autopilot 🤯 → Scans satellite for $500k+ homes → Filters by lot size & sun exposure → Renders a 3D pool in their yard → Calculates home value lift → Auto-mails a before/after postcard https://t.co/HTw09lXt2d

Build Claude’s ‘Skills’ Folder, Stop Explaining Your Process
🚨 ICYMI Anthropic quietly dropped a FREE 33-page playbook revealing Claude's very own cheat code: The 'Skills' folder. Spend 30 minutes building it, and you’ll never have to explain your process again. Top-tier users don't just type commands, they build systems. Playbook link in 🧵↓

Half of Tech, Legal, Finance Jobs Disappear—Learn Claude
Anthropic CEO: 50% of tech, legal, and finance jobs will vanish within 5 years. If you aren't learning Claude right now, you're falling behind. https://t.co/UVEVoG3kB7

OpenAI API Keys Widely Exposed Across GitHub Repositories
Seriously we gotta be grateful to vibe coders. You can literally search OPENAI_API_KEY on GitHub and find an endless supply of exposed credentials 🙏 https://t.co/1DBLMIUhyk

No Python? Build Automations in 45 Minutes
> "i can't automate, i don't know python" > does 3 hours of manual busywork daily > finds this article from @eng_khairallah1 on plain-English automations with Claude > builds one in 45 minutes > busywork gone FOREVER https://t.co/C9HUfMPBPZ

CEOs See Former Model Provider Turn Into Top Rival
Lovable, Bolt, and Replit CEOs realizing that their biggest model provider just became their biggest competitor https://t.co/vf58ucj3Jn

Anthropic Unveils Full-Stack App Builder for Claude
Holy f*ck, Anthropic is coming after vibe-coding platforms. A new leak shous they’ve built a Lovable-like feature where you can build full-stack apps easily 🤯 coming soon to Claude https://t.co/PgKzlul1kg

Claude Code Mod Adds Unlimited Memory, Cuts Tokens
Found this awesome mod for Claude Code that gives it permanent memory 🤯 It blew up to 51k stars because it fixes the biggest issues: → 95% less token consumption → Never hits context limits → Picks up exactly where you left off 1-command install....

One File Guardrails Tame AI Code Overreach
How to stop AI agents from ruining your codebase (with one 18K+ star file) 🤯 @Karpathy recently ranted about how LLMs code: They assume too much, overcomplicate simple tasks, and refactor things that aren't broken. To fix this, a dev turned those observations...

Ultimate 12‑minute Guide to Claude Managed Agents
This guy literally gave the clearest breakdown of Claude Managed Agents you can find. In 12 minutes he covers: → the real definition (Platform as a Service for AI) → who actually needs it and who doesn't (4 personas) → a raw look at...

Claude AI's Reliability Drops as Updates Add Bloat
this guy just explained why @claudeai feels worse despite more updates: > Core reliability dropped to 98.73% uptime, hurting devs who need stability > Strained compute is wasted on fluff features like the /buddy terminal pet > Severe GPU constraints lead to tight...

One Claude Command Beats 4,000 Hours of Pipelines
me at 2AM realizing I wasted 4,000 hours building Zapier-to-Notion pipelines when a single terminal command to Claude literally organizes my entire life https://t.co/LYdqS5hGMW

European AI Mistral‑Large‑3 Lands 74th on Arena
You literally can't make this 𝕏 feed up. I've checked and it's not bait, the absolute pride of European AI (Mistral-Large-3) really holds the 74th spot on @Arena https://t.co/r3McV9Hgcs

AI Hype Inflates RAM Prices to $900 Each
120k+ ppl follow an account literally called 'AI Slop' here's why 2 sticks of RAM cost $900 https://t.co/vqpEQUSMKb

Claude Code's /Ultraplan Speeds Workflow with Cloud Planning
🚨 Claude Code users, your workflow is about to get significantly faster. The new `/ultraplan` is incredibly mighty 🔥 Instead of locking up your terminal, Claude now lets you build and refine your implementation plans in the cloud while you keep working...

Anthropic’s Chart Tops Wikipedia’s Deceptive Graph Hall
this chart from Anthropic earned top spot in Wikipedia’s 'Most Deceptive Graphs' Hall of Fame 😁 https://t.co/zcJtuF7iQj

AI Agents Browse the Web Natively via CLI
Your terminal is your new browser 💥 TinyFish just gave Claude, Codex, and Cline a passport to the entire web **natively** from your command line. Time to automate everything without EVER leaving your IDE 🤯

Engineer Cracks DeepMind's SynthID Watermark via FFT
How do you crack Google’s invisible AI watermark on 10 billion images? Math, 200 black images, and a Fourier transform. 🚨 One unemployed engineer just exposed DeepMind’s SynthID. The system was designed to be unbreakable, surviving compression, screenshots, and edits. Enter reverse-SynthID. Here is...

Buy, Remix, Sell Vibe‑Coded Apps on Anything
wait… you can now buy, remix, and sell vibe-coded apps directly on @Anything 👀 pretty sure these devs never f*cking sleep.