Hugging Face - Latest News and Information
Technology Pulse
EMAIL DIGESTS
Daily
Every morning
Weekly
Tuesday recap
EMAIL DIGESTS
Daily
Every morning
Weekly
Tuesday recap

NVIDIA’s NeMo Retriever team unveiled an agentic retrieval pipeline that topped the ViDoRe v3 leaderboard and placed second on the reasoning‑heavy BRIGHT benchmark. The system replaces static semantic‑similarity searches with a ReACT‑style loop where an LLM agent iteratively plans, retrieves, and refines queries. Engineering advances, notably an in‑process singleton retriever, slashed latency and GPU overhead, making the approach viable at leaderboard scale. Ablation studies show the pipeline’s robustness across models and embeddings, while highlighting trade‑offs in speed and cost.

Hugging Face Builders is a global community program that puts local leaders at the center of the open-source AI movement 🤗 If you're passionate about open AI and love bringing people together, this is your invitation to lead ✉️ Apply for to build the Paris chapter today ➡️ https://t.co/ONVBZdxRdc

Researchers introduced a concept‑driven workflow that produces synthetic code data aligned with specific programming skills. Using a taxonomy of 91 Python concepts, they generated roughly 15 million Python problems and incorporated 10 billion tokens into the final 100 billion‑token pretraining of Nemotron‑Nano‑v3. The...

🪣 We just shipped Storage Buckets: S3-like mutable storage, cheaper & faster Git falls short for everything on high-throughput side of AI (checkpoints, processed data, agent traces, logs etc) Buckets fixes that: fast writes, overwrites, directory sync 💨 All powered by...

IBM released Granite 4.0 1B Speech, a compact multilingual speech‑language model aimed at resource‑constrained enterprise devices. The 1‑billion‑parameter model halves the size of its predecessor while delivering higher English transcription accuracy and faster inference via speculative decoding. It adds Japanese ASR and keyword‑list...

Ulysses Sequence Parallelism, part of Snowflake AI's Arctic Long Sequence Training protocol, distributes transformer attention across multiple GPUs by sharding both the input sequence and attention heads. The method replaces the quadratic memory bottleneck with two all‑to‑all communications per layer,...

Modular Diffusers launches a composable framework that breaks diffusion pipelines into interchangeable blocks such as text encoding, denoising, and decoding. Developers can assemble, replace, or run individual blocks, enabling lazy loading, memory‑efficient inference, and easy experimentation with models like FLUX.2‑Klein 4B....

Mixture‑of‑Experts (MoE) Transformers replace dense feed‑forward layers with multiple lightweight experts, activating only a few per token to keep inference cost low while preserving the capacity of much larger models. The Hugging Face transformers library introduced a WeightConverter that merges and splits...

NVIDIA’s Cosmos Reason 2B vision‑language model can now be deployed on the Jetson family using the vLLM inference engine. The tutorial walks through installing the NGC CLI, pulling FP8‑quantized weights, and running device‑specific Docker containers for AGX Thor, AGX Orin and Orin Super Nano. After...

The blog shows how Unsloth paired with Hugging Face Jobs lets developers fine‑tune the 1.2 B‑parameter LFM2.5‑Instruct model in half the usual time while using roughly 60 % less VRAM. By invoking a single `hf jobs` command, users can launch a managed GPU job,...

Hugging Face announced that GGML and its llama.cpp project are joining the company. Georgi Gerganov and his team will continue full‑time maintenance, retaining autonomy while receiving HF resources. Integration aims to streamline model deployment via the transformers library and improve...

Hugging Face released a 550‑token CUDA‑kernel agent skill that equips coding agents like Claude and Codex with architecture‑aware optimization knowledge. The skill was used to generate production‑ready RMSNorm, RoPE, GEGLU and AdaLN kernels for a diffusers video pipeline and a...

OpenEnv, an open‑source framework from Meta and Hugging Face, lets AI agents interact with real‑world tools through a standardized gym‑style API. Turing contributed a production‑grade Calendar Gym that mimics authentic calendar systems with access controls, partial visibility, and multi‑step workflows....
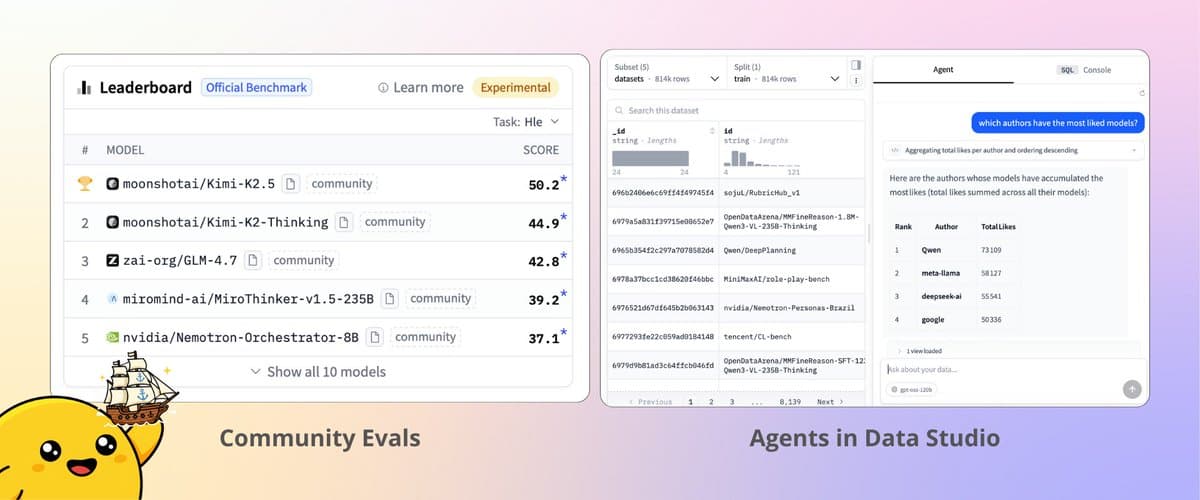
We have been shipping 🛳️❤️ 📦 Community Evals & Benchmark Datasets: Benchmark datasets host benchmark leaderboards, you can now contribute eval results by opening a PR to model repositories, all PRs are fed to benchmark datasets 📦 Chat with datasets: agents...

SyGra 2.0.0 launches Studio, a visual IDE for building synthetic data generation workflows. The canvas lets users configure models, data sources, and prompts via drag‑and‑drop, automatically generating the underlying YAML/JSON graph. Studio provides live execution monitoring, token‑cost tracking, and inline...
