

Governments Will Seize Near‑AGI Labs as Duty
Current events are just a prelude. If any AI lab gets close to AGI of course the government would take control of it. You could even argue a government would be failing to do its job if it didn’t… Thoughts?

AI Drives Intelligence Cost to Zero, Human Cognition Devalues
This is an interesting scenario like AI 2027 and in line with my book https://t.co/R8VoeGs69Q However one thing under appreciated is that the cost of useful intelligence is going to 0 & value of human cognition is going negative https://t.co/s2JNhGmxyd

AI-to-AI Speed Gives Massive Competitive Edge
Something folk haven't figured out: 15,000 tokens/second speed and million token context windows aren't for humans They are for the AIs to talk to each other & coordinate faster than we ever could Not just a bit faster and better Orders of magnitude That's your...

Experience Instant Intelligence with Taalas Inc’s Chatbot
You all have to try the @taalas_inc chatbot, I guarantee you'll find it crazy. Instant intelligence is a heck of a thing https://t.co/RzACWWxJGP https://t.co/F6OeYDxQXm

Elegant Ideas, Not Massive GPUs, Drive Breakthroughs
Folk don’t realise that the biggest breakthroughs won’t be millions of GPUs doing complex stuff but millions of tokens figuring out beautiful, elegant stuff Science & more is marred by model building and complexity because we rewarded it over elegance &...

Grok 4.20 Delivers Fast, Accurate, Pleasant AI Experience
My initial take on @Grok 4.20 is that it's very.. pleasant? Fast and accurate responses, handles some advanced stuff very well, nice balance of attitude. I feel it has more horsepower than currently shown though, perhaps that scales with more than 4...

GPT‑5.2 Pro Sets New Speed Record
New record for GPT 5.2 Pro ⏲️ Wonder when this will be days 🤔 https://t.co/scuvbDEDrr

II Agent Launches Manga Mode, Eyeing Full Media Expansion
Manga mode now in II Agent Soon manhwa, manhua, then onto anime, donghua & whatever else you can imagine 🤷🏾 Idk if we need spaghetti workflows in future, just teams of agents working with teams of humans to make their imaginations...
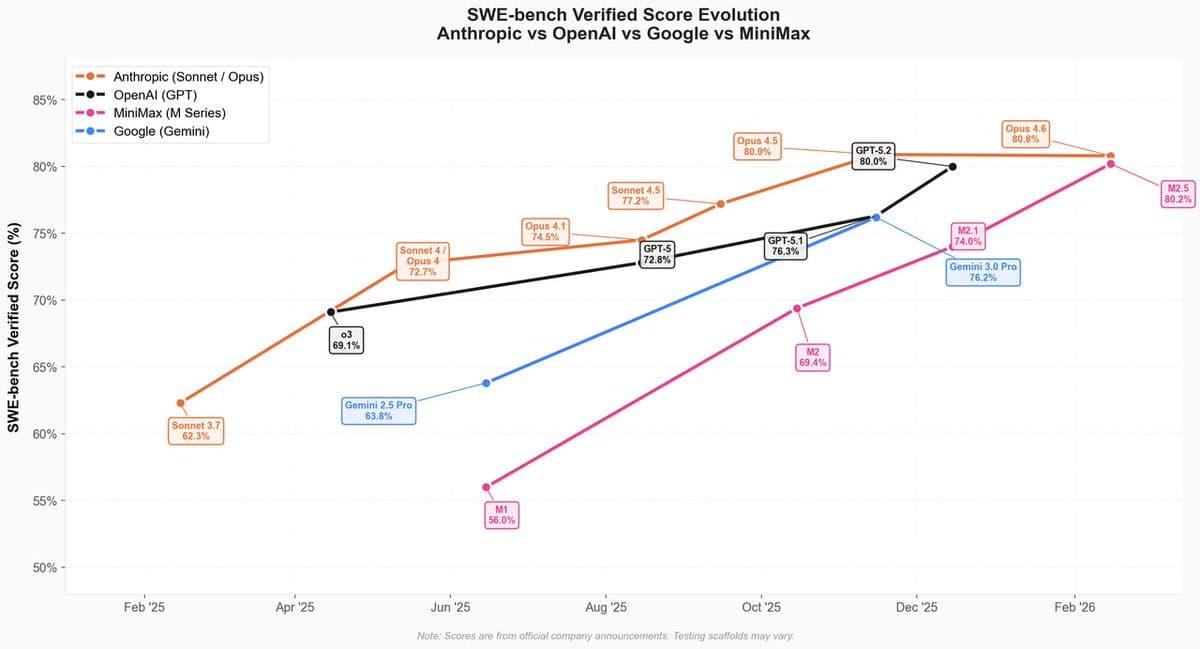
MiniMax AI Bridges Open-Source Frontier, Drives Zero-Cost Optimization
Congratulations to @MiniMax_AI for closing the closed - open source frontier AI gap for the first time. All models will saturate benchmarks & have amazing daily usage soon so then it becomes about optimisation even as the performance per token ramps. Intelligent...

