
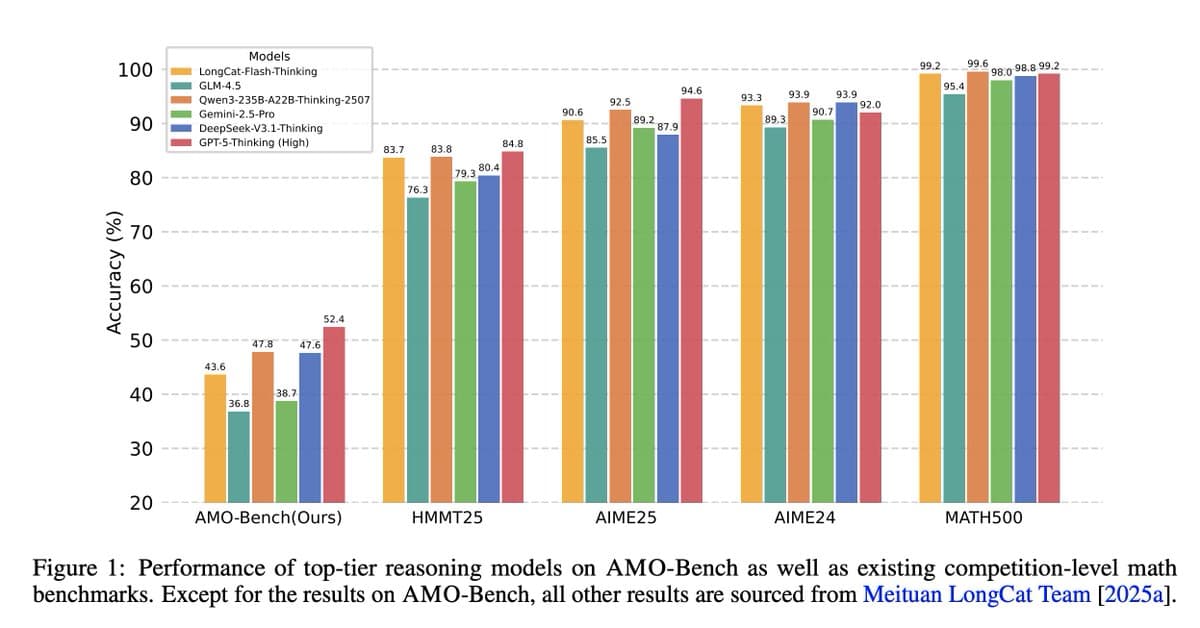
Mid-Tier Language Models only Hit 75‑85% on Basic Math
Language models perform poorly on high-school math? 🙄 You don't want to hear this, but the problems started in grade-school. The moment we (collectively) found acceptable that mid-tier models could score only 75%-85% on a GSM test set of 1.32k straightforward problems... https://t.co/iEVDgo3DVp

Fast Coding Model Feels Overpriced Despite Performance Gains
The speed of a faster coding model is worth it, but it seems mis-priced. C1 gobbles through files, reasons more, expect extra feedback to reach similar place as slower model do with less of everything. Intuitively it feels more expensive "the...

Better, Smaller Datasets Trump Massive Web Crawling
Great idea for a metric to further improve what datasets the models train on. It likely leads to an answer that is not web-scale crawling... Less data is often better, better data takes less.
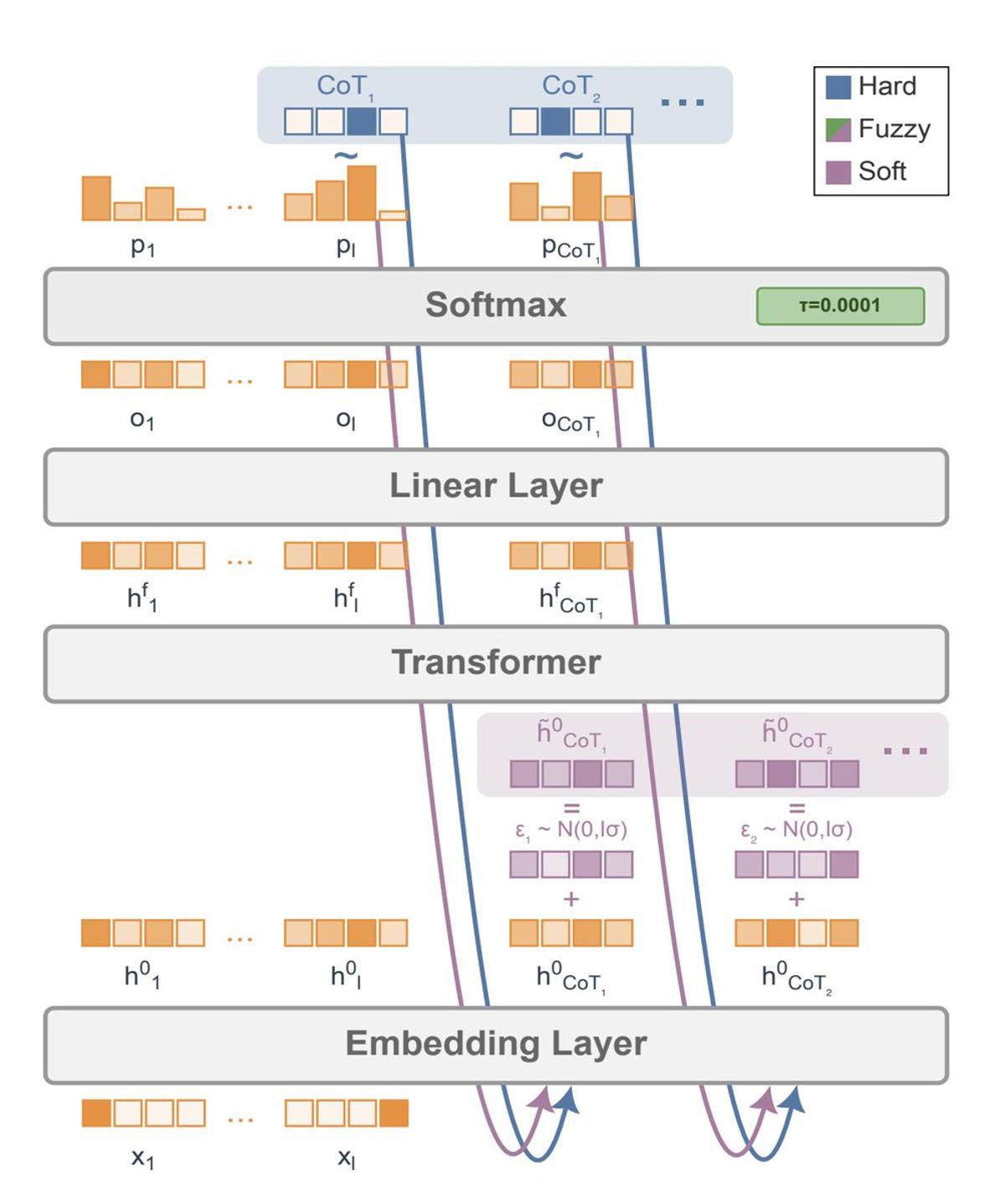
Meta's Soft Tokens Yield Modest Gains on GSM8k
This paper from Meta about "Soft Tokens" in RL is interesting; it allows LLMs to invent their own non-discrete (recursive) representations in order to solve problems better... Results are mixed though: it's only a few percent better on GSM8k from pass@4...