AI Firms Need Publicly Updated Alignment Documentation
Which AI companies have a clear, up to date document on their approach to/latest thinking alignment? It seems this should be standard by anyone building AGI?

AI Excels at Constructive Theories, Struggles with Principles
AI will massively outperform humans on constructive theories It is still pretty terrible at theories of principle

II-Agent Delivers Private, Open-Source AI with Agent Boost
Congrats to @ManusAI team on their way to @metaai I wonder if @Microsoft or similar will snap up @genspark_ai… If you want to try the best open source version fully private it’s II-Agent by @ii_posts Lots more features to come, agents...

Let AI Spark Intuition, Not Just Automate Proofs
I find automated math proving with AI not hugely interesting What is most interesting is how we can leverage AI to enable more intuition and inspiration like Ramanujan Save the proofs for later, dare to explore and do what we do best...

GPT 5.2 Pro's New Thinking Bar Limited to Web
The "thinking" bar for GPT 5.2 Pro has got a lot better, you can see it looking at the pages etc of what goes in, interrupt it etc However it remains on the web version only (along with the ability to...

Self‑Published ‘The Last Economy’ Tops AI Bestseller List
The Last Economy is number 1 on Amazon's Best Sellers for AI with a pretty good ratings ✍️ No publisher or big campaign, also available for free on the website and paperback just dropped 📖 Thank you all for the support &...

3 Billion Active Parameters Are Sufficient
3b (active) parameters is all you need

NousResearch Launches 3B Model Runnable on MacBook Air
Massive achievement by @NousResearch To make this clear: this is actually a 3b active parameter model that works on any new MacBook Air/Mini that would be #2 on Putnam, which is harder than IMO Now think of all the tasks that...

EU Should Create Open‑source AI for Transparent Governance
EU countries should get together to build an advisory AI that should run the EU with all decisions being transparent and participatory. This should be a fully open source, open data stack with all inputs also available so you can run...

MistralAI Hits 68% on 24
68% on SWE-Bench Verified on just 24b! Laptop class 72.2% on 124b 👏 Great job @MistralAI team, looking forward to trying it out https://t.co/I9VlzwMnwB

Three Years In: Imagining ChatGPT's Next Evolution
3 year anniversary of ChatGPT Where will we be 3 years from now

Video Pixel Generation Nears Solution with New Models
So many amazing new video models coming, we are heading next year to video pixel generation being “solved”

Claude Opus 4.5 Gains Math Usability, Scores 21%
Claude Opus 4.5 is the first Claude I think is reasonably usable for decent math work (Claude interface is great for iterating minus the timeouts & mobile slowdowns) The big thing here though that I've noted using Opus 4.5 usage is...

TPUs Outperform NVIDIA Chips in Large‑scale 8‑bit Training Stability
@zephyr_z9 TPUs are much more stable on 8 bit training (aqt etc) than NVIDIA chips at massive scale Previous gen was a bit sensitive on topology but looks like less of an issue for ironwood

TPU Scarcity and Memory Lag Behind A100s, Prompting Rework
@_The_Prophet__ TPUs had low availability for ages and also low memory relatively on the v6e especially versus the hoppers working pretty much out of the box similar to a100s Grace Blackwell is the next thing that needs reworking so there is...

TPUs Offer More Stable Training Than CUDA on Large Batches
@_The_Prophet__ TPUs have been more stable for training than CUDA equivalents for a couple of years now, especially on large batch sizes XLA is pretty good now! For inference it makes even less of a difference (We previously trained sota models on thousands...

Claude's iOS App Still Drains Battery on Long Replies
Lots of improvements! Claude still crawls and burns battery on mobile iOS app when doing long replies, very frustrating

Humans Serve as AGI’s Biological Bootloader
Humanity as the biological bootloader of AGI

Grok Fast 4.1 Outperforms Agents 10‑20× Faster
This looks crazy good, will run evals now on our sota II-Agent The cost and speed of grok fast 4.1 are way higher than comparable agentic AI models, even top notch ones from the numbers here - 10-20x better in some...

Generative AI Set to Transform Music’s Future
Music team @StabilityAI is amazing, was a privilege to build it up and see how they came together It’ll be super interesting to see how music evolves with generative AI from technology to form to expression itself
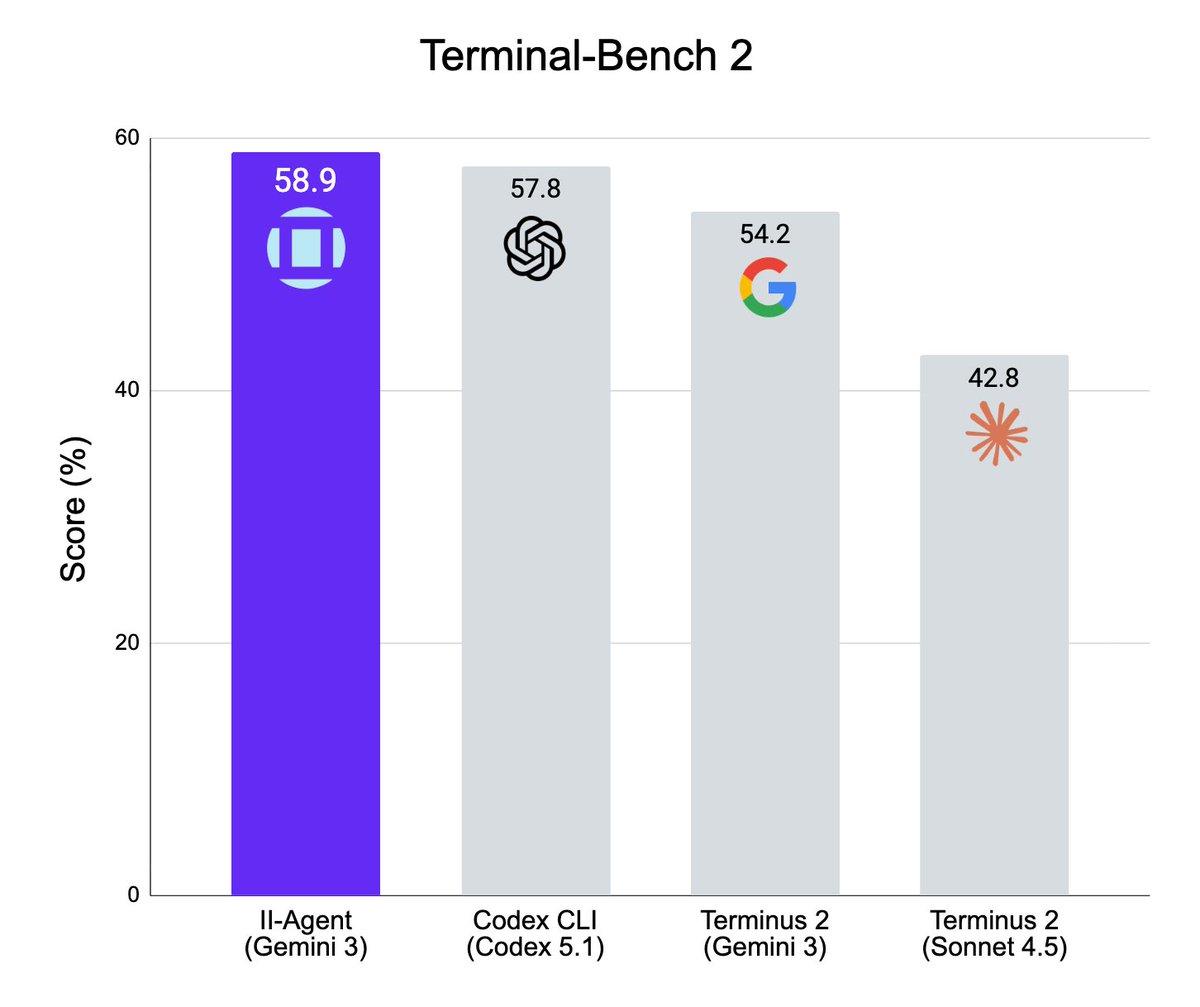
Open‑Source II Agent Hits State‑of‑the‑Art Benchmark
Buried the lede a bit but our fully open source II Agent framework is now state of the art in Terminal Bench 2 using just Gemini 3! Congrats to team for amazing work & more coming the pipeline The best agents will...

Gemini 3 Pro Delivers More Intelligence per Token
The most interesting thing testing Gemini 3 Pro has been how *efficient* it is from tokens to tool calls The intelligence per token of models is increasingly rapidly even as prices fall, its quite something

Gabecube Hardware Rivals AMD Ryzen, Supports 128GB RAM for LLMs
Just call it the Gabecube Hardware looks to be around AMD Ryzen Al Max+ 395 (strix halo) level Would be cool if RAM was upgradeable, can run 128 Gb for LLMs (see @FrameworkPuter Desktop)

Can AI Achieve Continuous Learning in Two Years?
Will continuous learning for AI models be solved within 2 years

AI Lacks Built‑In Morals; Time for Asimov’s Laws
No current AI systems have morals explicitly encoded into them at pretraining time. At the very least they should have Asimov's laws of robotics eh

Open Stack Enables Sovereign AI's State‑of‑the‑Art Future
Proud of the @ii_posts team who have made a fully open stack for our agentic future that is truly state of the art, from datasets to models to agents We have done 0 press on this preferring to build & soon...