AI Firms Launch Browsers to Dodge Scraping Liability
The reason AI companies are rushing to release browsers: they don't want the responsibility / liability of scraping on their servers. They need to push that to the users! We'll be moving into an ever more gated internet soon...

Only Path to Shippable Code From AI Agents?
Is this the only way to get coding agents to produce shippable quality code? https://t.co/bZvxMN6JEv

More Compute Trumps All Other AI Strategies
Without checking, what is the message behind the "Bitter Lesson", in your opinion? (a) all other things being equal, using more compute is better. (b) more compute is better than all the other things put together.

Internal AI May Replace Risky Open‑Source Contributions
Even though this particular example worked out as you'd expect today, Open Source dynamics will certainly change. Accepting and merging contributions is always a risk and has high cost, so trusting an internal AI system for minor codebase improvements may become...

Avoid the RL Hammer: Choose the Right Tool
If you sub-optimally define any problem to require RL, when most can be solved with different approaches, then of course the RL hammer looks like the right solution! Rather than defending RL thru semantics, better would be to ask: how can...
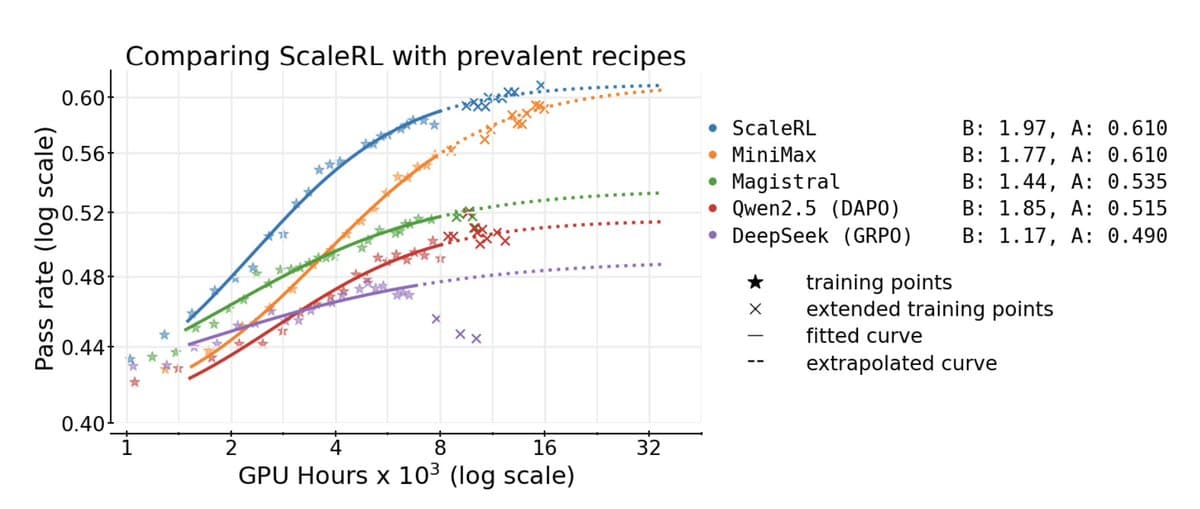
RL Fine‑tuning LLMs Caps at 61% Success Rate
It's hard to overstate how devastating this paper is, not only for reinforcement learning. They spent $4m of compute to find out that RL on LLMs basically taps out at 61% "asymptotic pass rate" (exact rate depends on context), but they...