Even Billion‑Dollar Labs Stumble Against Kimi Moonshot
Can you imagine being a "frontier" lab that's raised like a billion dollars and now you can't release your latest model because it can't beat @Kimi_Moonshot ? 🗻 Sota can be a bitch if thats your target

Constraints Fuel Chinese AI: 100× Compute Savings
Necessity is the mother of invention Also - training optimally on small amounts of chips with focus on data means the Chinese models take 10-100x less compute to run as well & have that cost advantage $150/mGPT 4.5 vs $0.5/m DeepSeek v3...

Stability AI Wins UK Trial, Eyes US Lawsuit Battle
Can remember how surprised we were to be sued for $1.8 trillion by Getty a few years back when leading Stability AI Good to see Stability AI largely win this case in the UK, now onto the USA portion I'd agree with...

Pakistan Pursues Sovereign AI Powered by Blockchain
Was a pleasure meeting with Pakistan Prime Minister @CMShehbaz and Minister of State @Bilalbinsaqib & co Look forward to helping Pakistan have Sovereign AI, providing aligned universal AI to all citizens coordinated by blockchain Huge potential for a true leapfrog moment 🇵🇰🚀

Launching SAGE: Open‑Source Sovereign AI for Society
Who builds the AI that Teaches our kids? Supports our health? Guides our governments? It must be open source & sovereign, aligned to our flourishing We are building that stack, the first part of which we announce wigh @FIIKSA & 🇸🇦 today, SAGE -...
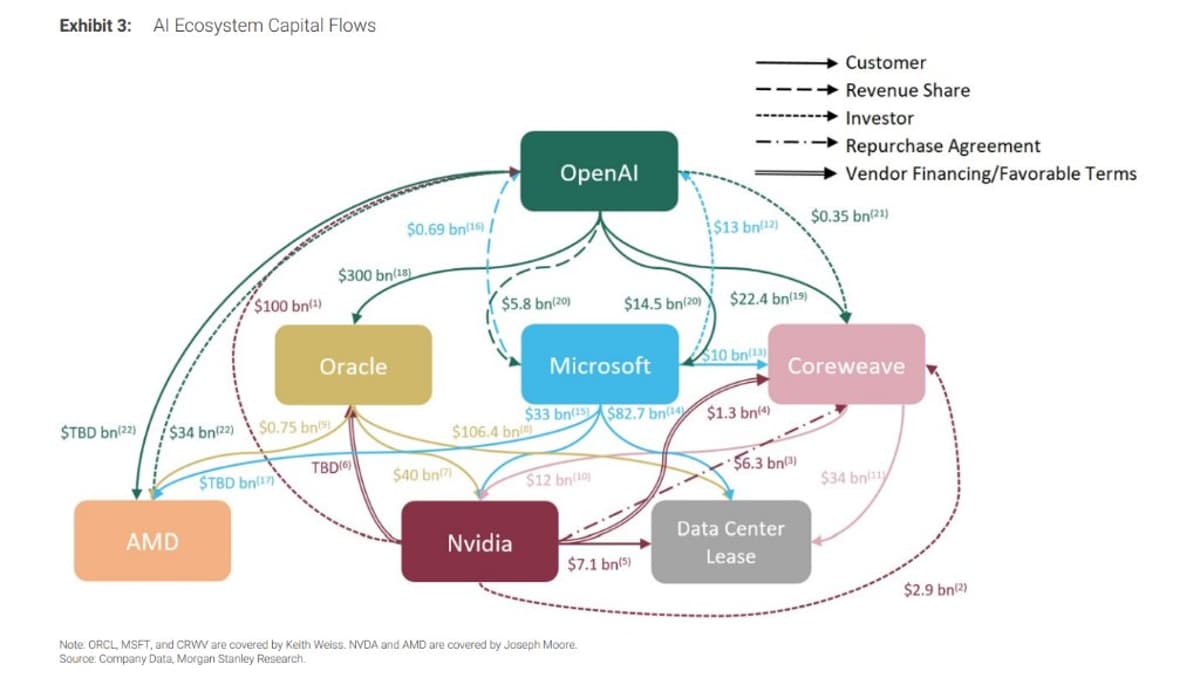
Speculating on U.S. Government Buying 10% of OpenAI
What are the odds that the US government takes a 10% stake on @OpenAI https://t.co/heI3WJLr48